







公众号:尤而小屋
作者:Peter
编辑:Peter
大家好,我是Peter
本文中介绍的是第21-25题目,主要涉及的知识点是:
- 分组统计求和,百分比
- 如何利用SQL实现排序
- having使用
- union拼接

5个题目是:
- 查询不同老师所教不同课程平均分从高到低显示
- 查询所有课程的成绩第2名到第3名的学生信息及该课程成绩
- 统计各科成绩各分数段人数:课程编号,课程名称,[100-85],[85-70],[70-60],[0-60]及所占百分比
- 查询学生的平均成绩及名次
- 查询各科成绩前三名的记录
题目21
题目需求
查询不同老师所教不同课程平均分从高到低显示
分析过程
涉及到的表主要是
老师:Teacher
课程:Course,作为主表
成绩:Score
通过3个表的连接求出来即可
SQL实现
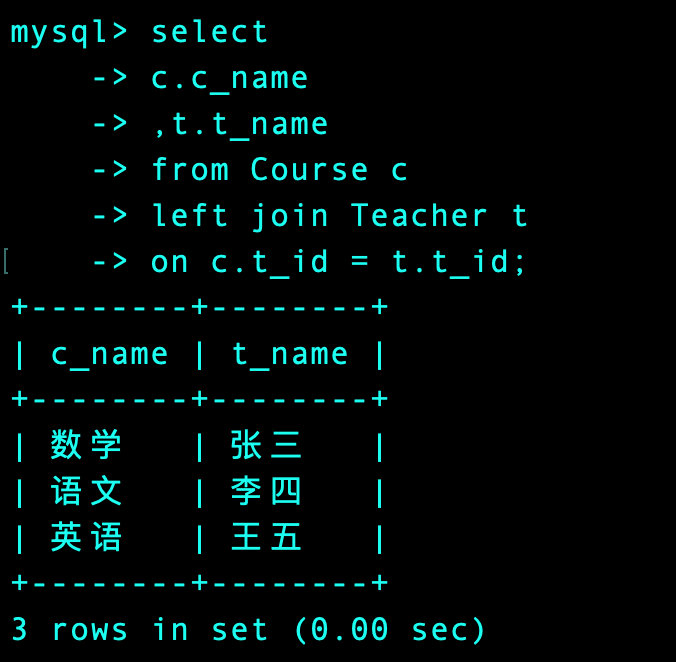
先找出每个老师教授了哪些课程:
select
c.c_name
,t.t_name
from Course c
left join Teacher t
on c.t_id = t.t_id;
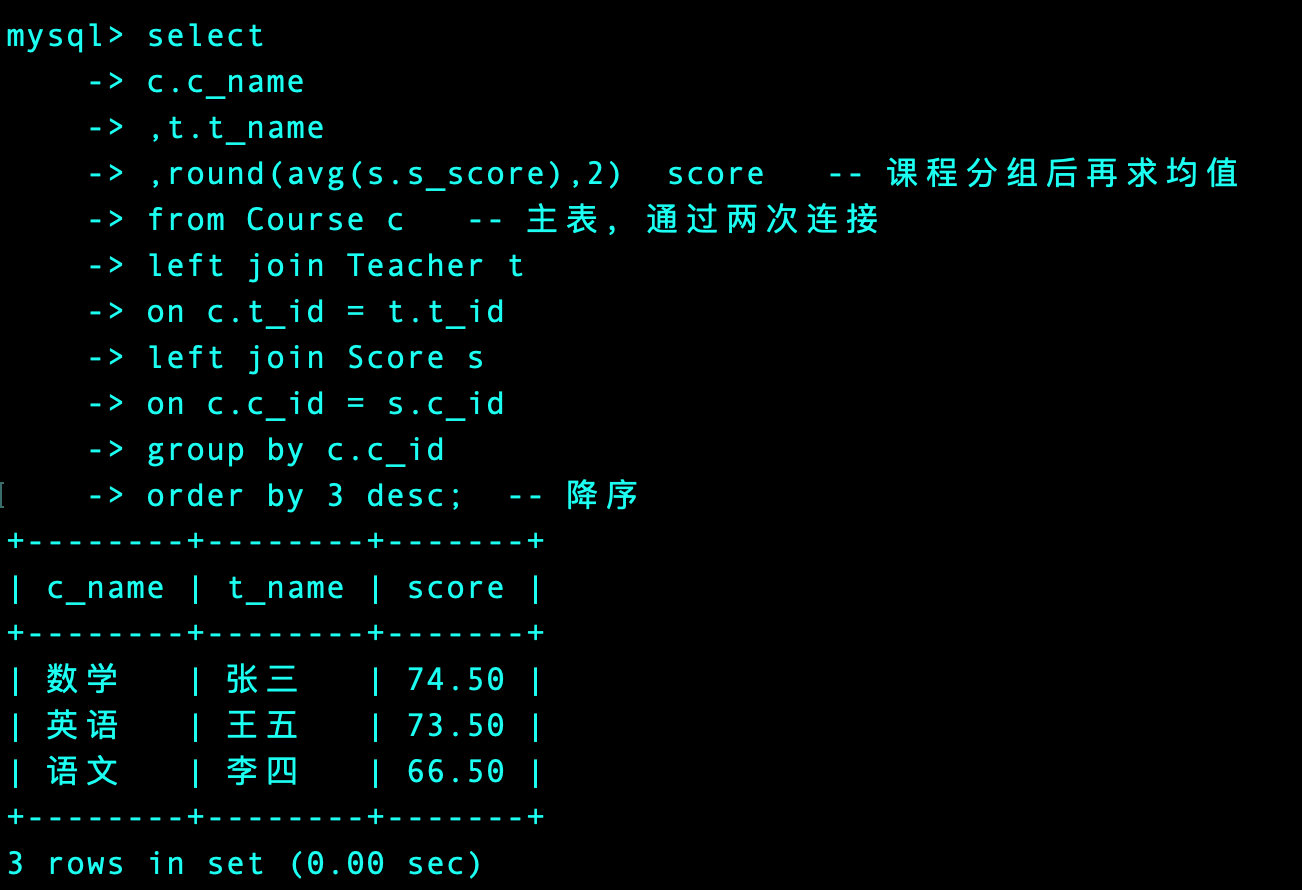
将上面的结果和成绩表连接起来:
select
c.c_name
,t.t_name
,round(avg(s.s_score),2) score -- 课程分组后再求均值
from Course c -- 主表,通过两次连接
left join Teacher t
on c.t_id = t.t_id
left join Score s
on c.c_id = s.c_id
group by c.c_id -- 课程分组
order by 3 desc; -- 降序
题目22
题目需求
查询所有课程的成绩第2名到第3名的学生信息及该课程成绩
分析过程
成绩:Score
学生信息:Student
我们通过取出每科的第2、3名拼接起来再取出学生信息
SQL实现
自己的方法
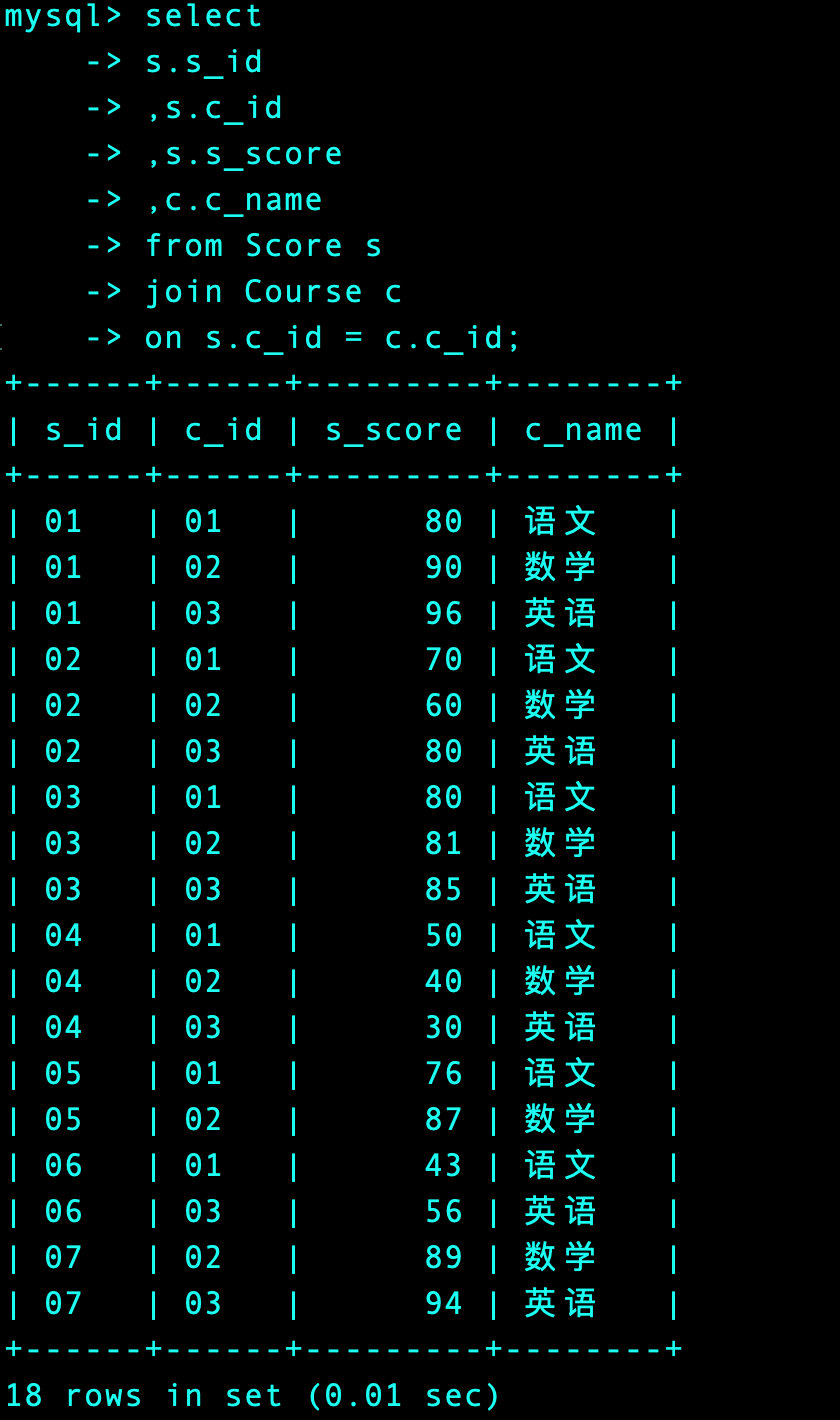
1、课程表和成绩表连接起来,显示所有的课程和成绩信息
select
s.s_id
,s.c_id
,s.s_score
,c.c_name
from Score s
join Course c
on s.c_id = c.c_id
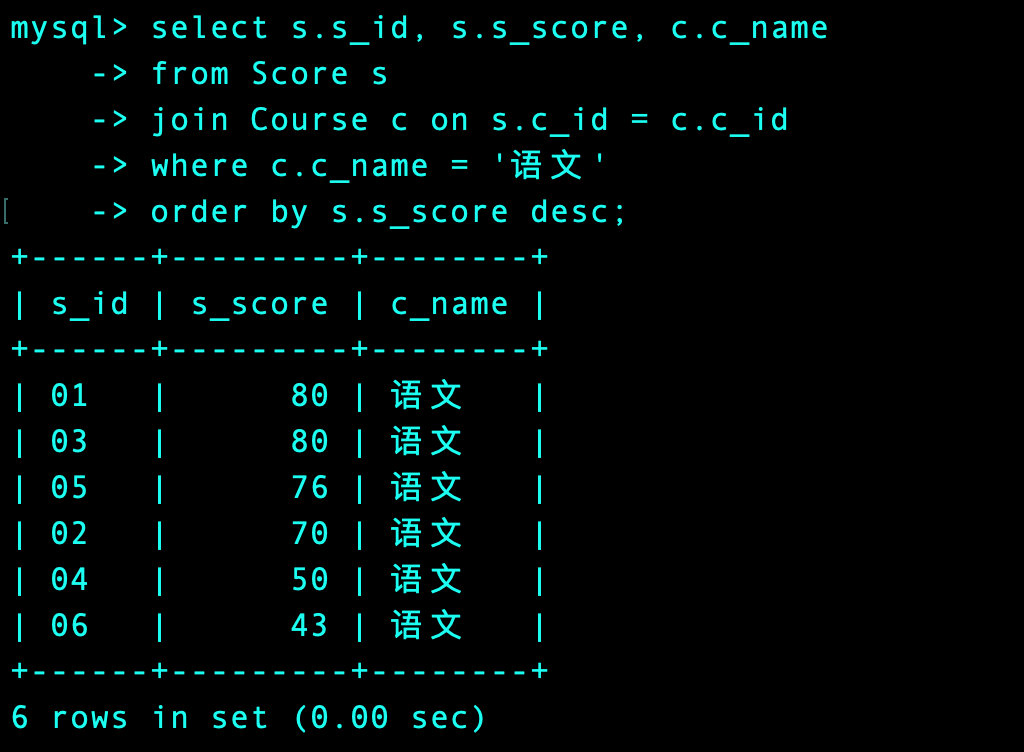
2、查出全部的语文成绩
select s.s_id, s.s_score, c.c_name
from Score s
join Course c on s.c_id = c.c_id
where c.c_name = '语文'
order by s.s_score desc;
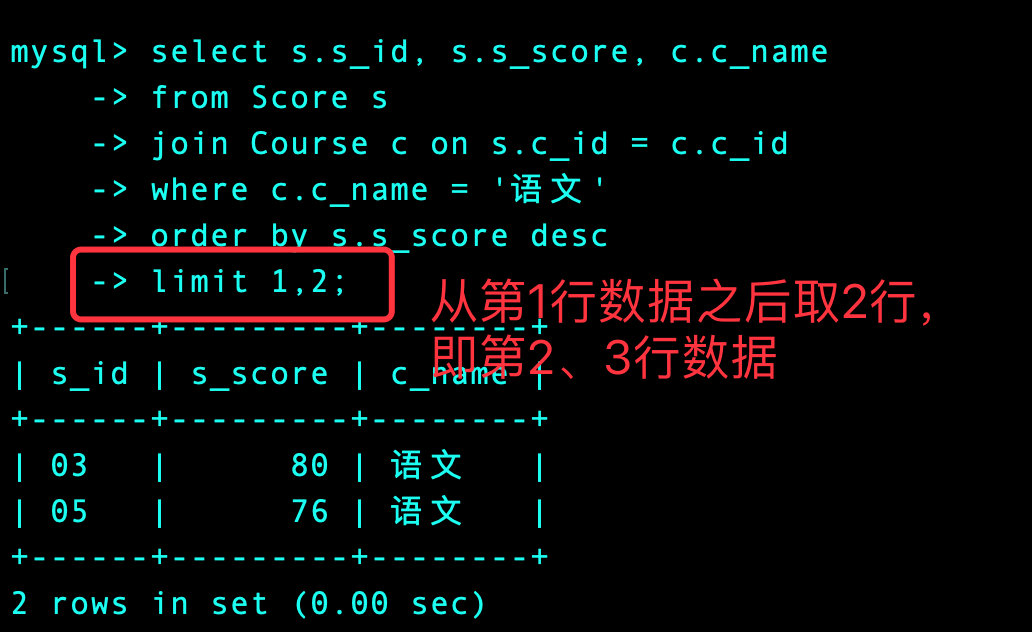
3、我们找出语文的第2、3的学生
select s.s_id, s.s_score, c.c_name
from Score s
join Course c on s.c_id = c.c_id
where c.c_name = '语文'
order by s.s_score desc
limit 1, 2;
