








文末附源码地址
实验内容
- 单词及其英文解释的录入、修改和删除
- 录入新单词,把它插入到相应的位置(按词典顺序),其后跟英文解释、同义词、反义词;(此功能要求在文件中完成,其它功能可以将单词放在数据段中)
- 可修改单词英文解释;
- 删除单词及其英文解释;
- 查找
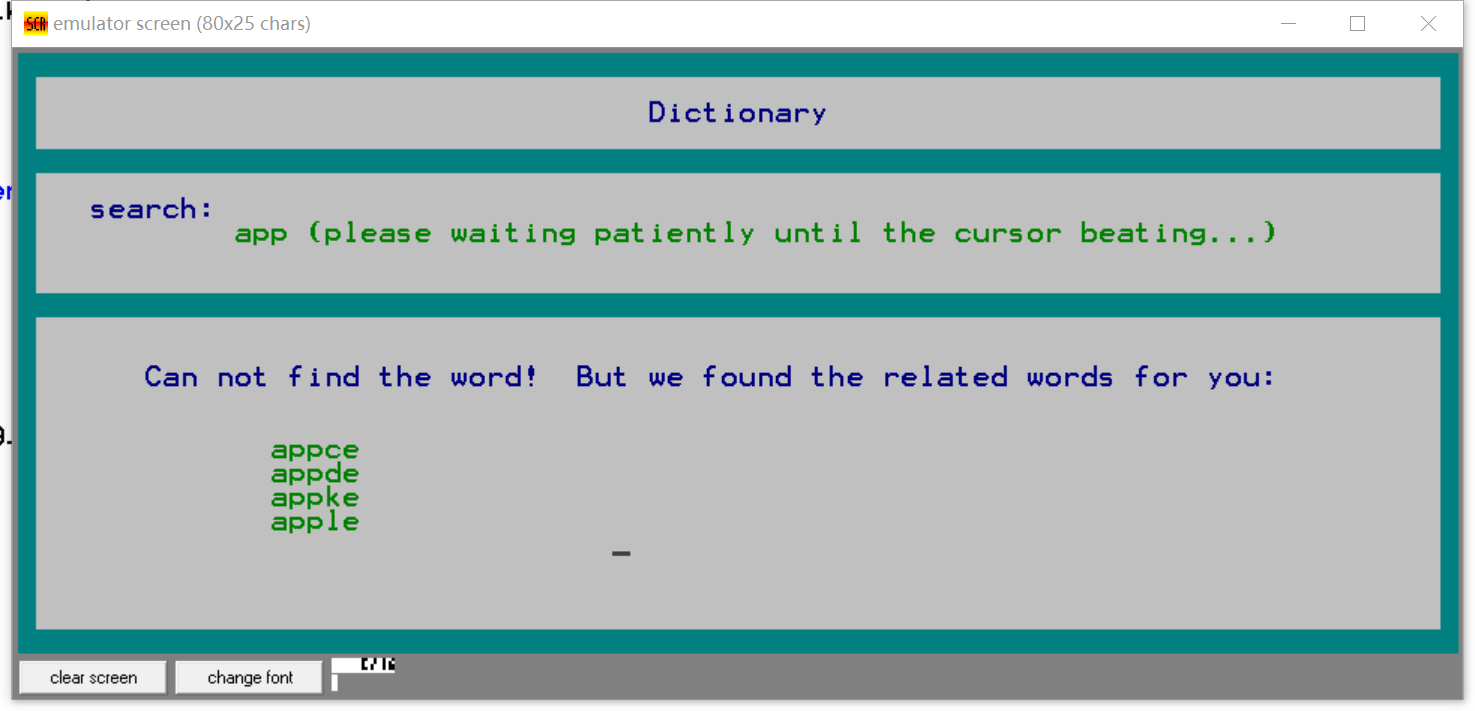
- 输入不完整的字符串,会依顺序列出单词前缀和字符串相匹配的单词;
- 如输入:en则列出:enable, enabled, enact等
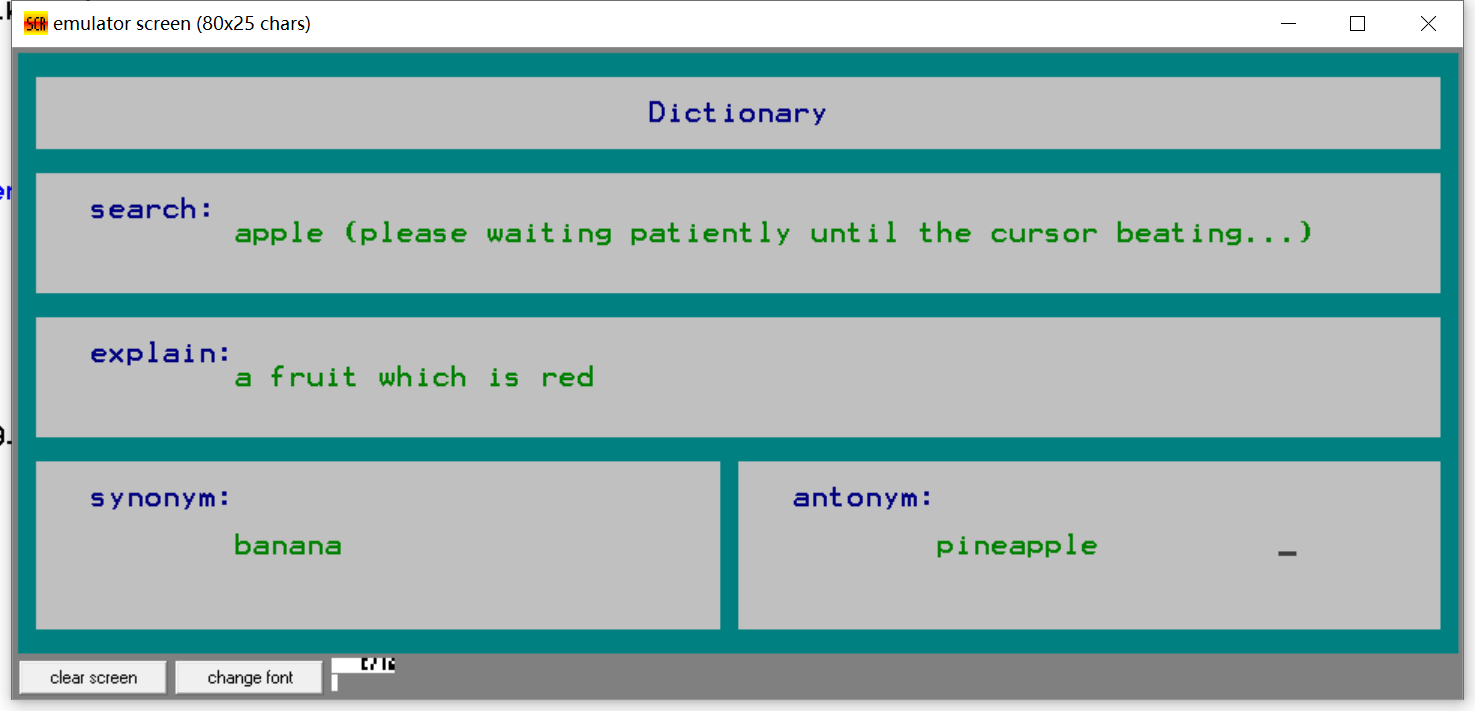
