







银行卡号识别
项目目标
在该项目中找到两张银行卡如下:


在该项目中,使用图像处理的基本知识,来识别出银行卡上的卡号。不同于现在使用的机器学习或者深度学习的方法来实现。
实现的效果如下:


实现原理
在该项目中,使用图像处理的基本操作,如阈值操作,滤波操作,轮廓寻找,图像分割,模板匹配等知识实现银行卡号的准确识别。整个过程主要分为两大块,一是对于模板的选取,在两张银行卡号中选取一组0-9的模板,用于后期匹配的模板。二是对输入银行卡图片的处理,分割得到每个卡号数字的方块,然后与实现选取的模板匹配,得到银行卡的卡号。
模板处理
对于模板的的处理,首先我们要明确,处理成什么样的模板才是我们需要的。如何判断是否是我们需要?最大可能的方便后面我们进行匹配操作。在该项目中,我们需要将十个模板和对应的数字一一对应起来,这样在后面匹配过程中,方便我们知道最佳匹配的数字。因此我在这里使用字典的形式来对模板信息进行存储。{0:template0,1:template1,...,9:template9}
选取模板的图片如下:

在该图片中通过查找轮廓,然后绘制轮廓外界矩形的方式,将每一和数字分割出来,并和对应的数字相对应。
每一个模板都是这样的array([[ 0, 0, 0, 0, 0, 0, 0, 255, 255, 255, 255, 255, 255], [ 0, 0, 0, 0, 0, 0, 0, 0, 255, 255, 255, 255, 255], [ 0, 0, 0, 0, 0, 0, 0, 0, 255, 255, 255, 255, 255], [255, 255, 255, 255, 0, 0, 0, 0, 255, 255, 255, 255, 255], [255, 255, 255, 255, 255, 0, 0, 0, 255, 255, 255, 255, 255], [255, 255, 255, 255, 255, 0, 0, 0, 255, 255, 255, 255, 255], [255, 255, 255, 255, 255, 0, 0, 0, 255, 255, 255, 255, 255], [255, 255, 255, 255, 255, 0, 0, 0, 255, 255, 255, 255, 255], [255, 255, 255, 255, 255, 0, 0, 0, 255, 255, 255, 255, 255], [255, 255, 255, 255, 255, 0, 0, 0, 255, 255, 255, 255, 255], [255, 255, 255, 255, 255, 0, 0, 0, 255, 255, 255, 255, 255], [255, 255, 255, 255, 255, 0, 0, 0, 255, 255, 255, 255, 255], [255, 255, 255, 255, 255, 0, 0, 0, 255, 255, 0, 0, 0], [255, 255, 255, 255, 255, 0, 0, 0, 255, 255, 0, 0, 0], [255, 255, 255, 255, 255, 0, 0, 0, 255, 255, 0, 0, 0], [255, 255, 255, 255, 255, 0, 0, 0, 255, 255, 0, 0, 0], [255, 255, 255, 255, 255, 0, 0, 0, 255, 255, 0, 0, 0], [255, 255, 255, 255, 255, 0, 0, 0, 255, 255, 0, 0, 0], [255, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [255, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 255, 255]], dtype=uint8)的形式存储。
输入图片处理
对于输入图片来说处理起来比模板图片困难多,一是整个照片的干扰信息很多,很难直接就定位到卡号位置,需要经过一系列的变换。二是,定位到卡号位置后,如何将每个卡号给提取出来,进行模板匹配,识别其数字。
- 首先,对于输入的图片为RGB格式,需要转换成GRAY格式,然后再将灰度形式的图片进行二值化处理。
- 对于二值化处理之后的图片进行Sobel滤波,将数字模糊,连接起来。
- 经过Sobel之后可能数字没有连接在一起,所以执行闭操作将相邻的数字连接起来,因为数字是横向的,所以闭操作的核设置为
[1,1,1,1,1,1,1,1,1]。 - 通过查找轮廓和轮廓外接矩形的方式定位到连续数字区域。
- 最后,通过连续数字区域分割出每一个数字,然后将每个数字和模板进行匹配,匹配结果最高的就是最有可能的数字。
源码分析
利用python-opencv和numpy两个包,对输入的图片进行各种操作。最终实现卡号的识别。
源码分析
源码的主要分为两部分,一是对于模板的处理生成模板的字典,二是对输入图片的处理,得到银行卡上的卡号。
模板处理源码
img = cv2.imread('template.png')#读入模板图片
img_gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)#将模板图片转换为灰度图格式
ret,img_b = cv2.threshold(img_gray,127,255,cv2.THRESH_BINARY_INV)#将模板图片进行二值化处理
contours,h = cv2.findContours(img_b,cv2.RETR_EXTERNAL,cv2.CHAIN_APPROX_NONE)#查找图片中所有数字的轮廓