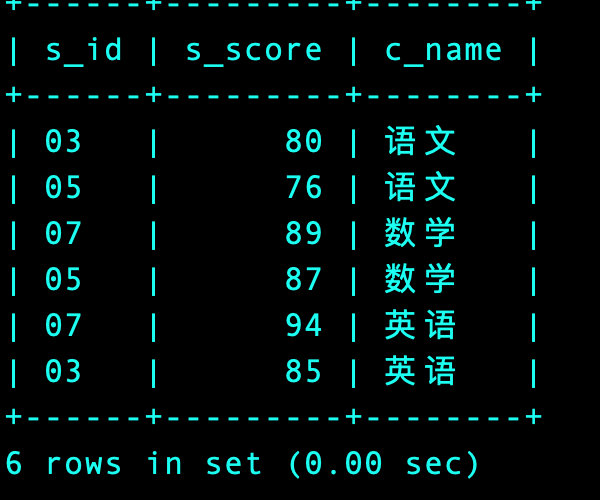
4、同时求出语文、数学、英语的分数,并且通过union拼接
-- union连接
(select s.s_id, s.s_score, c.c_name
from Score s
join Course c on s.c_id = c.c_id
where c.c_name = '语文'
order by s.s_score desc
limit 1, 2)
union
(select s.s_id, s.s_score, c.c_name
from Score s
join Course c on s.c_id = c.c_id
where c.c_name = '数学'
order by s.s_score desc
limit 1, 2)
union
((select s.s_id, s.s_score, c.c_name
from Score s
join Course c on s.c_id = c.c_id
where c.c_name = '英语'
order by s.s_score desc
limit 1, 2))
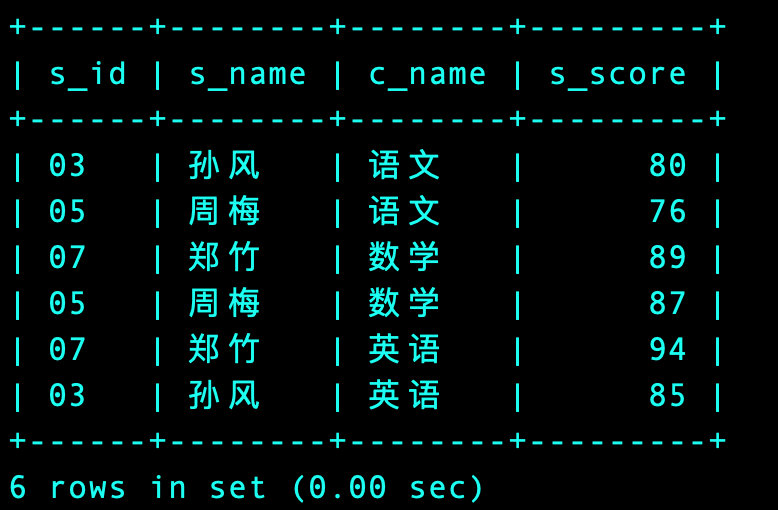
5、将上面的结果学生信息表进行连接即可
好歹是实现了😭
-- 最终脚本
-- !!!!真的需要好好优化下
select
s.s_id
,s.s_name
,t.c_name
,t.s_score
from Student s
join (-- union连接
(select s.s_id, s.s_score, c.c_name
from Score s
join Course c on s.c_id = c.c_id
where c.c_name = '语文'
order by s.s_score desc
limit 1, 2)
union
(select s.s_id, s.s_score, c.c_name
from Score s
join Course c on s.c_id = c.c_id
where c.c_name = '数学'
order by s.s_score desc
limit 1, 2)
union
((select s.s_id, s.s_score, c.c_name
from Score s
join Course c on s.c_id = c.c_id
where c.c_name = '英语'
order by s.s_score desc
limit 1, 2)))t -- 临时表t
on s.s_id = t.s_id
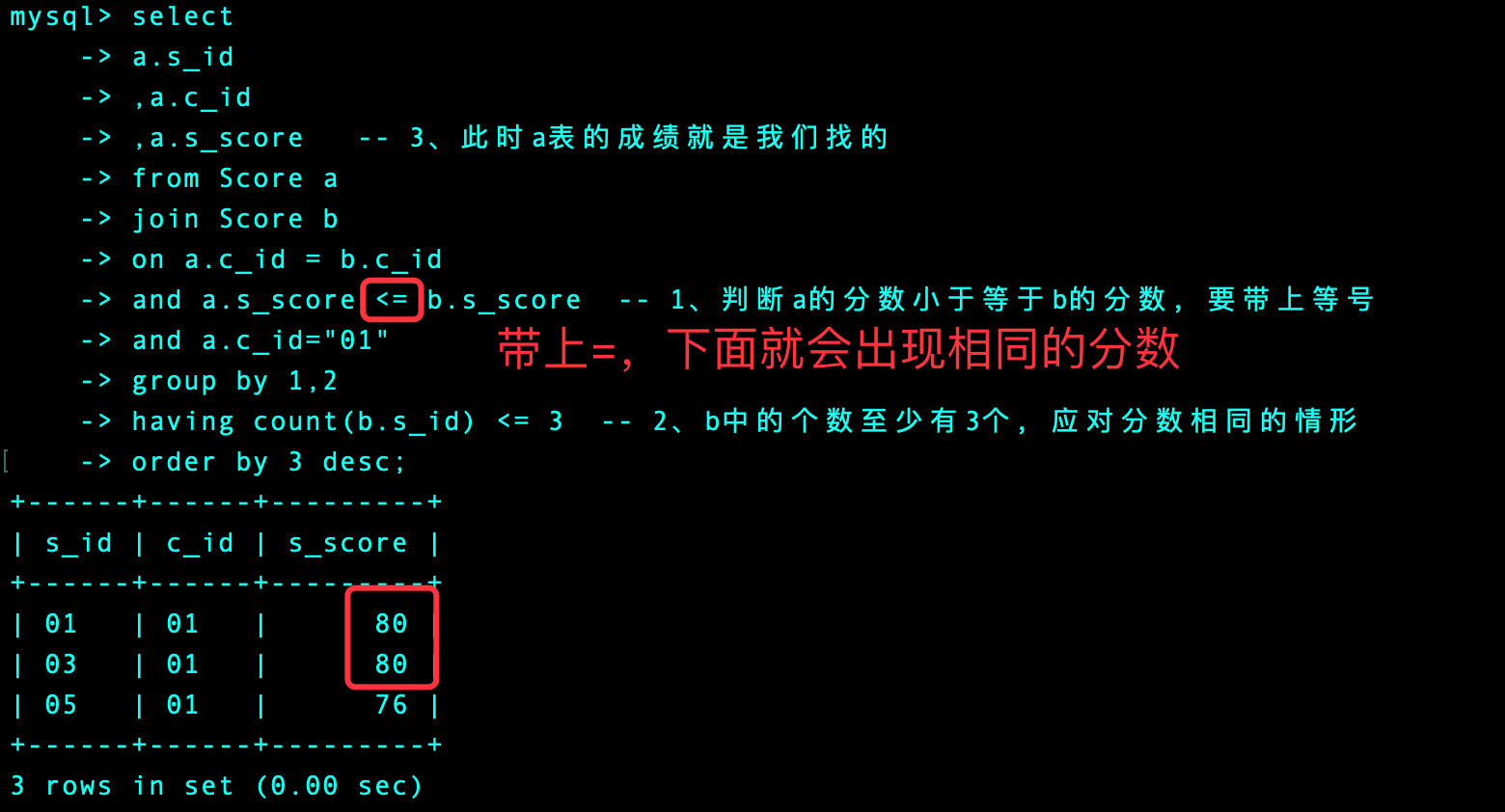
和第25题相同的方法
1、以语文为例,首先我们找出前3名的成绩(包含相同的成绩)
-- 语文
select
a.s_id
,a.c_id
,a.s_score -- 3、此时a表的成绩就是我们找的
from Score a
join Score b
on a.c_id = b.c_id
and a.s_score <= b.s_score -- 1、判断a的分数小于等于b的分数,要带上等号
and a.c_id="01"
group by 1,2