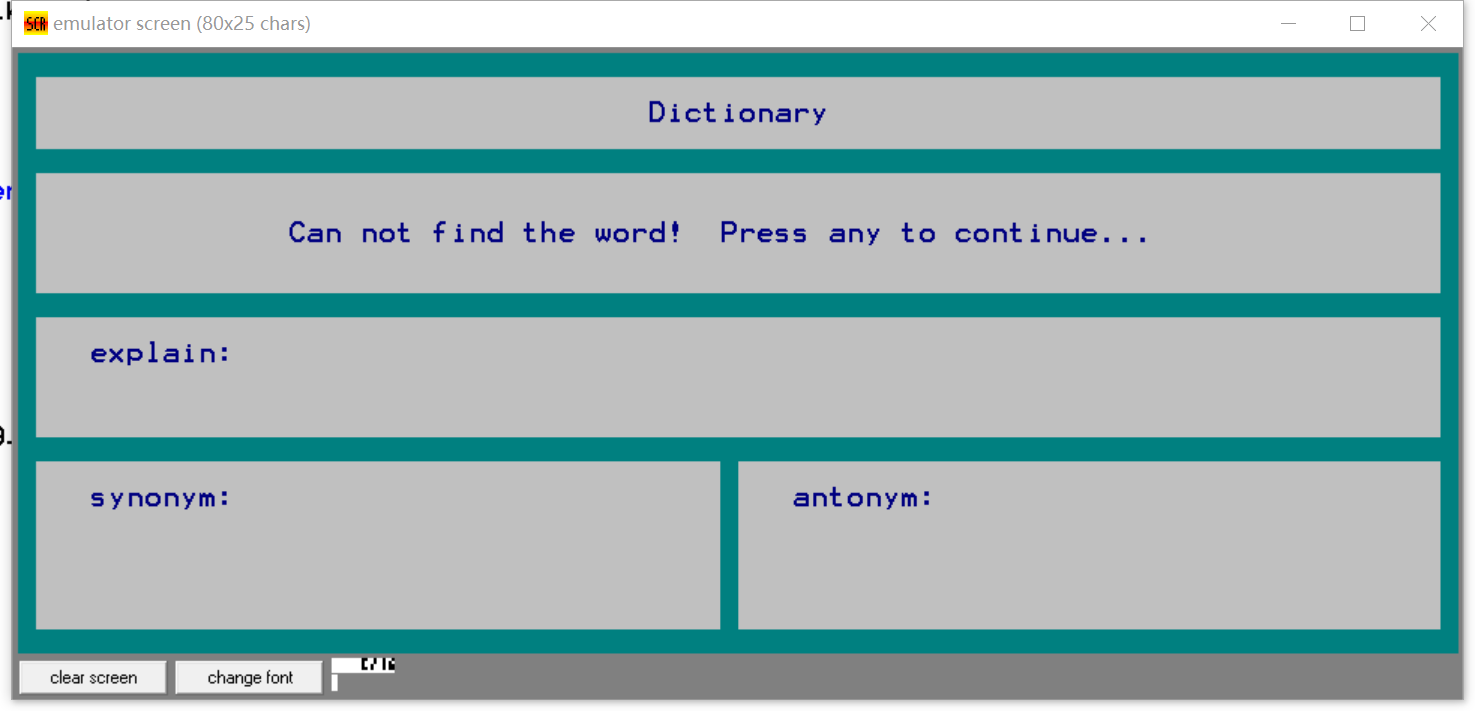
- 查询某个单词英文解释(如enable: to provide with the means or opportunity; to make possible, practical, or easy),词库中不存在此单词,则提示找不到;
- 查询某个单词的同义词(如accept: approve);
- 查询某个单词的反义词(如win: lose);
- 输入不完整的字符串,会依顺序列出单词前缀和字符串相匹配的单词;
- 以上结果均需显示
开发环境
windows10(x64), emu8086
注意事项
-
