







1、关于fp16定义
CUDA 7.5 新特性介绍 -- FP16(即fp16是cuda7.5引入的,需要计算能力达到5.3或以上)
16-bit Floating Point (半精度浮点)
从 Tegra X1 开始,NVIDIA 的 GPU 将支持原生的 FP16 计算指令,理论上可以获得两倍于 FP32 (单精度浮点)的性能,适用于大规模的神经网络或者计算机视觉相关的应用。而从 CUDA 7.5 开始,开发者可以很容易的将原有的 FP32 的代码移植为 FP16:直接使用内置的half以及half2类型。
CUDA 7.5 主要提供以下三种 FP16 相关的功能:
新的 cuda_fp16.h 头文件定义了 half 和 half2 类型,并为 FP32 和 FP16 之间的类型转换提供了half2float() 与float2half() 两个函数。
新的 ”cublasSgemmEx()“ 接口实现了混合精度的矩阵乘法(在输入 FP16 的情况下以 32 位的精度进行计算)以此在保证精度的前提下处理两倍于原有规模的矩阵运算。
对于现有的 Tegra X1 设备以及未来的 GPU 型号(如下一代 Pascal 架构),CUDA 7.5 中的 cuda_fp16.h 头文件提供了一系列的 intrinsics 来帮助开发者实现 高效的 FP16 计算(FP16x2 SIMD 指令)。另外 cuBLAS 也新加入了一个高度优化的 cublasHgemm() 实现,以在这类设备上提供高性能的半精度浮点的矩阵乘法。
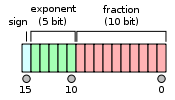
NVIDIA 的 GPU 完整支持符合IEEE 754 floating point standard (2008) 标准的半精度浮点数据类型,具体定义如下:
符号位: 1 bit
指数位: 5 bits
有效数位: 11 bits (10 位显式)
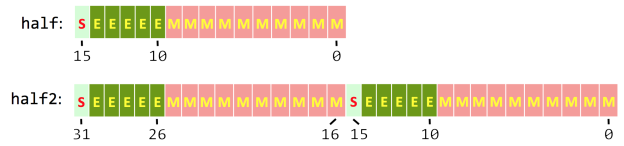
半精度浮点范围:CUDA 7.5 中定义的 half2 结构在一个32位的字中存储了两个半精度浮点数,如下图所示。在 GPU 中这些 half2 的类型将以宽度为 2 的 SIMD 方式进行计算,这也是解释了为什么 FP16 的性能可以两倍于 FP32。
2、关于IEEEp16标准的详细定义
如上节最后一个连接的wiki页面
一些half二进制表示所对应的值
0 01111 0000000000 = 1 0 01111 0000000001 = 1 + 2−10 = 1.0009765625 (next smallest float after 1) 1 10000 0000000000 = −2 0 11110 1111111111 = 65504 (max half precision) 0 00001 0000000000 = 2−14 ≈ 6.10352 × 10−5 (minimum positive normal) 0 00000 1111111111 = 2−14 - 2−24 ≈ 6.09756 × 10−5 (maximum subnormal) 0 00000 0000000001 = 2−24 ≈ 5.96046 × 10−8 (minimum positive subnormal) 0 00000 0000000000 = 0 1 00000 0000000000 = −0 0 11111 0000000000 = infinity 1 11111 0000000000 = −infinity 0 01101 0101010101 = 0.333251953125 ≈ 1/3
3、自己写的fp16加法
加法函数
//size为数据的多少,一共有size/2个half2型数据
__global__ void myHalf2Add(half2 *a, half2 *b, half2 *c, int size)
{
int idx = blockDim.x * blockIdx.x + threadIdx.x;
const int stride = gridDim.x*blockDim.x;
for (int i = idx; i<size / 2; i += stride)
c[idx] = __hadd2(a[idx], b[idx]);
}完整代码
#include "cuda_fp16.h"
#include <cuda_runtime_api.h>
#include "helper_cuda.h"
#include "cudaCode.h"
#include <cstdlib>
#include <iostream>
using namespace std;
#define CHECK(call) \
{ \
const cudaError_t error = call; \
if (error != cudaSuccess) \
{ \
printf("Error: %s: %d, ", __FILE__, __LINE__); \
printf("code: %d, reason: %s\n", error, cudaGetErrorString(error)); \
system("pause"); \
} \
}
//size为转换前float数据个数,转换后由size/2个half2存储所有数据
__global__ void float22Half2Vec(float2 *src, half2 *des, int size)
{
int idx = blockDim.x * blockIdx.x + threadIdx.x;
const int stride = gridDim.x*blockDim.x;
for (int i = idx; i<size / 2; i += stride)
des[i] = __float22half2_rn(src[i]);
}
__global__ void half22Float2Vec(half2 *src, float2 *des, int size)
{
int idx = blockDim.x * blockIdx.x + threadIdx.x;
const int stride = gridDim.x*blockDim.x;
for (int i = idx; i<size / 2; i += stride)
des[i] = __half22float2(src[i]);
}
//size为数据的多少,一共有size/2个half2型数据
__global__ void myHalf2Add(half2 *a, half2 *b, half2 *c, int size)
{
int idx = blockDim.x * blockIdx.x + threadIdx.x;