having count(b.s_id) <= 3 -- 2、b中的个数至少有3个,应对分数相同的情形
order by 3 desc
limit 1,2
-- 语文
select
a.s_id
,a.c_id
,a.s_score -- 3、此时a表的成绩就是我们找的
from Score a
join Score b
on a.c_id = b.c_id
and a.s_score <= b.s_score -- 1、判断a的分数小于等于b的分数,要带上等号
and a.c_id="01"
group by 1,2
having count(b.s_id) <= 3 -- 2、b中的个数至少有3个,应对分数相同的情形
order by 3 desc
limit 1,2; -- 取得第2、3名
在通过数学和英语的类似操作得到2、3名的成绩,再进行拼接即可
题目23
题目需求
统计各科成绩各分数段人数:课程编号,课程名称,[100-85],[85-70],[70-60],[0-60]及所占百分比
分析过程
课程:Course
成绩:Score
通过case语句来进行判断,count语句进行统计,sum语句进行求和
SQL实现
自己的方法
1、如何对每个成绩进行分组展示:ABCD代表相应的等级
select
c_id
,s_score
,case when s_score >= 85 and s_score<= 100 then 'A' -- 大小关系必须分两次写,一次写的话MySQL无法识别
when 70 <= s_score and s_score < 85 then 'B'
when 60 <= s_score and s_score < 70 then 'C'
when 0 <= s_score and s_score < 60 then 'D'
else '其他' end as 'category'
from Score s;
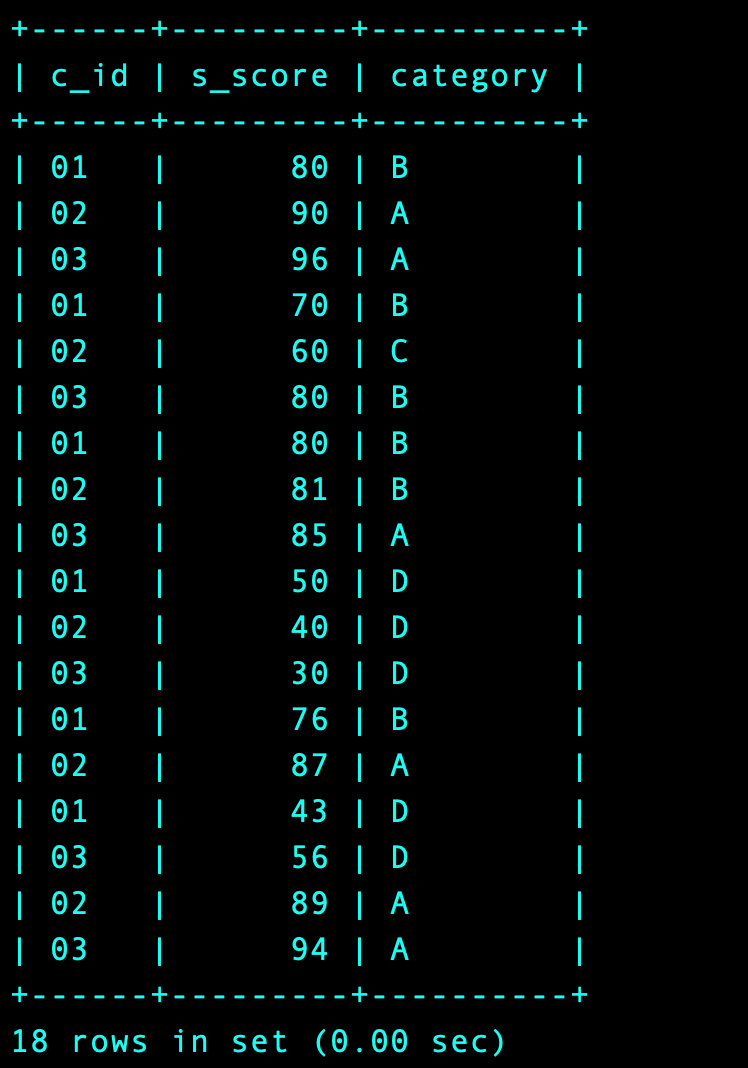
2、将两个表关联起来展示数据
-- 1、查看全部课程和成绩信息
select
s.c_id
,c.c_name
,s.s_score
,case when s.s_score >= 85 and s.s_score<= 100 then 'A' -- 大小关系必须分两次写,一次写的话MySQL无法识别
when 70 <= s.s_score and s.s_score < 85 then 'B'
when 60 <= s.s_score and s.s_score < 70 then 'C'
when 0 <= s.s_score and s.s_score < 60 then 'D'
else '其他' end as 'category'
from Score s
join Course c
on s.c_id = c.c_id;
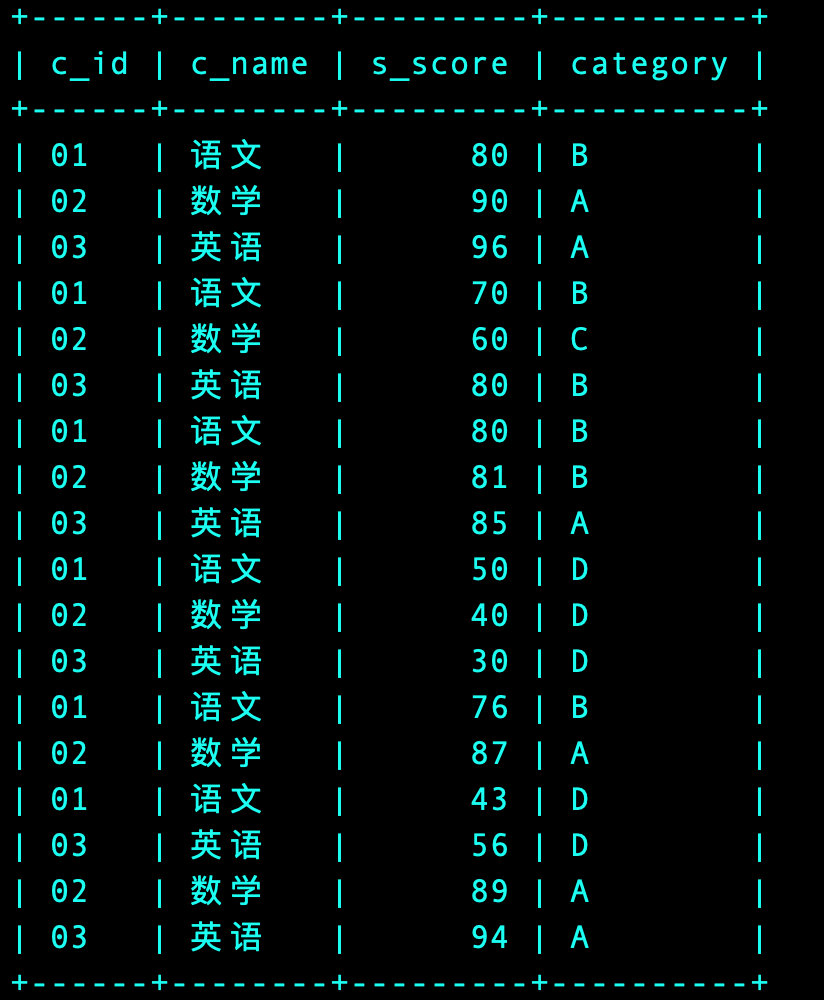
3、完整代码
select
s.c_id 编号
,c.c_name 科目
,sum(case when s.s_score >= 85 and s.s_score<= 100 then 1 else 0 end) "[85,100]人数"