请在光标跳动时进行输入,否则输入的信息会读入到缓冲区中,而在缓冲区的数据在进行后续操作时可能会被自动使用,导致预期之外的情况发生
-
如果不小心输入到缓冲区则可以点击清空缓冲区的数据

-
在输入前请确保切换至英文输入法,中文输入会导致数据出错,写入文件中可能出现乱码等问题
-
在进行搜索单词,插入单词,修改单词和删除单词等功能时需要进行单词的查找,这需要一段比较长的时间,请耐心等待,不要进行其他操作,等待光标再次跳动进行输入或者屏幕出现提示信息再进行后续操作。
-
代码中默认导入d:\words.txt的数据,请提前在对应目录创建好文件
- 此处的d是虚拟磁盘中的d盘,注意好位置

- 或者将代码主程序import部分中的注释块取消注释。

- 此处的d是虚拟磁盘中的d盘,注意好位置
功能展示
- 单词导入


- 单词的查找
- 精确查找
- 模糊查找
- 查找不存在且不是某个单词前缀的单词
- 精确查找
- 单词的插入
- 插入已存在单词
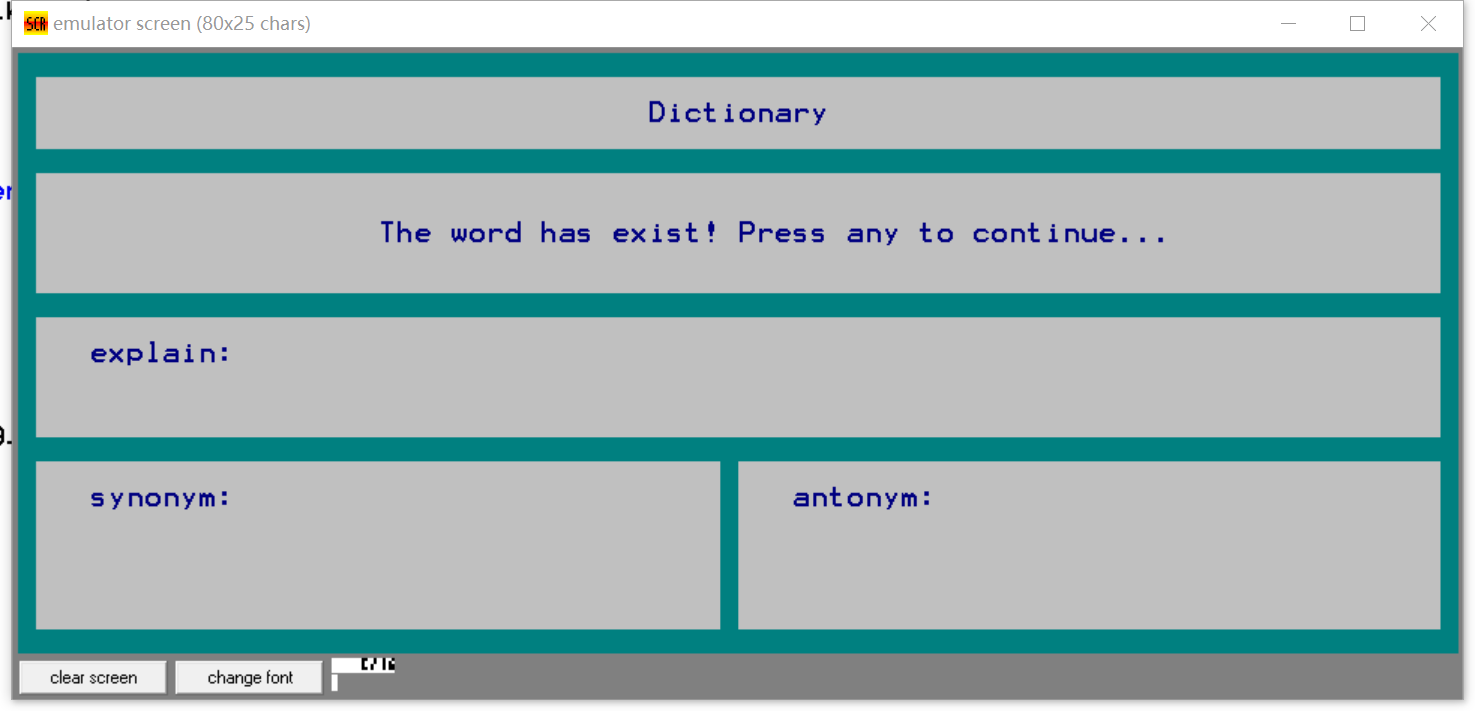
- 插入未存在单词
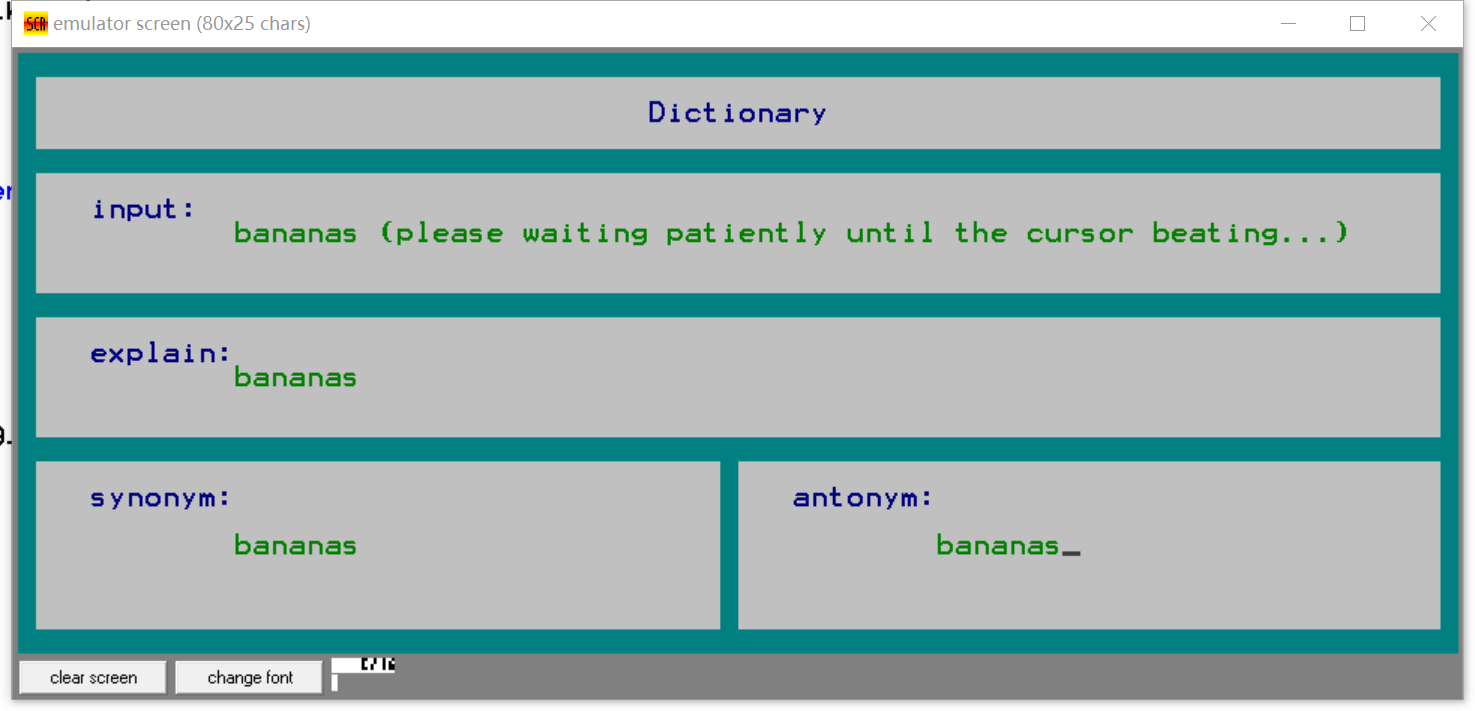
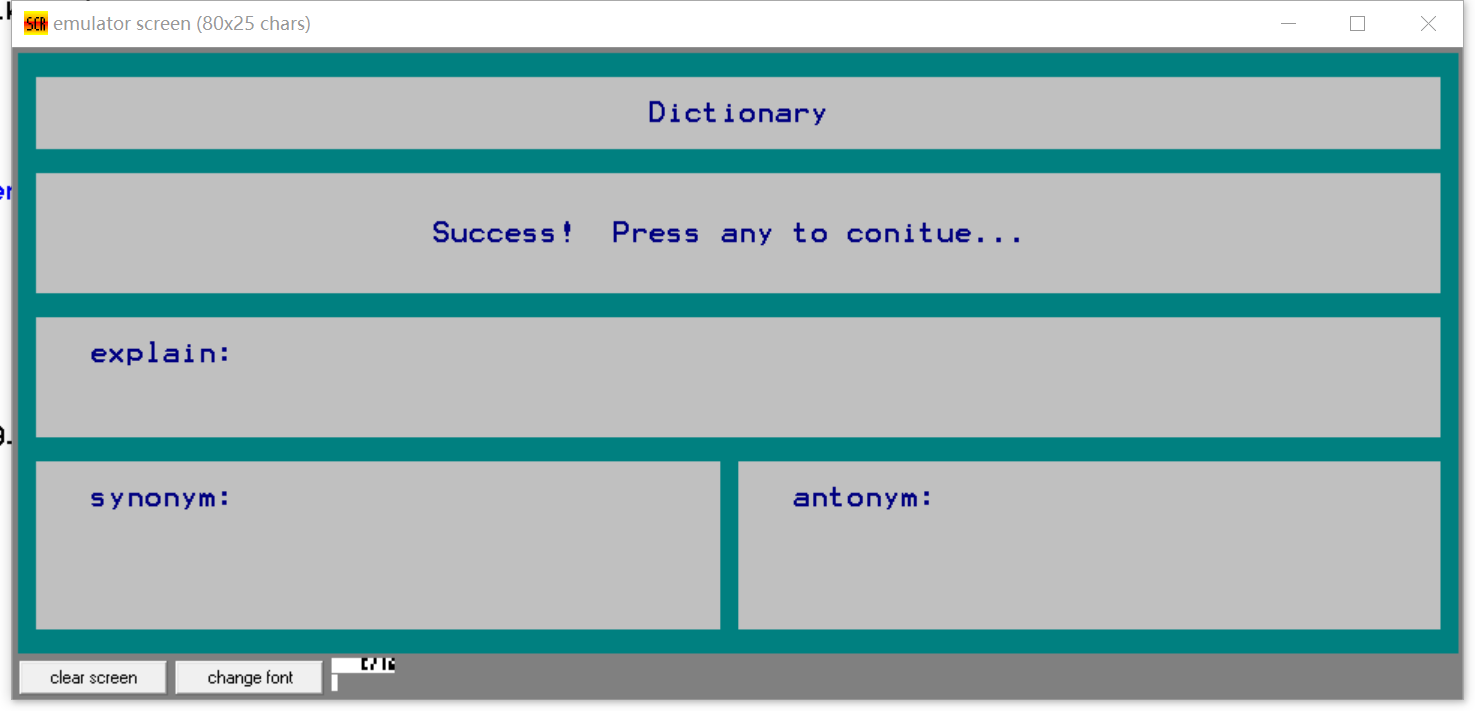
- 插入已存在单词
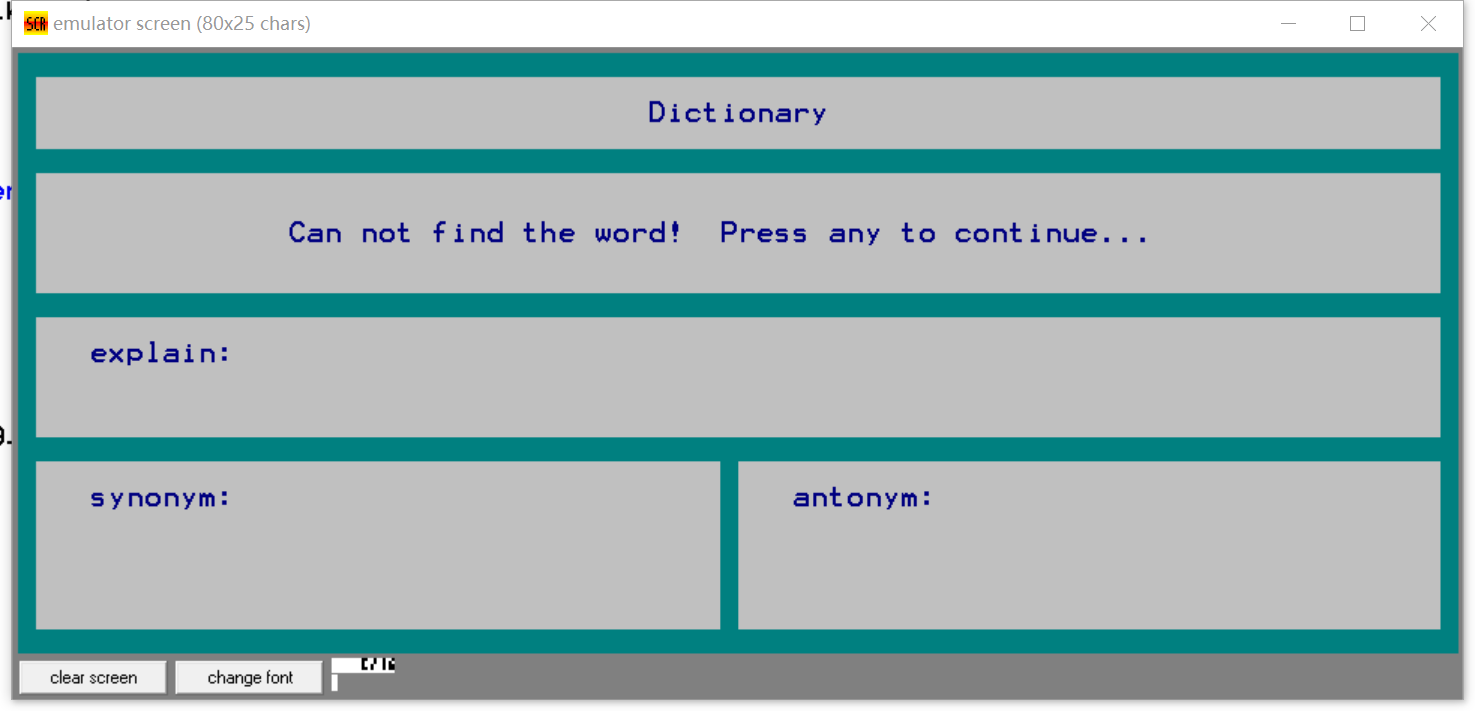
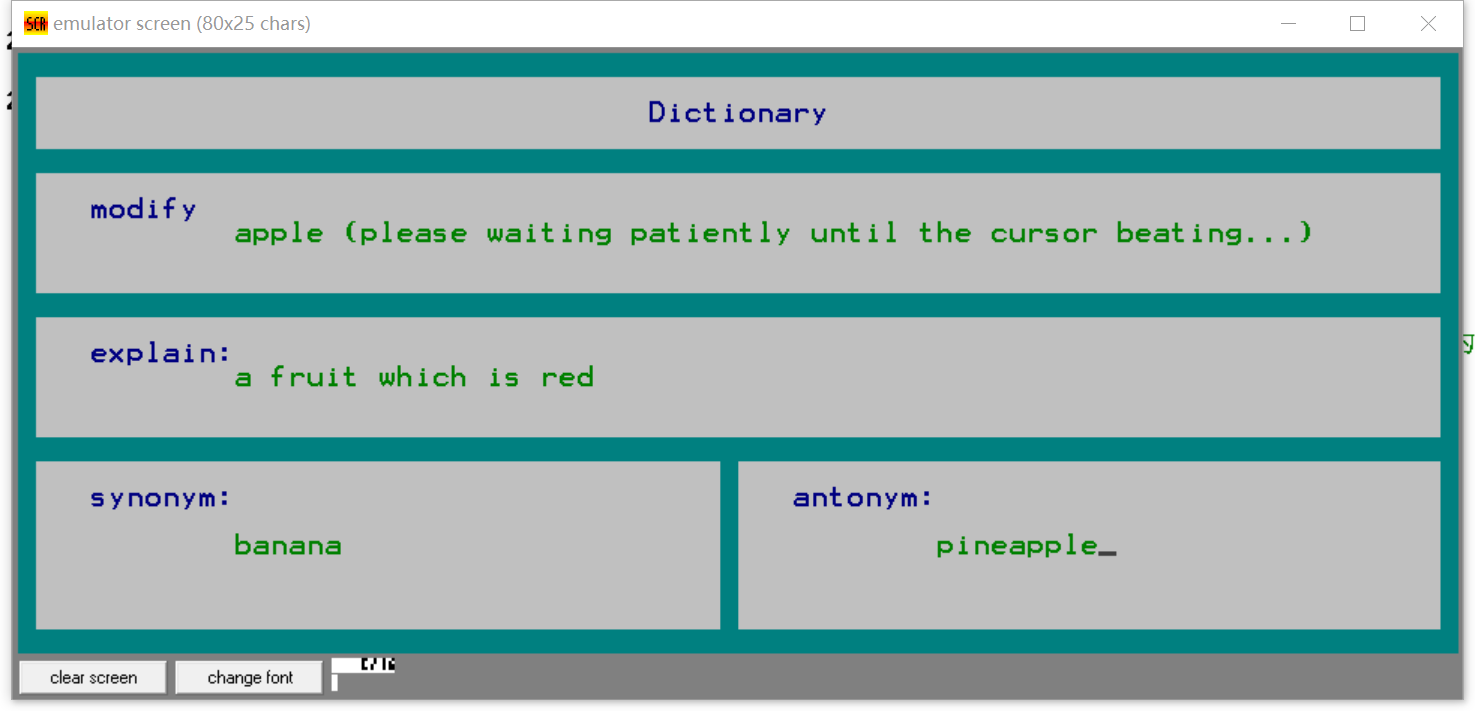
