







第一周
1、首先介绍的是神经网络,是一个广泛的概念,标准的神经网络如下图所示:
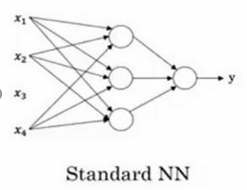
在连线上有不同的比例常数,相当于各个输入的线性组合,然后在圆圈中表示有个激励函数(其实就是一个非线性函数),虽然说借用了生物学中的神经元概念,但是实际上整个模型就是非线性函数和线性函数的组合,越大越复杂的网络能组合出更加复杂、表示能力更强的函数。
2、对于结构化数据,每个输入有划定的维度和特征值,神经网络比较擅长处理。而非结构化数据(图像,音频等)虽然没那么擅长,但是也有比较好的办法:卷积神经网络(CNN)和递归神经网络(RNN)。
第二周
本周的课程以逻辑回归为例,主要讲解以下几个问题:
- 输出从函数值映射到实际问题
- 定义问题的损失函数和代价函数
- 以链式求导为基础的反向传播的计算。
- 向量化
对于这4个问题,看完视频后心得如下:
第一个问题,其实就是我们说的译码,从模型结果映射到实际问题,根据不同的映射方法当然对应不同的损失函数。而编码呢?规范化数据其实就是较好编码的那一类,不规范化数据就是不太好编码的,如何编码译码由我们自己决定,因为现实的问题怎么表示是约定俗称的,放到模型里如何表示是我们设定的,原则只有一个,怎么好算怎么算的好就怎么设定。
第二个问题,逻辑回归中定义的损失函数是
L
(
y
^
,
y
)
=
−
y
log
(
y
^
)
−
(
1
−
y
)
log
(
1
−
y
^
)
L(\hat{y}, y)=-y \log (\hat{y})-(1-y) \log (1-\hat{y})
L(y^,y)=−ylog(y^)−(1−y)log(1−y^)当然也可以定义其他损失函数,如平方误差等,满足
y
^
\hat{y}
y^越接近y时误差越小即可,同时便于后面的计算,不同的误差函数可能带来不同的效果,需要自己的经验和思考。自然的我们定义总的代价函数为:
J
(
w
,
b
)
=
1
m
∑
i
=
1
m
L
(
y
^
(
i
)
,
y
(
i
)
)
=
1
m
∑
i
=
1
m
(
−
y
(
i
)
log
(
y
^
(
i
)
)
−
(
1
−
y
(
i
)
)
log
(
1
−
y
^
(
i
)
)
)
J(w, b)=\frac{1}{m} \sum_{i=1}^{m} L(\hat{y}^{(i)}, y^{(i)})=\frac{1}{m} \sum_{i=1}^{m}\left(-y^{(i)} \log(\hat{y}^{(i)})-(1-y^{(i)})\log(1-\hat{y}^{(i)})\right)
J(w,b)=m1i=1∑mL(y^(i),y(i))=m1i=1∑m(−y(i)log(y^(i))−(1−y(i))log(1−y^(i)))
第三个问题就是求导的基础,梯度下降就是逼近最小误差。
第四个问题向量化。由x横向扩展到
x
(
i
)
x^{(i)}
x(i),由单个结点竖向扩展到很多个结点。等我去学一下做动画再贴个图就一目了然了。
第三周
这一周主要以浅层神经网络为例教我们搭建一个浅层网络。实际上很多概念和逻辑回归时差不多,主要分为以下几点:
- 介绍输入层、输出层、隐藏层、层数等概念。
- 向量化,同一批次多样本同时计算,不显式使用循环。
- 为什么不使用线性激活函数(线性函数组合仍是线性函数)。至于那种非线性函数比较好,则是实验效果得出的结论。
- 反向传播的计算,梯度下降首先是有个损失函数,从当前位置向损失函数最小处逼近,也就是 y ^ \hat y y^向 y y y逼近, x x x是不变量, w w w和 b b b等参数是因变量。
- 讲解了随机初始化的必要性。(初始化为0或者对称初始化将导致一些问题)
第四周
第四周就是把浅层神经网络扩展成深度神经网络,主要讲了以下几点:
- 搭建网络后手动校对网络层数
- 参数和超参数的概念















 5533
5533











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