,round(100 * (sum(case when s.s_score >= 85 and s.s_score<= 100 then 1 else 0 end) / sum(case when s.s_score then 1 else 0 end)), 2) as '[85,100]百分比'
,sum(case when s.s_score >= 70 and s.s_score<= 85 then 1 else 0 end) "[70,85]人数"
,round(100 * (sum(case when s.s_score >= 70 and s.s_score<= 85 then 1 else 0 end) / sum(case when s.s_score then 1 else 0 end)), 2) as '[70,85]百分比'
,sum(case when s.s_score >= 60 and s.s_score<= 70 then 1 else 0 end) "[60,70]人数"
,round(100 * (sum(case when s.s_score >= 60 and s.s_score<= 70 then 1 else 0 end) / sum(case when s.s_score then 1 else 0 end)), 2) as '[60,70]百分比'
,sum(case when s.s_score >= 0 and s.s_score<= 60 then 1 else 0 end) "[0,60]人数"
,round(100 * (sum(case when s.s_score >= 0 and s.s_score<= 60 then 1 else 0 end) / sum(case when s.s_score then 1 else 0 end)), 2) as '[0,60]百分比'
from Score s
left join Course c
on s.c_id = c.c_id
group by s.c_id, c.c_name
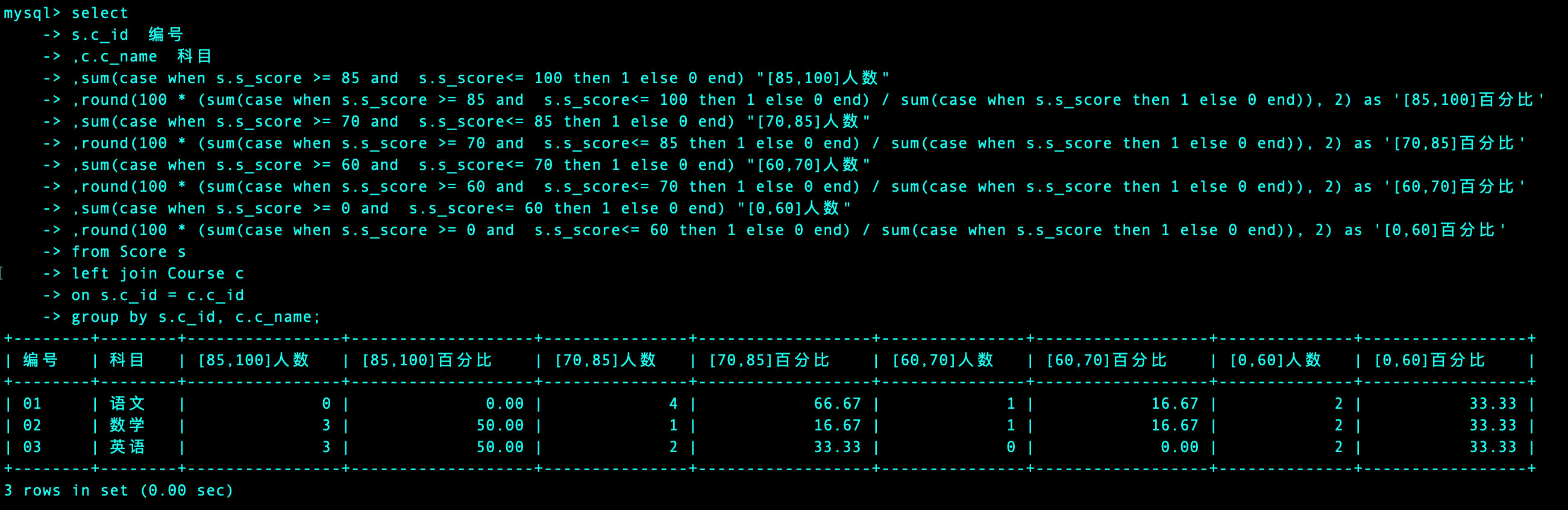
参考方法
1、先统计每个阶段的人数和占比
select
c_id
,sum(case when s_score > 85 and s_score <=100 then 1 else 0 end) as '85-100'
,round(100 * (sum(case when s_score > 85 and s_score <= 100 then 1 else 0 end) / count(*)), 2) '占比'
from Score
group by c_id; -- 分课程统计总数和占比
-- 方式2
select
c_id
,sum(case when s_score > 85 and s_score <=100 then 1 else 0 end) as '85-100'
,round(100 * (sum(case when s_score > 85 and s_score <= 100 then 1 else 0 end) / count(case when s_score then 1 else 0 end)), 2) '占比' -- 不同count(*)
from Score