- 单词的修改
- 修改不存在的单词
- 修改存在的单词
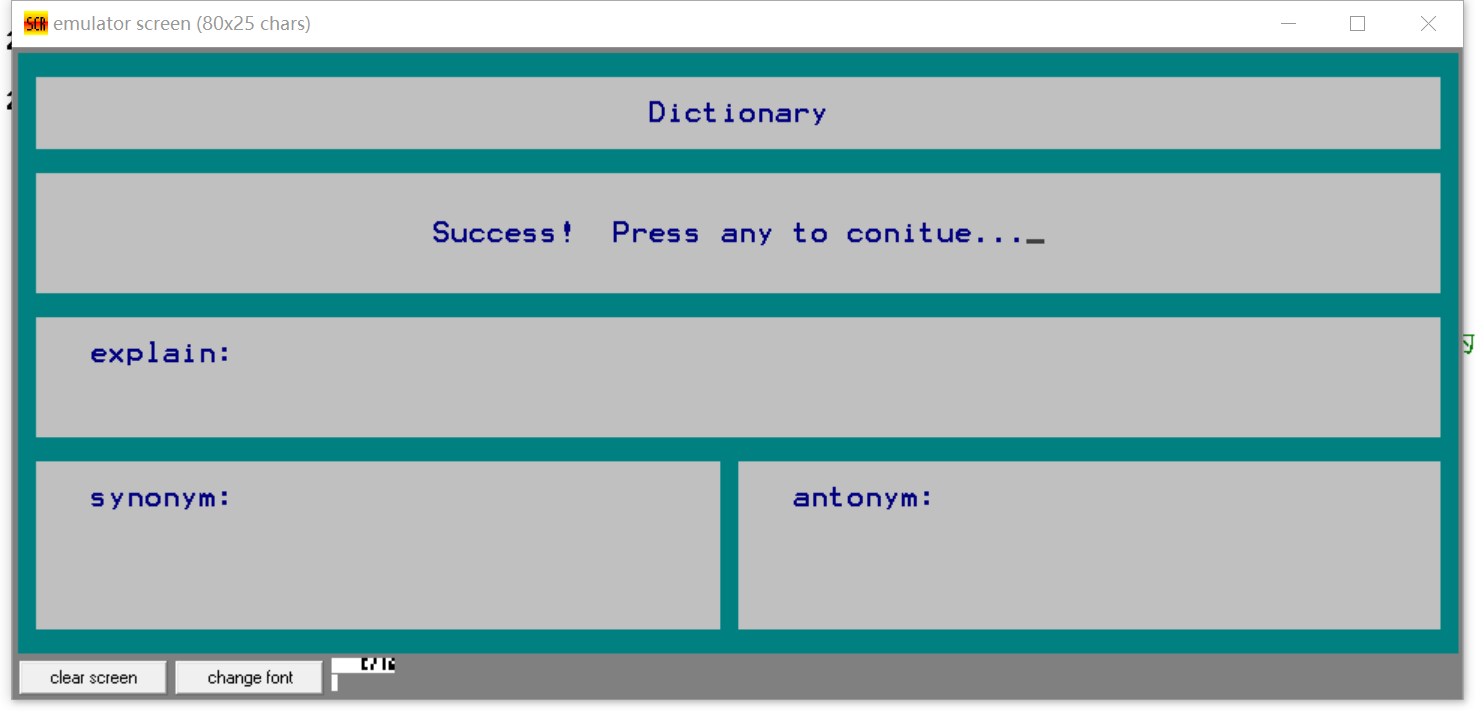
- 修改不存在的单词
- 单词的删除
- 删除不存在的单词
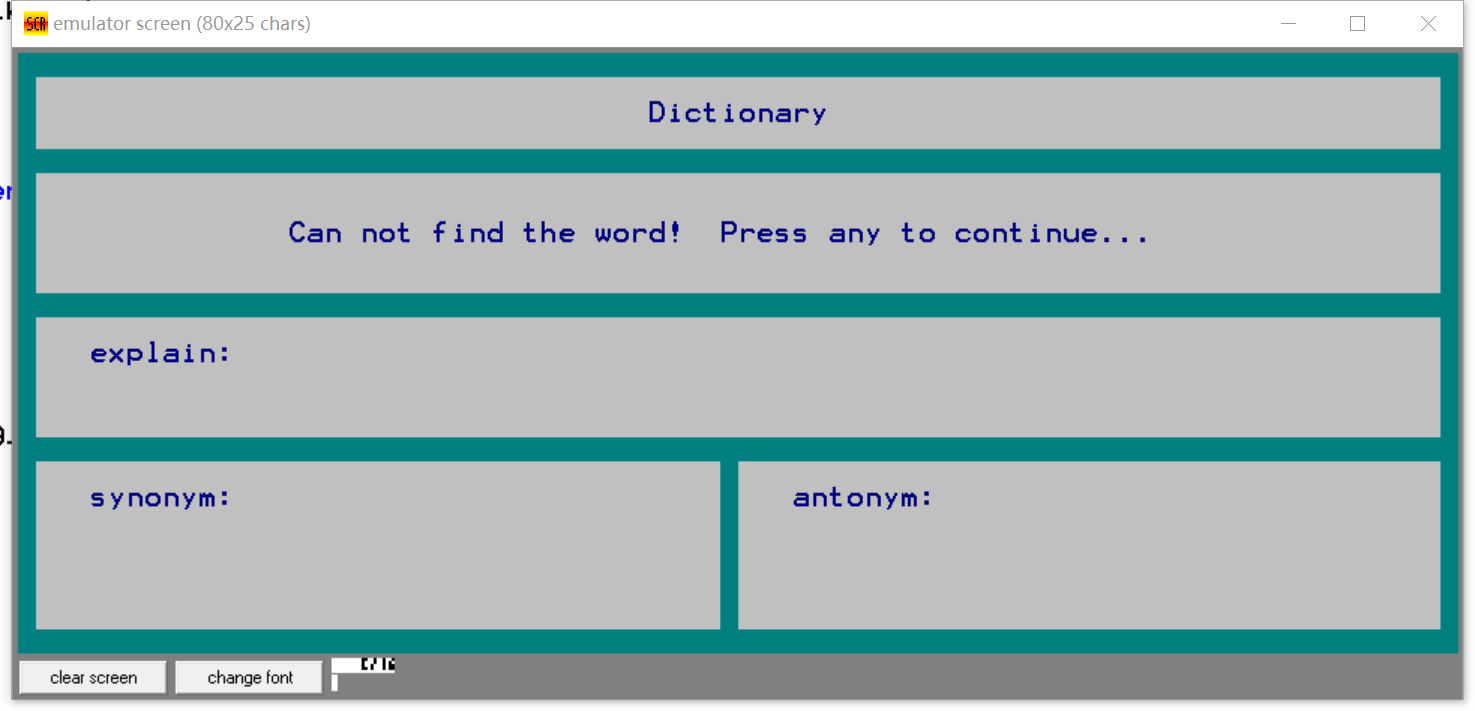
- 删除存在的单词
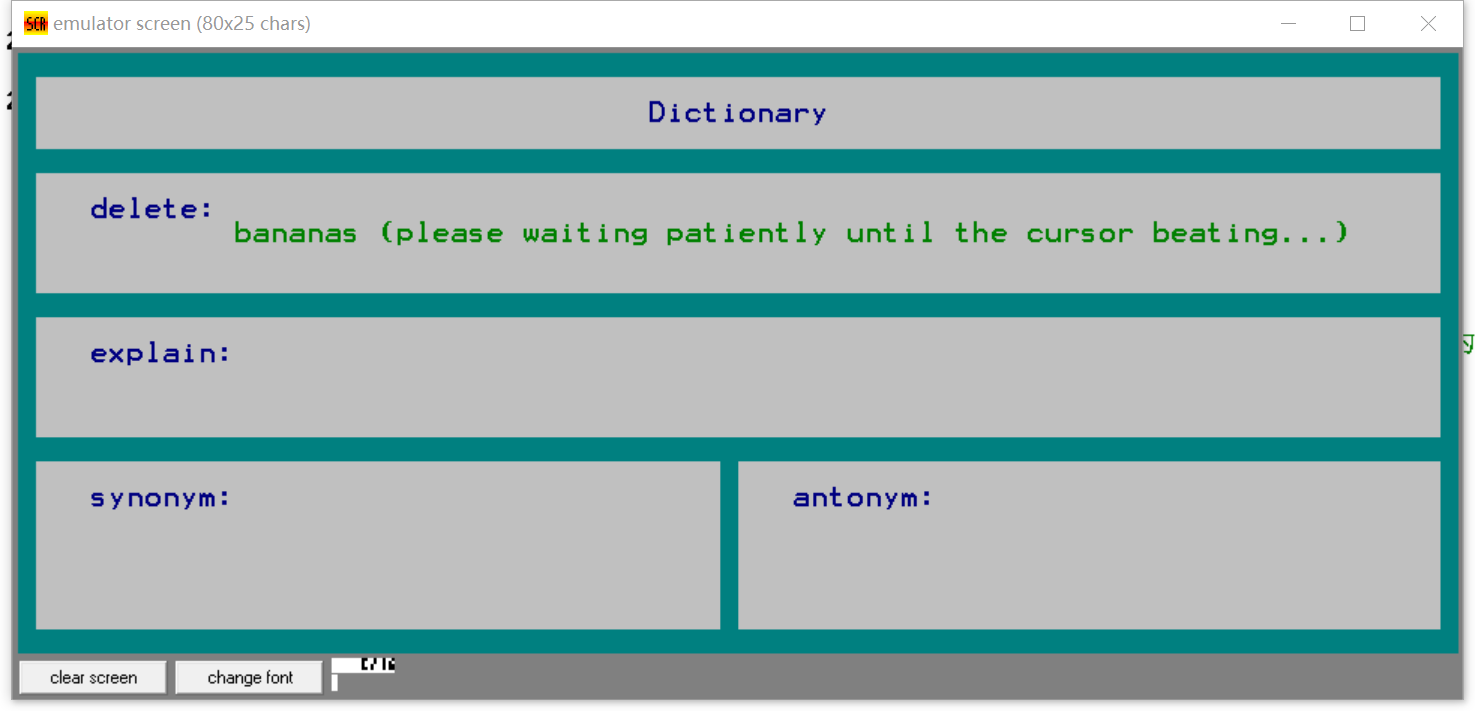
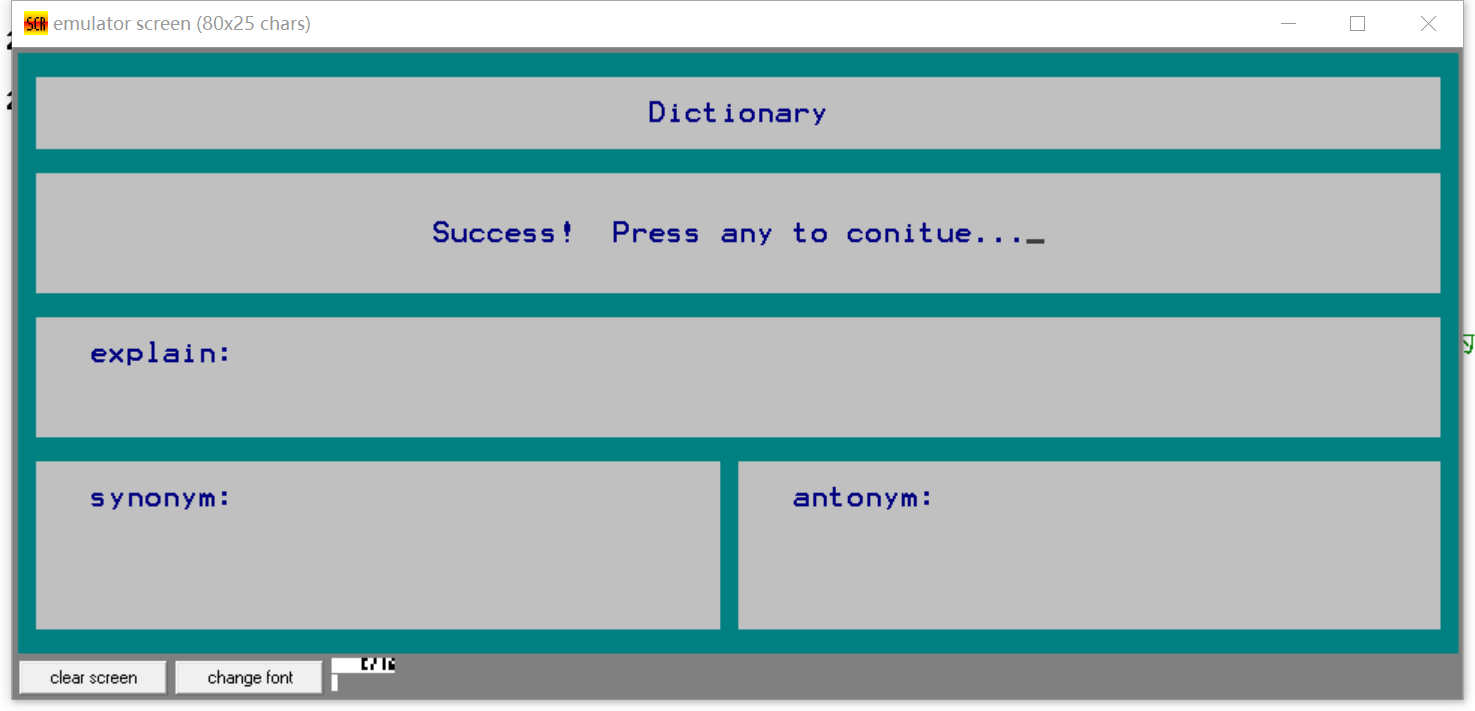
- 删除不存在的单词
- 单词导出
功能实现
进入界面之前首先从文件导入单词到words数组中,根据读取的字节数确定存储的单词数量(记录在cnt中)