draw_image = img.copy()
#以下实现对轮廓的排序
temp = contours.copy()
temp[0] = contours[0]
for i in range(1,10):
temp[i] = contours[10-i]
contours = temp
res = cv2.drawContours(draw_image,contours,6,(0,0,255),1)
#定义存储模板的字典
digits={}
for i,con in enumerate(contours):
x,y,w,h = cv2.boundingRect(con)
draw_image = cv2.rectangle(draw_image,(x,y),(x+w,y+h),(0,255,0),2)
digits[i] = img_gray[y:y+h,x:x+w]
print(digits)
代码中最后的for循环,用于遍历所有的轮廓,在循环内部,使用boundingRect函数找到轮廓的外接矩形,外接矩形的区域就是模板数字的区域,截取出来存储到字典中即可。
输入图片处理源码
输入图片处理源码大致可以分为以下部分:
- 对于读入卡片的初步处理操作
- 从卡片中截取出连续的数字区域
- 从每一个连续数字区域中将每一个数字截取出来,这一部分和模板的操作大致相同
- 将截取出来的单个数字部分分别与十个模板相匹配,对比十个匹配结果,选取最佳的匹配作为该数字的匹配结果。
对读入图片的初步处理操作
img = cv2.imread('card1.png')#读入对应的银行卡片
acount = []
img_gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)#转换成灰度图
ret,img_b = cv2.threshold(img_gray,0,255,cv2.THRESH_BINARY|cv2.THRESH_OTSU)#自动选择相应的阈值对图片进行二值化操作
#求图片的Sobel梯度
gradx = cv2.Sobel(img_b,cv2.CV_64F,1,0,-1)
gradx = np.absolute(gradx)
minv,maxv = int(np.min(gradx)),int(np.max(gradx))
gradx = (255*((gradx-minv)/(maxv-minv)))
grady = cv2.Sobel(img_b,cv2.CV_64F,0,1,-1)
grady = np.absolute(grady)
minv,maxv = int(np.min(grady)),int(np.max(grady))
grady = (255*((grady-minv)/(maxv-minv)))
grad = cv2.addWeighted(gradx,0.5,grady,0.5,0)
#形态学操作,对图片进行闭操作,就是先膨胀,后腐蚀
kernel = np.ones((7,7),np.uint8)
img_close = cv2.morphologyEx(grad,cv2.MORPH_CLOSE,kernel)
kernel = np.ones((1,11),np.uint8)
img_close = cv2.morphologyEx(grad,cv2.MORPH_CLOSE,kernel)
img_close = cv2.morphologyEx(grad,cv2.MORPH_CLOSE,kernel)
ret,img_close = cv2.threshold(img_close,127,255,cv2.THRESH_BINARY)
这段代码中,比较重要的是对图片做闭操作,闭操作就是先膨胀,后腐蚀。前面对图片进行处理,数字为白色,背景为黑色。这里先膨胀,将数字之间的黑色缝隙覆盖,然后执行腐蚀操作,类似于膨胀的逆操作,但已经被覆盖连接的黑色区域没法还原。在闭操作中,比较重要的是他执行操作的核,这里数字为水平连续,所以选择(1,11)的核。对于不同的场景可以根据需要选择不同的核。
执行完毕上面的操作后的图像:

上图为原始图像的灰度图和处理后的图像的对比图。
从卡片中截取出连续的数字区域
代码思想,通过上面处理好的图片找到白色区域的轮廓,然后找到轮廓的外接矩形,通过外接矩形的长宽比,过滤掉不合适的区域,得到连续的数字区域。然后根据得到区域的x坐标对得到的数字区域进行从左到右排序。
contours,h = cv2.findContours(img_close,cv2.RETR_TREE,cv2.CHAIN_APPROX_NONE)#找到所有的轮廓
draw_img = img.copy()
images = []
x_position = []
for contour in contours:
x,y,w,h = cv2.boundingRect(contour)#轮廓的外接矩形
p = float(w)/h
if p >= 3.1 and p <= 3.4 and w > 50:#通过外接矩形的长宽比来筛选合适的区域
x_position.append(x)
images.append(img[y-10:y+h+10,x-10:x+w+10])
res = cv2.rectangle(draw_img,(x,y),(x+w,y+h),(0,255,0),1)
# 对找到的区域进行从左到右排序
p = np.argsort(x_position)
x_position = np.asarray(x_position)[p]
temp = []
for i in p:
temp.append(images[i])
images = temp
处理以后的效果图:

从每一个连续数字区域中将每一个数字截取出来,这一部分和模板的操作大致相同
这段代码的思想是,从上面的截取的小连续区域中,将每个数字分离出来,操作过程和对模板的选取是一样的。这里,我将模板匹配和数字区域提取放在了一起。大致流程如下,遍历每个连续数字区域,在每个区域中将数字区域截取出来,然后对于该区域截取出来的数字区域进行模板匹配,得到数字区域的值。
for image in images:
part_img_gray = cv2.cvtColor(image,cv2.COLOR_BGR2GRAY)
ret,part_img_b = cv2.threshold(part_img_gray,100,255,cv2.THRESH_BINARY_INV)
contours,h = cv2.findContours(part_img_b,cv2.RETR_TREE,cv2.CHAIN_APPROX_NONE)
image_bkg = image.copy()
temps = []
x_p = []
for contour in contours:
x,y,w,h = cv2.boundingRect(contour)
p = float(h)/w
if p >= 1.0 and p < 2.0 and h > 10:
res = cv2.rectangle(image_bkg,(x,y),(x+w,y+h),(0,255,0),1)
temps.append(image[y-3:y+h+3,x-3:x+w+3])
x_p.append(x)
#以上代码为从数字连续区域中将每个数字区域截取出来
#下面这几行,将截取出来的数字区域进行排序
p = np.argsort(x_p)
temp_temp = []
for i in p:
temp_temp.append(temps[i])
temps = temp_temp
#以下代码是将数字连续区域截取出来的数字区域和模板做匹配得到数字区域的值。
for temp in temps:
img_gray = cv2.cvtColor(temp,cv2.COLOR_BGR2GRAY)
ret,img_b = cv2.threshold(img_gray,100,255,cv2.THRESH_BINARY_INV)
contour,h = cv2.findContours(img_b,cv2.RETR_TREE,cv2.CHAIN_APPROX_SIMPLE)
x,y,w,h = cv2.boundingRect(contour[1])
source_img = img_b[y:y+h,x:x+w]
values = []
for i in range(10):# 每个数字区域和十个模板相匹配,得到最佳匹配结果
digits[i] = cv2.resize(digits[i],(source_img.shape[1],source_img.shape[0]))
res = cv2.matchTemplate(source_img,digits[i],cv2.TM_CCOEFF_NORMED)
minv,maxv,minl,maxl = cv2.minMaxLoc(res)
values.append(maxv)
s = np.hstack((digits[i],source_img))
acount.append(np.argmax(values))
上面提到最佳匹配结果,以模板匹配中的正态相关系数来举例,每一次匹配都会得到一个数值,将十次匹配结果对比,选取匹配结果最大的就是最佳匹配结果。
下面来看匹配的过程:
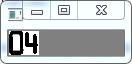
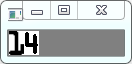

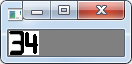



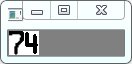


下面来看一下,匹配结果的值:

不难看出与模板4的匹配值最大,所以该数字区域就是数字4。同理应用于别的数字区域。
结果分析
对每一个数字区域都进行匹配操作,记录匹配值最大的。最后即可得到完整的银行卡号。
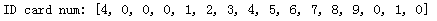
接下来将结果绘制到卡片的对应位置即可:
for i,value in enumerate(acount):
cv2.putText(img,str(value),(x_position[int(i/4)]+(i%4)*10,140),1,1,(0,0,255),2)
最后的图片为:

总结
在这个项目中,没有使用机器学习和深度学习的知识,主要使用一些图像处理的基本操作。例如:梯度、形态学、模板匹配、阈值等操作。在做项目过程中,选择合适的方式来使用这些操作为项目服务。通过项目实战对各种操作有更深的理解,使用起来更加得心应手,这才是我们做项目的最终目的。















 9743
9743











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