group by c_id;
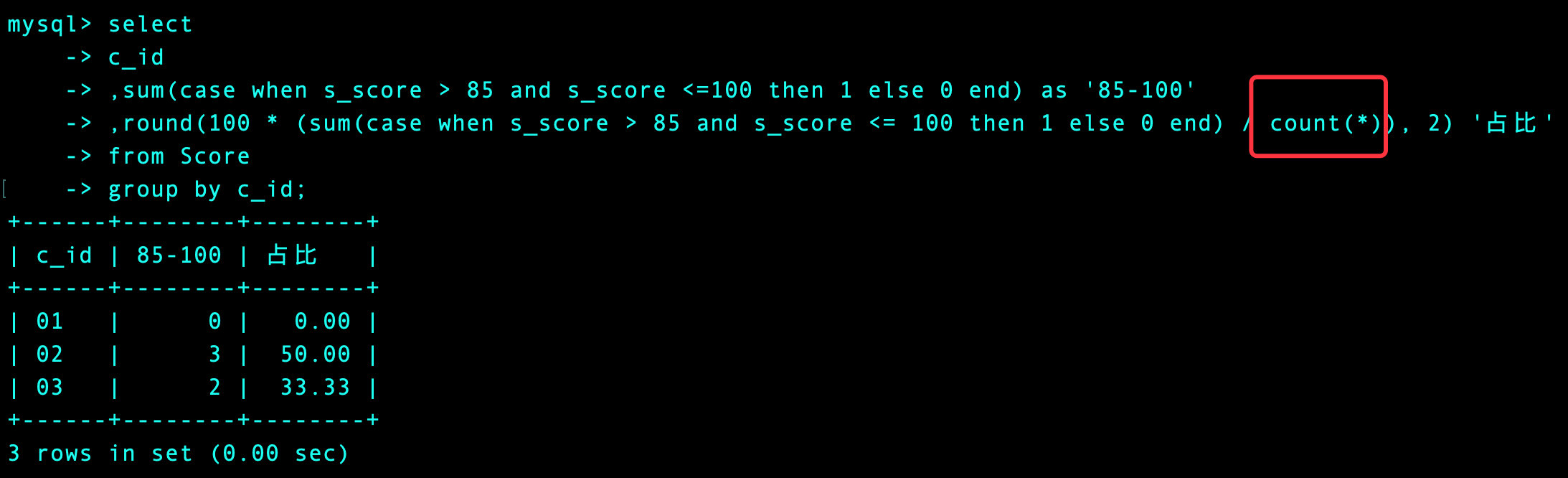
注意对比:
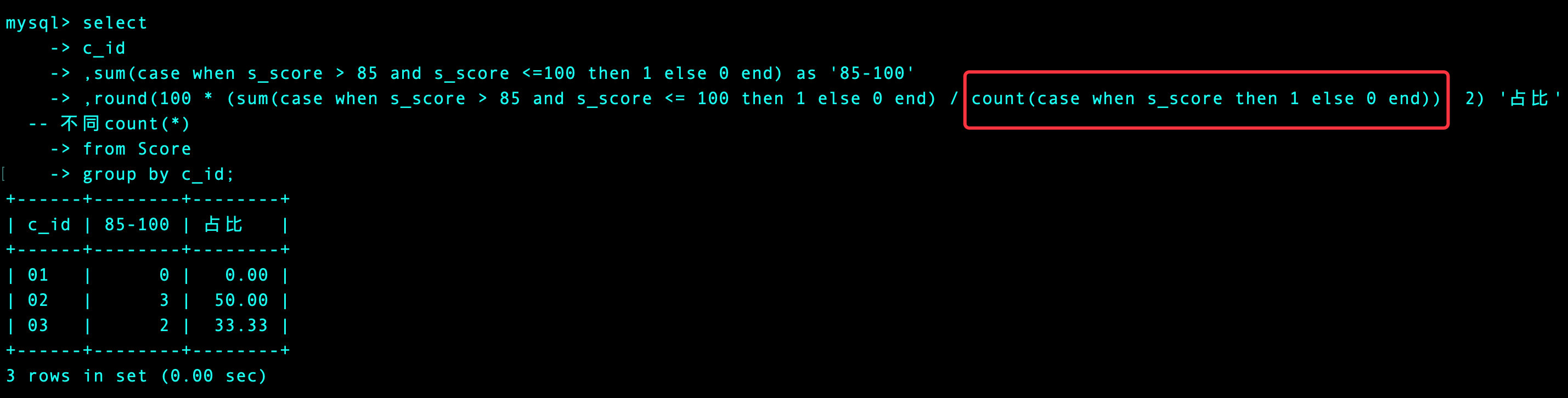
2、我们将4种情况同时查出来
select
c_id
,sum(case when s_score > 85 and s_score <=100 then 1 else 0 end) as '85-100'
,round(100 * (sum(case when s_score > 85 and s_score <= 100 then 1 else 0 end) / count(*)), 2) '[85,100]占比'
,sum(case when s_score > 70 and s_score <=85 then 1 else 0 end) as '70-85'
,round(100 * (sum(case when s_score > 70 and s_score <= 85 then 1 else 0 end) / count(*)), 2) '[70,85]占比'
,sum(case when s_score > 60 and s_score <=70 then 1 else 0 end) as '60-70'
,round(100 * (sum(case when s_score > 60 and s_score <= 70 then 1 else 0 end) / count(*)), 2) '[60,70]占比'
,sum(case when s_score >=0 and s_score <=60 then 1 else 0 end) as '0-60'
,round(100 * (sum(case when s_score > 0 and s_score <= 60 then 1 else 0 end) / count(*)), 2) '[0,60]占比'
from Score
group by c_id; -- 分课程统计总数和占比
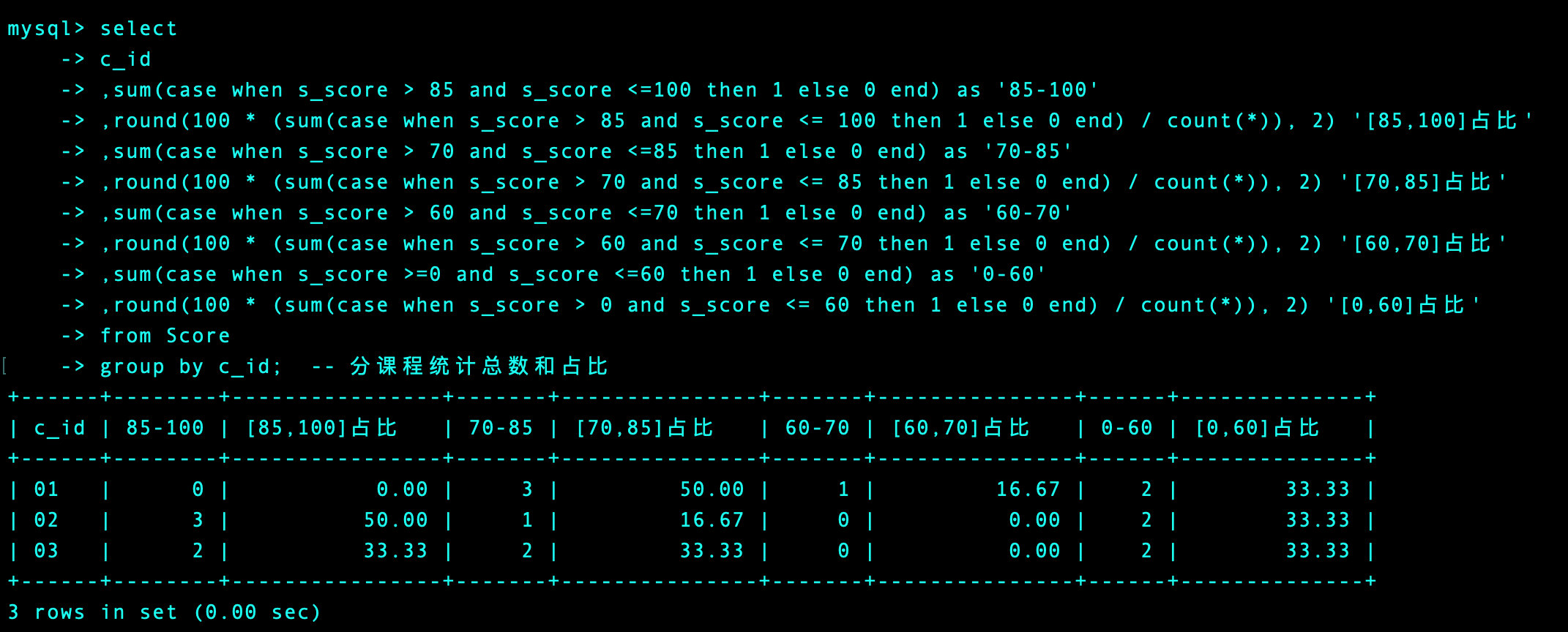
3、将科目名称连接起来
-- 整体和自己的方法是类似的
select
s.c_id
,c.c_name
,sum(case when s_score > 85 and s_score <=100 then 1 else 0 end) as '85-100'
,round(100 * (sum(case when s_score > 85 and s_score <= 100 then 1 else 0 end) / count(*)), 2) '[85,100]占比'
,sum(case when s_score > 70 and s_score <=85 then 1 else 0 end) as '70-85'
,round(100 * (sum(case when s_score > 70 and s_score <= 85 then 1 else 0 end) / count(*)), 2) '[70,85]占比'
,sum(case when s_score > 60 and s_score <=70 then 1 else 0 end) as '60-70'