const int stride = gridDim.x*blockDim.x;
for (int i = idx; i<size / 2; i += stride)
c[i] = __hadd2(a[i], b[i]);
}
int main()
{
const int blocks = 128;
const int threads = 128;
size_t size = blocks*threads * 16;
float * vec1 = new float[size];
float * vec2 = new float[size];
float * res = new float[size];
for (int i = 0; i < size; i++)
{
vec2[i] = vec1[i] = i;
}
float * vecDev1, *vecDev2, *resDev;
CHECK(cudaMalloc((void **)&vecDev1, size * sizeof(float)));
CHECK(cudaMalloc((void **)&vecDev2, size * sizeof(float)));
CHECK(cudaMalloc((void **)&resDev, size * sizeof(float)));
CHECK(cudaMemcpy(vecDev1, vec1, size * sizeof(float), cudaMemcpyHostToDevice));
CHECK(cudaMemcpy(vecDev2, vec2, size * sizeof(float), cudaMemcpyHostToDevice));
half2 *vecHalf2Dev1, *vecHalf2Dev2, *resHalf2Dev;
CHECK(cudaMalloc((void **)&vecHalf2Dev1, size * sizeof(float) / 2));
CHECK(cudaMalloc((void **)&vecHalf2Dev2, size * sizeof(float) / 2));
CHECK(cudaMalloc((void **)&resHalf2Dev, size * sizeof(float) / 2));
float22Half2Vec << <128, 128 >> >((float2*)vecDev1, vecHalf2Dev1, size);
float22Half2Vec << <128, 128 >> >((float2*)vecDev2, vecHalf2Dev2, size);
myHalf2Add << <128, 128 >> > (vecHalf2Dev1, vecHalf2Dev2, resHalf2Dev, size);
half22Float2Vec << <128, 128 >> >(resHalf2Dev, (float2*)resDev, size);
CHECK(cudaMemcpy(res, resDev, size * sizeof(float), cudaMemcpyDeviceToHost));
for (int i = 0; i < 128*128*3; i++)//打印出前64个结果,并与CPU结果对比
{
cout << vec1[i] << " + " << vec2[i] << " = " << vec1[i] + vec2[i] << " ? " << res[i] << endl;
}
delete[] vec1;
delete[] vec2;
delete[] res;
CHECK(cudaFree(vecDev1));
CHECK(cudaFree(vecDev2));
CHECK(cudaFree(resDev));
CHECK(cudaFree(vecHalf2Dev1));
CHECK(cudaFree(vecHalf2Dev2));
CHECK(cudaFree(resHalf2Dev));
system("pause");
return 0;
}代码是非常简单的。
half2定义和运算所需要的头文件为cuda_fp16.h
以下为计算结果的一部分,由于使用字节少,计算精度低,所以会有很多数据存在误差。
wiki里面有关于在各个数据范围内,数据的误差。其中数据位0-2048范围内的整数时,数据是完全准确的。基本上所有数据的误差都在千分之一量级。此处注意half型数据精度低,表示的数据范围也比较低,最大能表示65520。
4、进一步使用所需要的文档资料
这里是cuda的半精度内建函数和定义的相关内容。包含:
1.half和half2的算术运算
2.half和half2的比较函数
3.half和half2精度转换和数据传输(包括float2在内的各种数据类型与half和half2的相互转换)
4.half和half2的数学函数
half和half2的定义
5、遇到的问题
使用过程中一定要注意将compute_61,sm_61设置正确(需要将所有低于要求版本的选项都删掉),否则nvcc将默认使用该cuda版本支持的最低架构,cuda8.0将设置为20.低于所需要的5.3,因而编译失败。
错误表现为
1>F:/cuda/vsCuda/learn/fp16ScalarProductLearn/fp16ScalarProductLearn.cu(29): error : identifier "__hadd2" is undefined
6、其他应用
cublas提供了对fp16的支持,并且官方称速度是单精度的2倍。
以下是有人在TX1上做的关于fp16+Faster R-CNN测试
也可以参考我以前的博客实现cublasHgemm运算
New Features in CUDA 7.5是官方介绍的关于cuda7.5叫以前的新特性。
很多应用都是受限于内存带宽,且许多应用都会受益于低精度数据存储时进行高精度计算。NVIDIA CEO黄建勋宣布以后的GPU都会支持混合精度计算。
使用半精度可以在内存中存储2倍大的模型,受限于内存带宽的应用能获取2倍加速(TX1也是)。
特性:
1.cuda_fp16.h中定义了half和half2相关内容
2.cublasSgemmEx()函数提供了fp16数据的混合精度矩阵乘法
3.cublasHgemm() 提供了fp16乘法。Drive PX withTegra X1 GPUs都支持。
4.Windows Remote Desktop使用cuda7.5 windows端可以在没有NVIDIA gpu的情况下使用远程Windows服务器来进行cuda开发(但没说怎么做)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