数据段中words模拟二维数组(
words[64][100])实现单词的存储,开辟了6400字节的大小(默认为64个单词,可自定义调节),其中每个单词划分为1-20位存放单词,21-60存放解释,61-80存放同义词,81-100存放反义词,可以根据需求自行划分每一个部分的大小。首先是考虑采用符号分隔存储,但是在文件中显示效果较差,所以改为每种信息规范多少位进行存储,没有占满则用空格占位,当然这样的方式要求输入的字符不能超过规定的限制,考虑到页面显示情况本身就不适合输入太多字符,所以采用此种方式。
随后初始化界面,进行功能的选择
通过在键盘上键入0-4选择功能(采用的是int16h的0号功能,不需要输入回车键),如果输入其他字符则会提示错误并要求重新输入
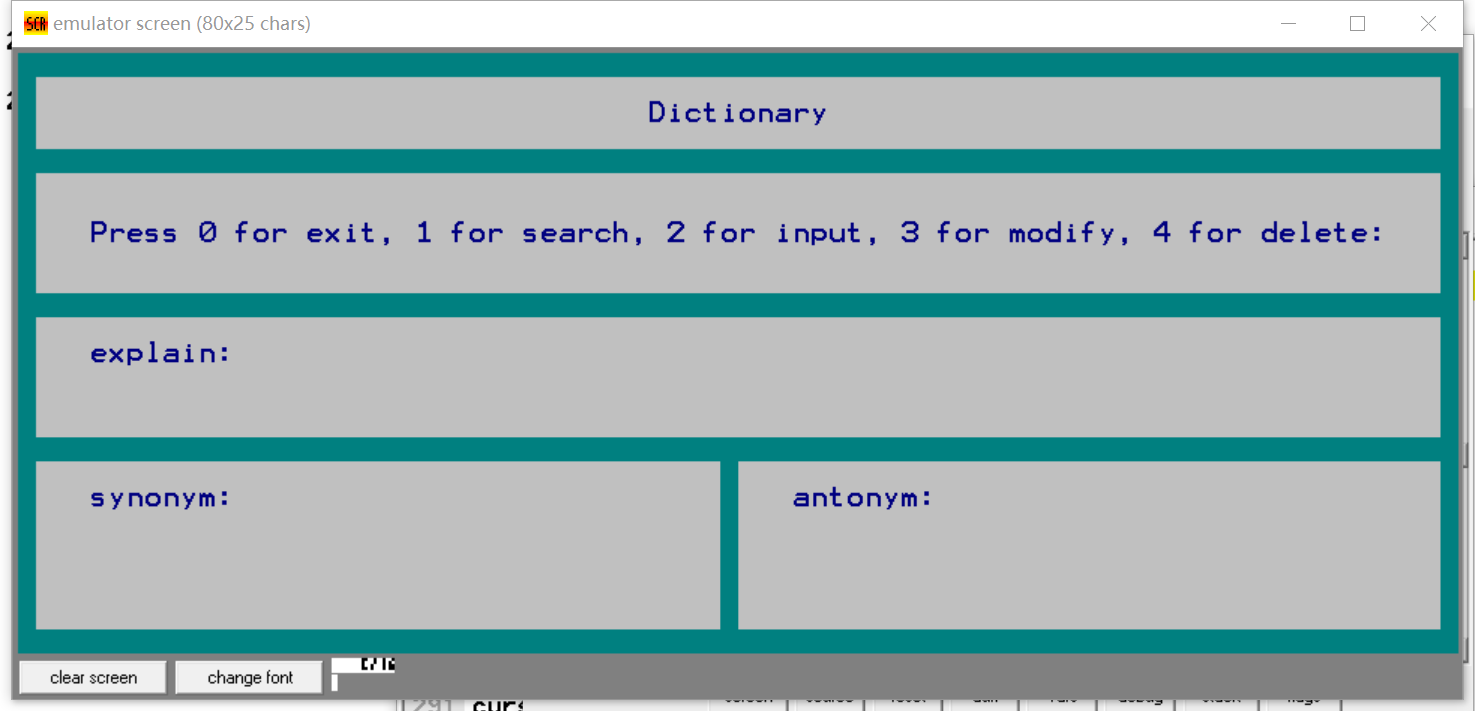
之后则可以进行对应的操作,如果选择的是0,则将words数组中的数据写入文件后退出程序。
- 搜索功能实现了精确查找和模糊查询,在输入单词之后,查找是否存在精确匹配的单词,如果存在则输出对应的解释以及同义词、反义词。如果无精准匹配则搜索是否存在以其为前缀的单词(即模糊查询),之后将所有模糊匹配的结果输出
- 查找某个单词使用两重循环,外层遍历所有单词,内层遍历单词中的每个字母进行实现
- 插入功能通过字典序找到该单词应该插入的位置,之后将其后续位置相继都后移100位,挪出位置给新单词存放
- 修改功能首先找到单词位置,之后使用读入的新数据覆盖原本的数据
- 删除功能通过找到单词所在位置,将后续单词全部前移100位
具体实现可查看代码中的注释。
代码已在gitee和github上开源
- 个人网站:https://www.ken-chy129.cn/
- gitee:https://gitee.com/Ken-Chy129/dict
- github:https://github.com/Ken-Chy129/emu8086-dictionary



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