,round(100 * (sum(case when s_score > 60 and s_score <= 70 then 1 else 0 end) / count(*)), 2) '[60,70]占比'
,sum(case when s_score >=0 and s_score <=60 then 1 else 0 end) as '0-60'
,round(100 * (sum(case when s_score > 0 and s_score <= 60 then 1 else 0 end) / count(*)), 2) '[0,60]占比'
from Score s
left join Course c
on s.c_id = c.c_id
group by s.c_id, c.c_name; -- 分课程统计总数和占比
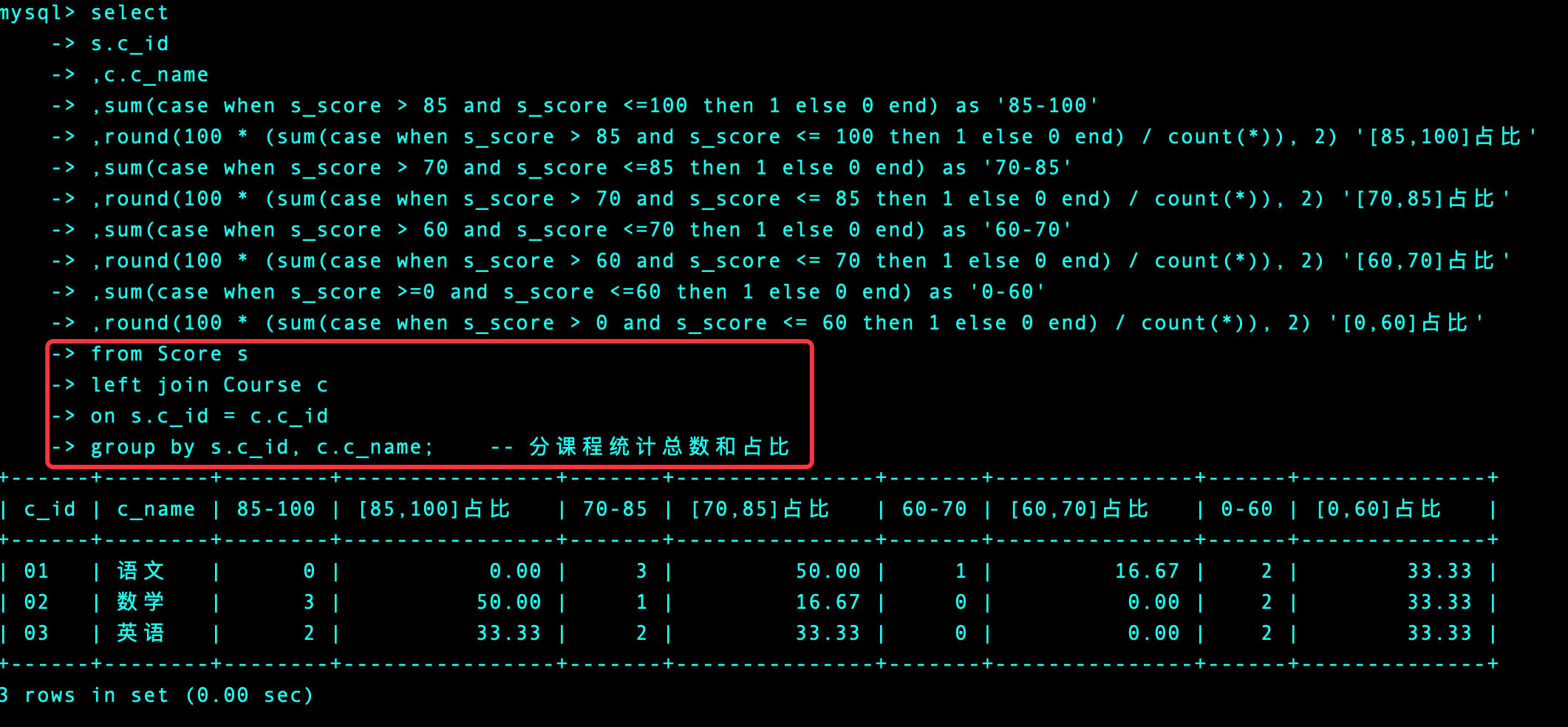
题目24
题目需求
查询学生的平均成绩及名次
分析过程
学生:Student
成绩:Score
平均:avg函数
名次:通过排序来解决
SQL实现
自己的方法
1、先求出每个人的平均分
-- 自己的方法
select
sc.s_id
,s.s_name
,round(avg(sc.s_score),2) avg_score
from Score sc
join Student s
on sc.s_id=s.s_id
group by sc.s_id,s.s_name
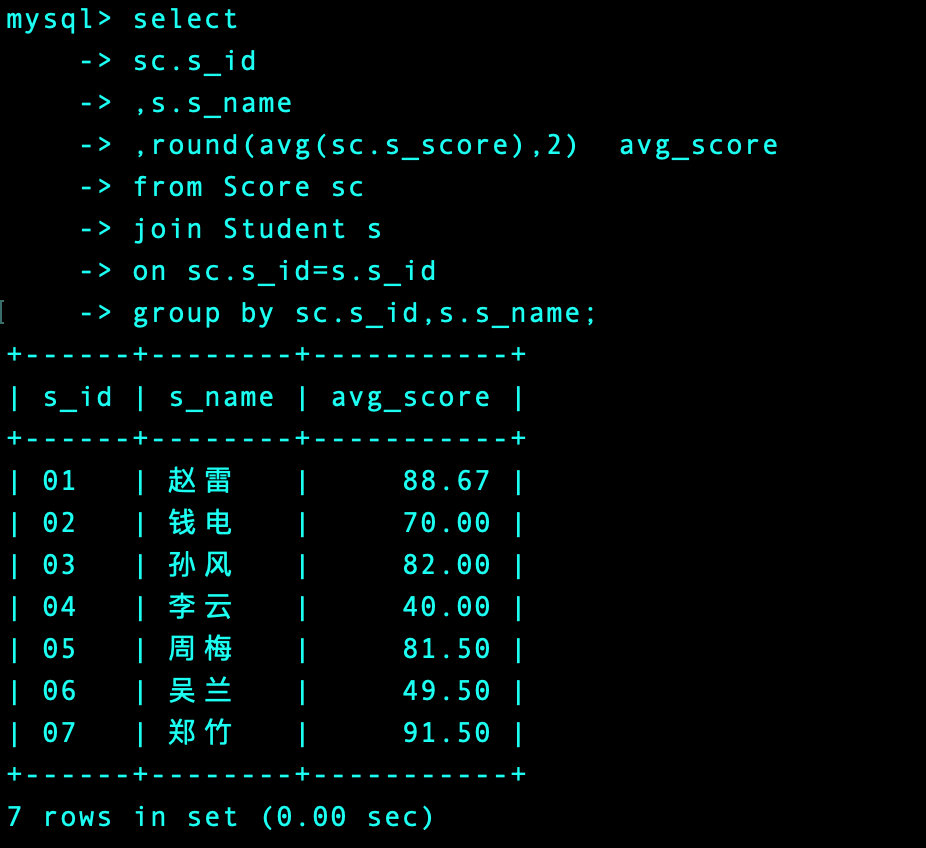
2、我们对上面的结果进行排序
!!!MySQL5中是没有rank函数的,需要自己实现排序功能
-- MYSQL5.7中没有rank函数,所以通过自连接实现
select
t1.s_id
,t1.s_name
,t1.avg_score
,(select count(distinct t2.avg_score)
from (select
sc.s_id
,s.s_name
,round(avg(sc.s_score),2) avg_score
from Score sc
join Student s
on sc.s_id=s.s_id
group by sc.s_id,s.s_name)t2 -- 临时表t2也是上面的结果
where t2.avg_score >= t1.avg_score
) rank
from (select
sc.s_id
,s.s_name
,round(avg(sc.s_score),2) avg_score
from Score sc
join Student s
on sc.s_id=s.s_id
group by sc.s_id,s.s_name)t1 -- 临时表t1就是上面的结果
order by t1.avg_score desc;
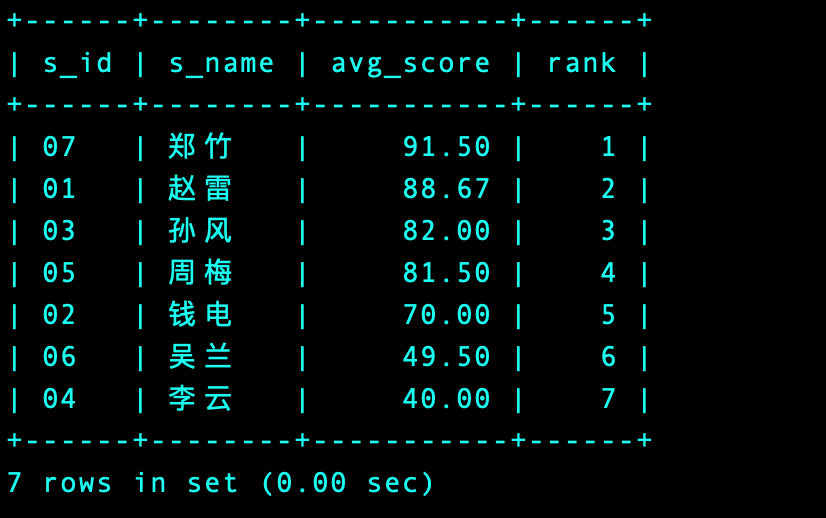
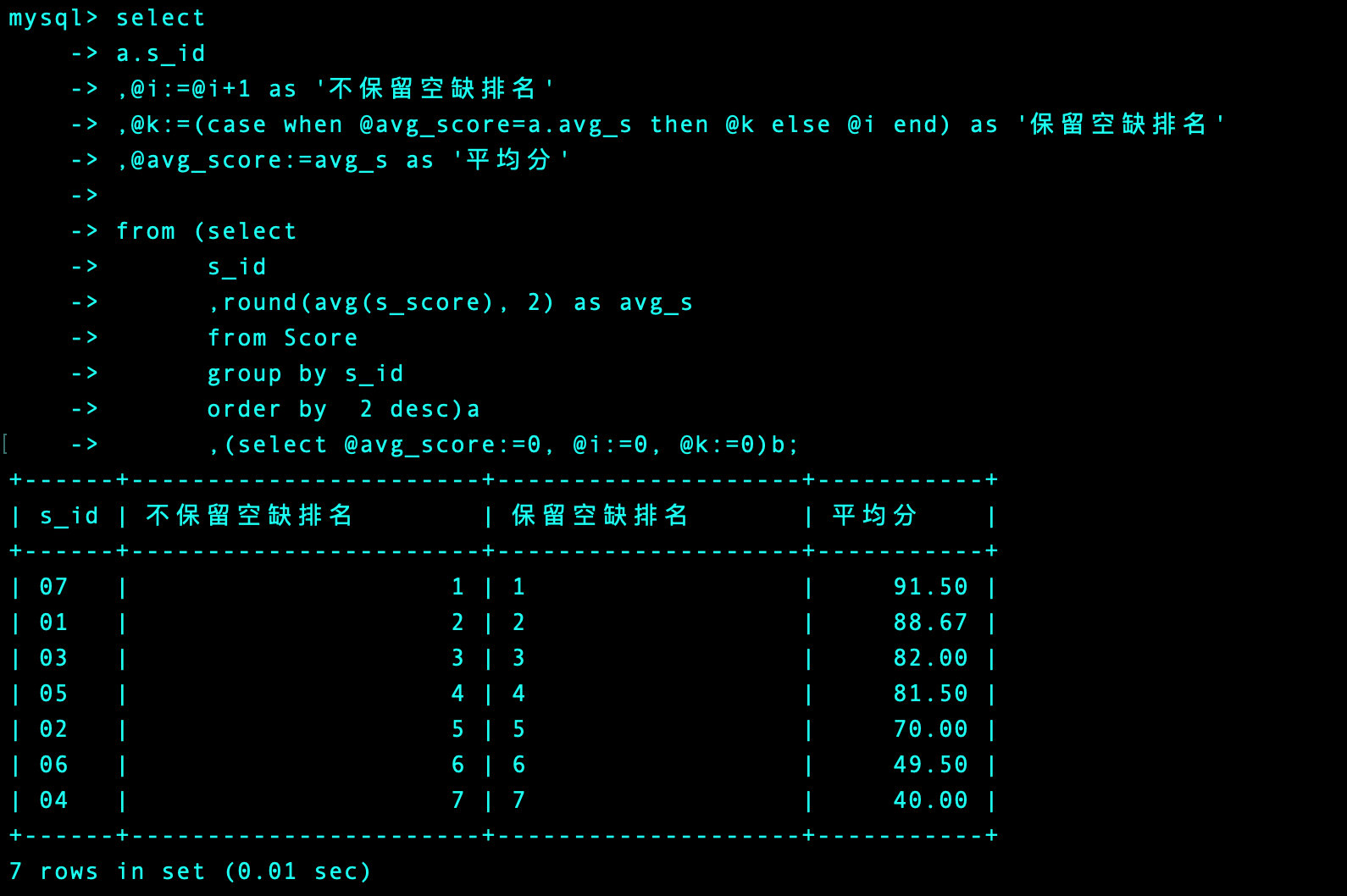
参考方法
select
a.s_id -- 学号
,@i:=@i+1 as '不保留空缺排名' -- 直接i的自加
,@k:=(case when @avg_score=a.avg_s then @k else @i end) as '保留空缺排名'
