







模型评估
-
precision、rescore、f1、auc、roc的评分表格,画出roc曲线
-
??那些是概率&结果(predict&predict_proba)
-
对于二分类问题:可以分为(0为正例,1为反例)——强调预测的结果和真实比较
- TP(true positive)真正例:真实为0,预测也0
- FP(false positive)假正例:真实为1,预测为0
- TN(true negative)真反例:真实为1,预测为1
- FN(false negative)假反例:真实为0,预测为1
-
TP + FP + TN + FN = 样例总数
-
分类结果的“混淆矩阵”(confusion matrix)

1.分类准确率(accuracy)
- 所有样本中被预测正确的比率
A c c u r a c y = T P + T N T P + F N + F P + T N Accuracy = \frac{TP+TN}{TP+FN+FP+TN} Accuracy=TP+FN+FP+TNTP+TN
from sklearn.metrics import accuracy_score
accuracy = accuracy_score(y_test, y_predict)
2.精准率(precision)_(查准率)
- 正确预测为正占全部预测为正的比例——针对预测结果
p r e c i s i o n = T P T P + F P precision = \frac{TP}{TP+FP} precision=TP+FPTP
from sklearn.metrics import precision_score
precision = precision_score(y_test, y_predict)
3.召回率(recall)_(查全率)
- 正确预测为正占全部正样本的比例——针对原始样本
- 有多少正样本被正确的预测出来了
r e c a l l = T P T P + F N recall = \frac{TP}{TP+FN} recall=TP+FNTP
from sklearn.metrics import recall_score
recall = recall_score(y_test, y_predict)
- 查全率和查准率是一对矛盾的度量
4.F1
- F1基于精准度和召回率的调和平均
1 F 1 = 1 2 ( 1 P + 1 R ) \frac{1}{F1} = \frac{1}{2}(\frac{1}{P}+\frac{1}{R}) F11=21(P1+R1)
F 1 = 2 ∗ P ∗ R P + R F1 = \frac{2*P*R}{P+R} F1=P+R2∗P∗R
from skearn.metrics import f1_score
F1 = f1.score(y_test, y_predict)
5.ROC(Receiver Operating Characteristic) 受试者工作特征
- ROC曲线
- 纵轴:真正例率(True Positive Rate)TPR
- 横轴:假正例率(False Position Rate)FPR
T P R = T P T P + F N ( 召 回 率 ) TPR = \frac{TP}{TP+FN}(召回率) TPR=TP+FNTP(召回率)
F P R = F P T N + F P FPR=\frac{FP}{TN+FP} FPR=TN+FPFP
6.AUC
- ROC曲线下的面积
7.代码绘制
from matplotlib import pyplot as plt
from sklearn.metrics import accuracy_score, recall_score, f1_score, roc_auc_score, roc_curve
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import StandardScaler
'''------------------------------------------
1 读取数据
----------------------------------------------'''
data = pd.read_csv('data_processed.csv',encoding='gbk')
'''-------------------------------------------
1.1 划分训练集何验证集
----------------------------------------------'''
train, test = train_test_split(data, test_size=0.1, random_state=666)
'''----------------------------------------
1.2 获取标签
-------------------------------------------'''
y_train = train.status
train.drop(['status'], axis=1, inplace=True)
y_test = test.status
test.drop(['status'], axis=1, inplace=True)
'''---------------------------------------------
1.3 数据标准化
-----------------------------------------------'''
scaler = StandardScaler()
train = pd.DataFrame(scaler.fit_transform(train),index=train.index, columns=test.columns)
test = pd.DataFrame(scaler.fit_transform(test),index=test.index, columns=test.columns)
'''----------------------------------------
1.4 训练模型
------------------------------------------'''
model = LogisticRegression(C=1, dual=True)
model.fit(train, y_train)
'''----------------
1.5 模型评价
----------------'''
y_predict = model.predict(test)
y_proba = model.predict_proba(test)[:,1]
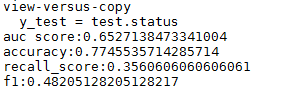
'''【AUC score】'''
print('auc score:{}'.format(roc_auc_score(y_test, y_predict)))
'''【准确率】'''
print('accuracy:{}'.format(accuracy_score(y_test, y_predict)))
'''【召回率】'''
print('recall_score:{}'.format(recall_score(y_test, y_predict)))
'''【f1】'''
print('f1:{}'.format(f1_score(y_test, y_predict)))
'''------------
1.6 绘制roc曲线
-----------'''
fpr, tpr, thresholds = roc_curve(y_test, y_proba)
plt.plot(fpr,tpr)
plt.plot([0, 1], [0, 1], 'k--')
- 结果:

参考:ROC与AUC的定义与使用详解















 1282
1282











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