,@avg_score:=avg_s as '平均分' -- 表a中的值
from (select
s_id
,round(avg(s_score), 2) as avg_s
from Score
group by s_id
order by 2 desc)a -- 表a:平均成绩的排序和学号
,(select @avg_score:=0, @i:=0, @k:=0)b -- 表b:通过变量设置初始值
实现rank函数
select
s.s_name -- 姓名
,s.s_score -- 成绩
,(select count(distinct t2.s_score)
from Score t2
where t2.s_score >= t1.s_score) rank -- 在t2分数大的情况下,统计t2的去重个数
from Score t1
order by t1.s_score desc; -- 分数降序排列
举例子来说明这个脚本:
| 姓名 | 成绩 |
|---|---|
| 张三 | 89 |
| 李四 | 90 |
| 王五 | 78 |
| 小明 | 98 |
| 小红 | 60 |
- 当t1.s_score=89,满足t2.s_score > = t1.s_score的有98,90和89,此时count(distinct t2.s_score) 的个数就是3
- 当t1.s_score=90,满足t2.s_score > = t1.s_score的有98和90,此时count(distinct t2.s_score) 的个数就是2
- 当t1.s_score=78,满足t2.s_score > = t1.s_score的有98、90、89和78,此时count(distinct t2.s_score) 的个数就是4
- 当t1.s_score=98,满足t2.s_score > = t1.s_score的只有98,此时count(distinct t2.s_score) 的个数就是1
- 当t1.s_score=60,满足t2.s_score > = t1.s_score的有89、90、78、98、60,此时count(distinct t2.s_score) 的个数就是5
通过上面的步骤,我们发现:t1中每个分数对应的个数就是它的排名
题目25
题目需求
查询各科成绩前三名的记录
分析过程
这题和第22题是属于一个类型的:找到每个科目的指定名次的成绩,使用的表是:Score
SQL实现
自己的方法
1、首先我们找出语文的前3名
select s.s_id, s.s_score, c.c_name
from Score s
join Course c on s.c_id = c.c_id
where c.c_name = '语文'
order by s.s_score desc -- 降序之后取出前3条记录
limit 3;
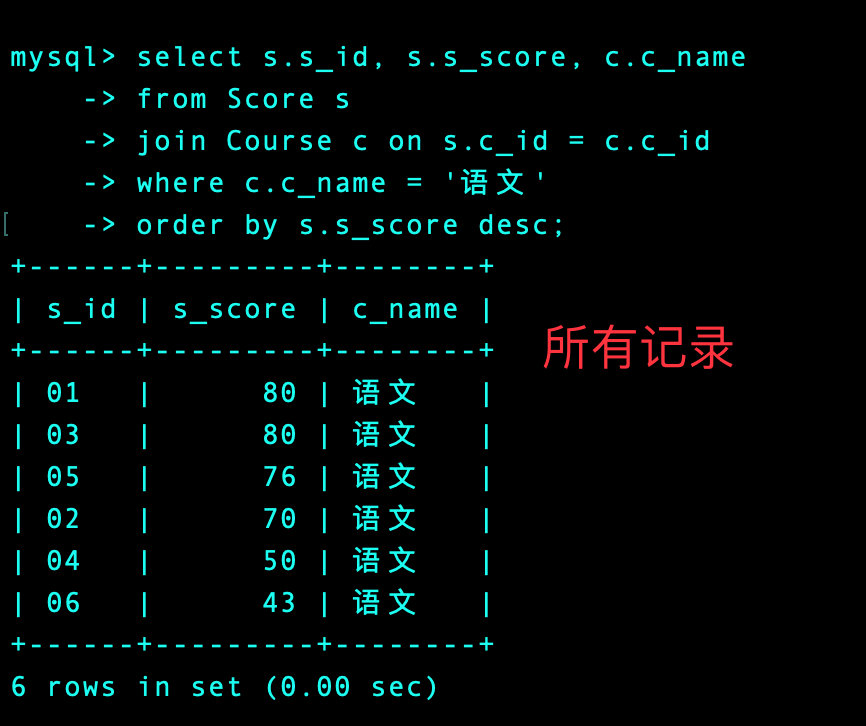
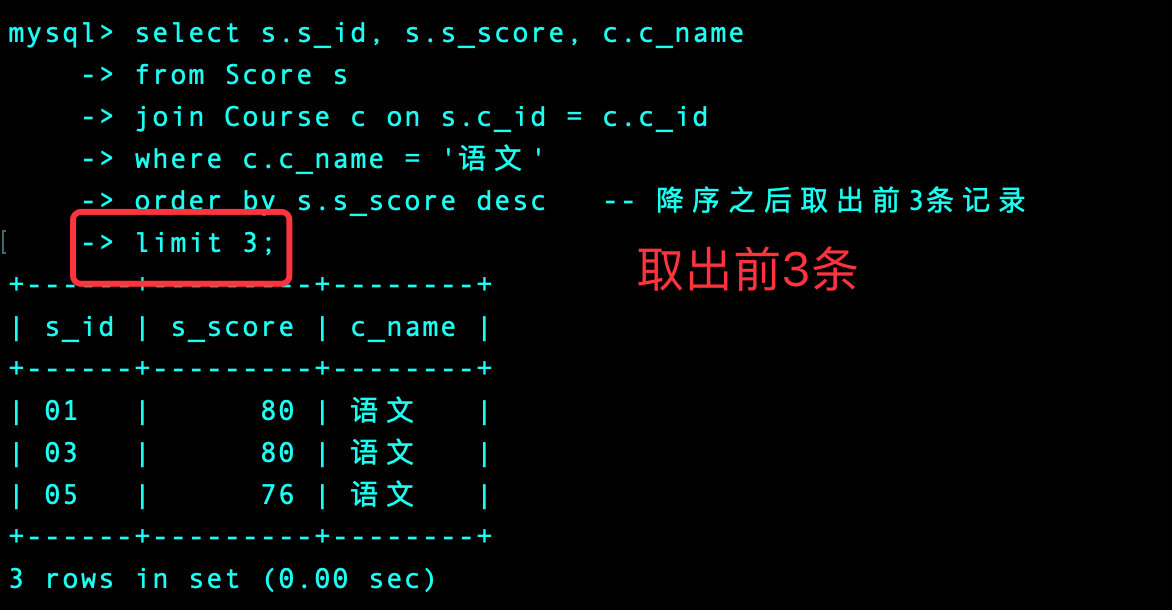
2、通过同样的方法我们可以求出数学和英语的前3条记录,然后通过union进行联结,有待优化😭
-- 自己的脚本
(select s.s_id, s.s_score, c.c_name
from Score s
join Course c on s.c_id = c.c_id
where c.c_name = '语文'
order by s.s_score desc -- 降序之后取出前3条记录
limit 3)
union
(select s.s_id, s.s_score, c.c_name
from Score s
join Course c on s.c_id = c.c_id
where c.c_name = '数学'
order by s.s_score desc
limit 3)
union
(select s.s_id, s.s_score, c.c_name
from Score s
join Course c on s.c_id = c.c_id
where c.c_name = '英语'
order by s.s_score desc
limit 3)
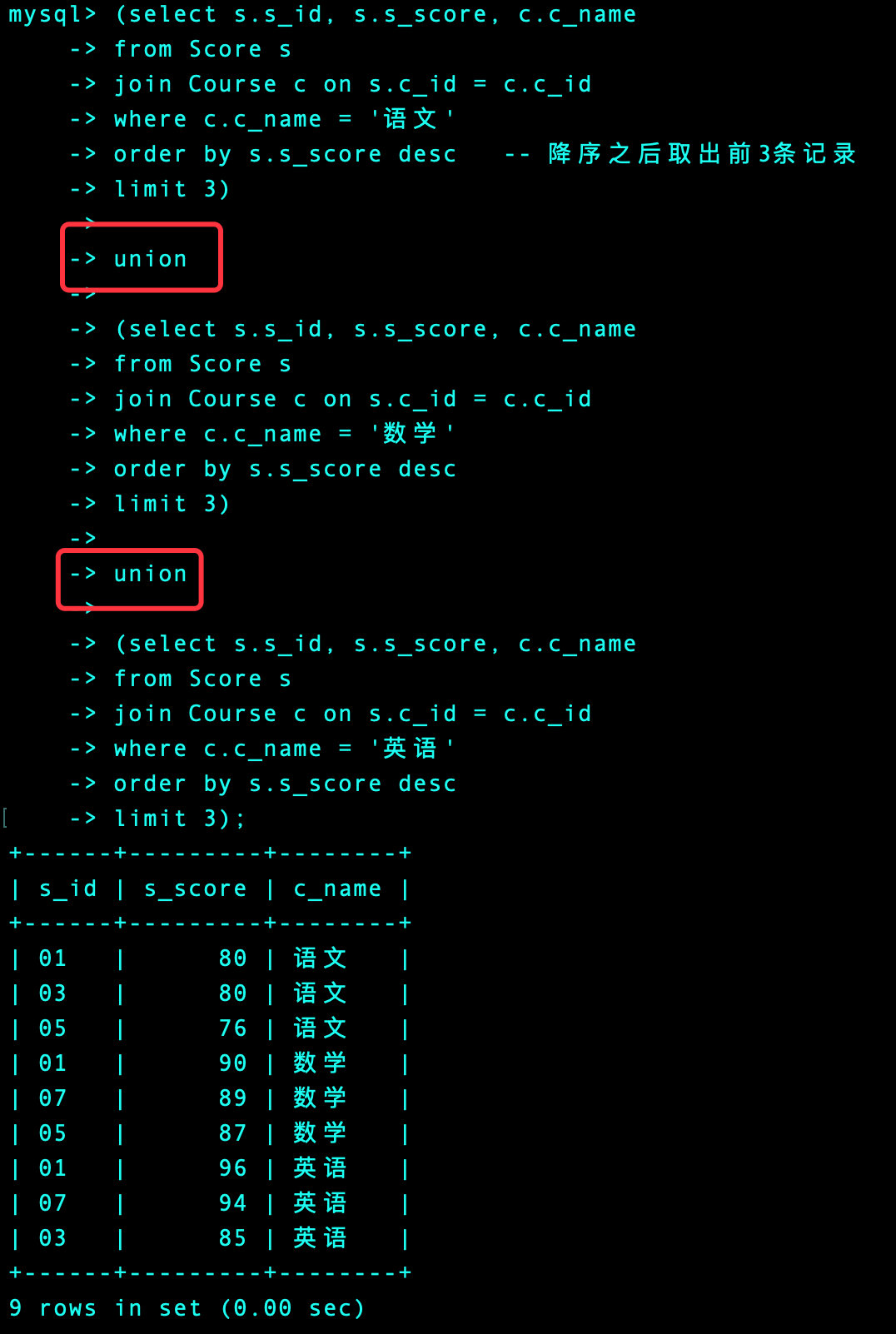
参考方法
通过Score表的自连接,表a中的值小于表b中的值,排序之后我们取前3
select
a.s_id
,a.c_id
,a.s_score -- 取出a中的成绩
from Score a
join Score b
on a.c_id = b.c_id
and a.s_score <= b.s_score -- 表b中的成绩大
group by 1,2,3
having count(b.s_id) = 3
order by 2, 3 desc;
我们通过语文这个科目来理解上面的代码:前3名是80,80,76
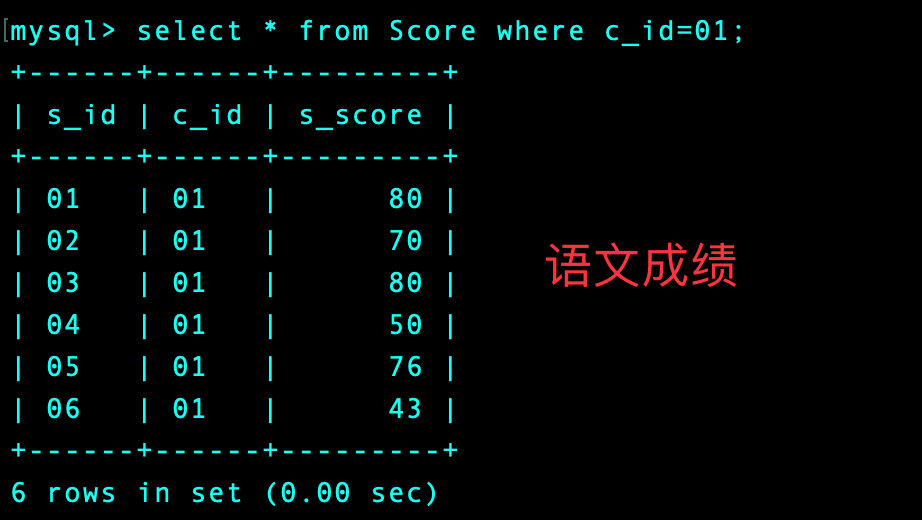
-- 语文
select
a.s_id
,a.c_id
,a.s_score -- 3、此时a表的成绩就是我们找的
from Score a
join Score b
on a.c_id = b.c_id
and a.s_score <= b.s_score -- 1、判断a的分数小于等于b的分数,要带上等号
and a.c_id="01"
group by 1,2
having count(b.s_id) <= 3 -- 2、b中的个数至少有3个,应对分数相同的情形
order by 3 desc;
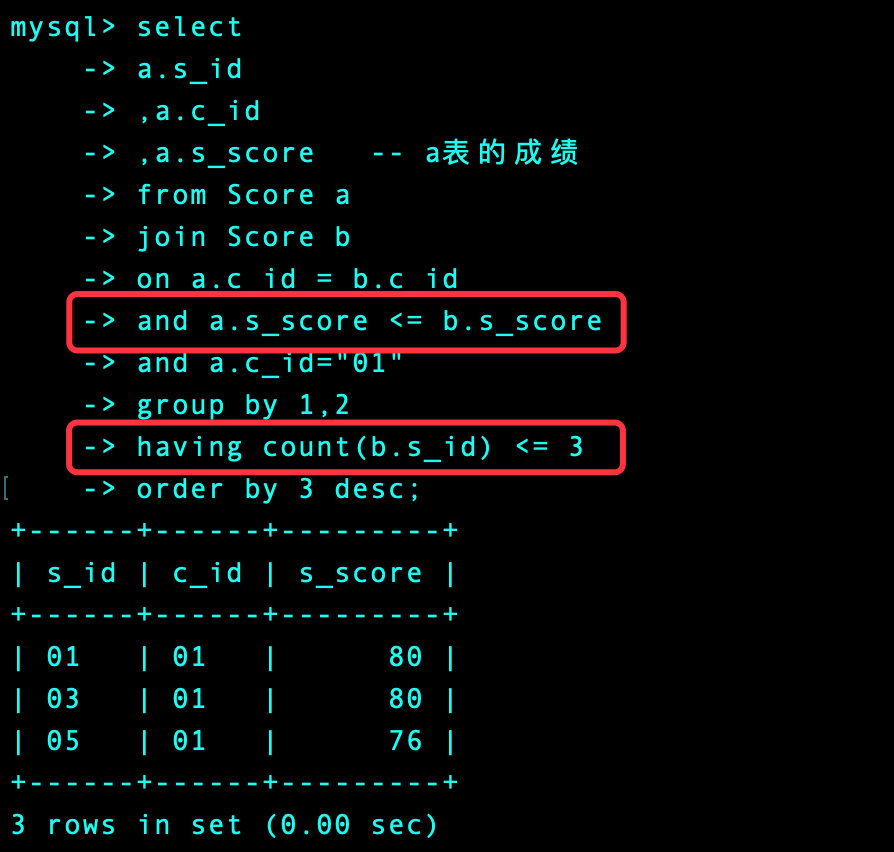
-- 语文
select
a.s_id
,a.c_id
,a.s_score -- a表的成绩
from Score a
join Score b
on a.c_id = b.c_id
and a.s_score <= b.s_score -- 1、判断a的分数小于等于b的分数,要带上等号
group by 1,2,3
having count(b.s_id) <= 3 -- 2、b中的个数至少有3个,应对分数相同的情形
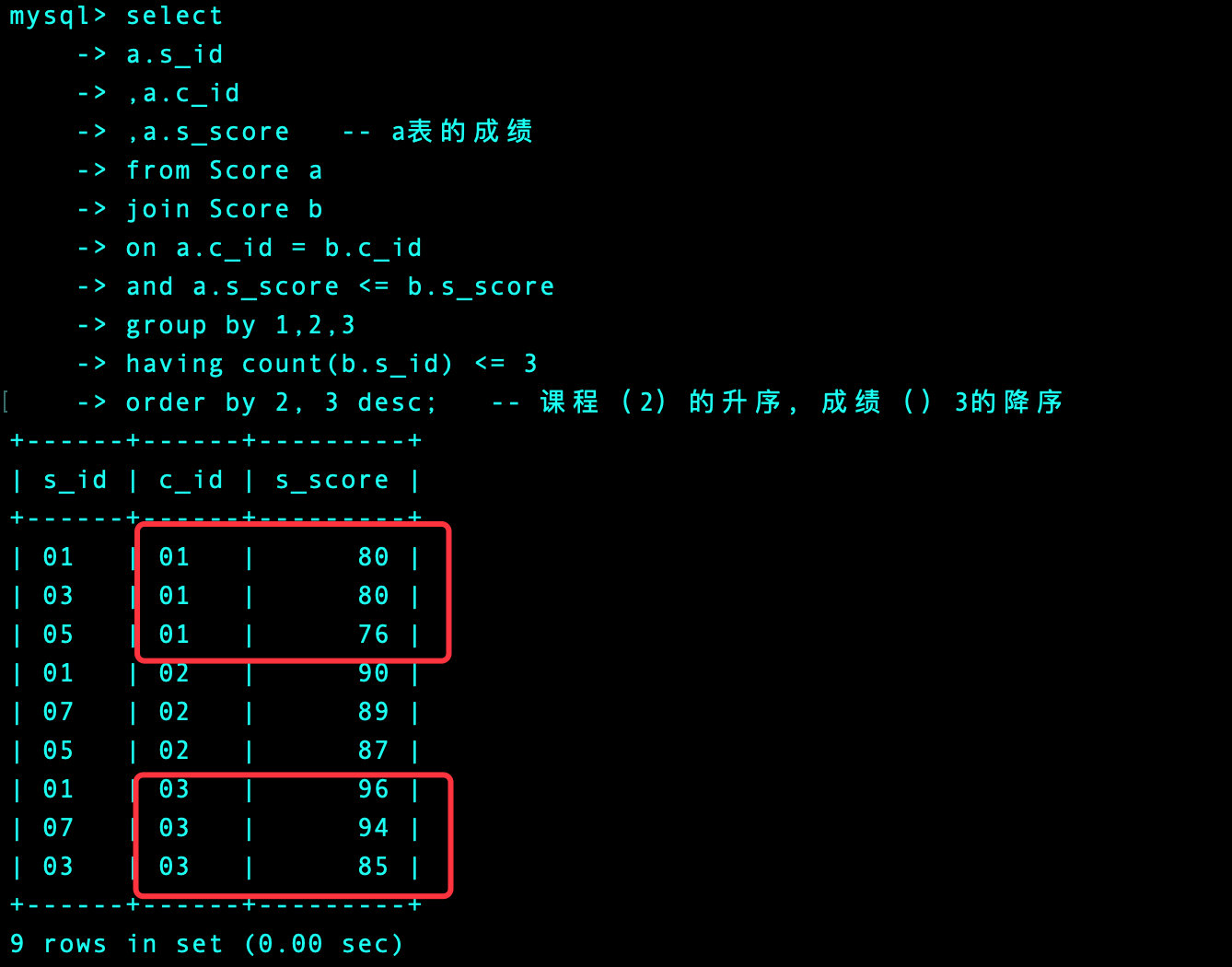
order by 2, 3 desc; -- 课程(2)的升序,成绩()3的降序

















 971
971

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









