









前言
简单梳理下JVM运行原理,其实项目中有用到,但一直没有出现问题,所以没怎么了解过JVM运行机制。
JVM运行原理
过程图
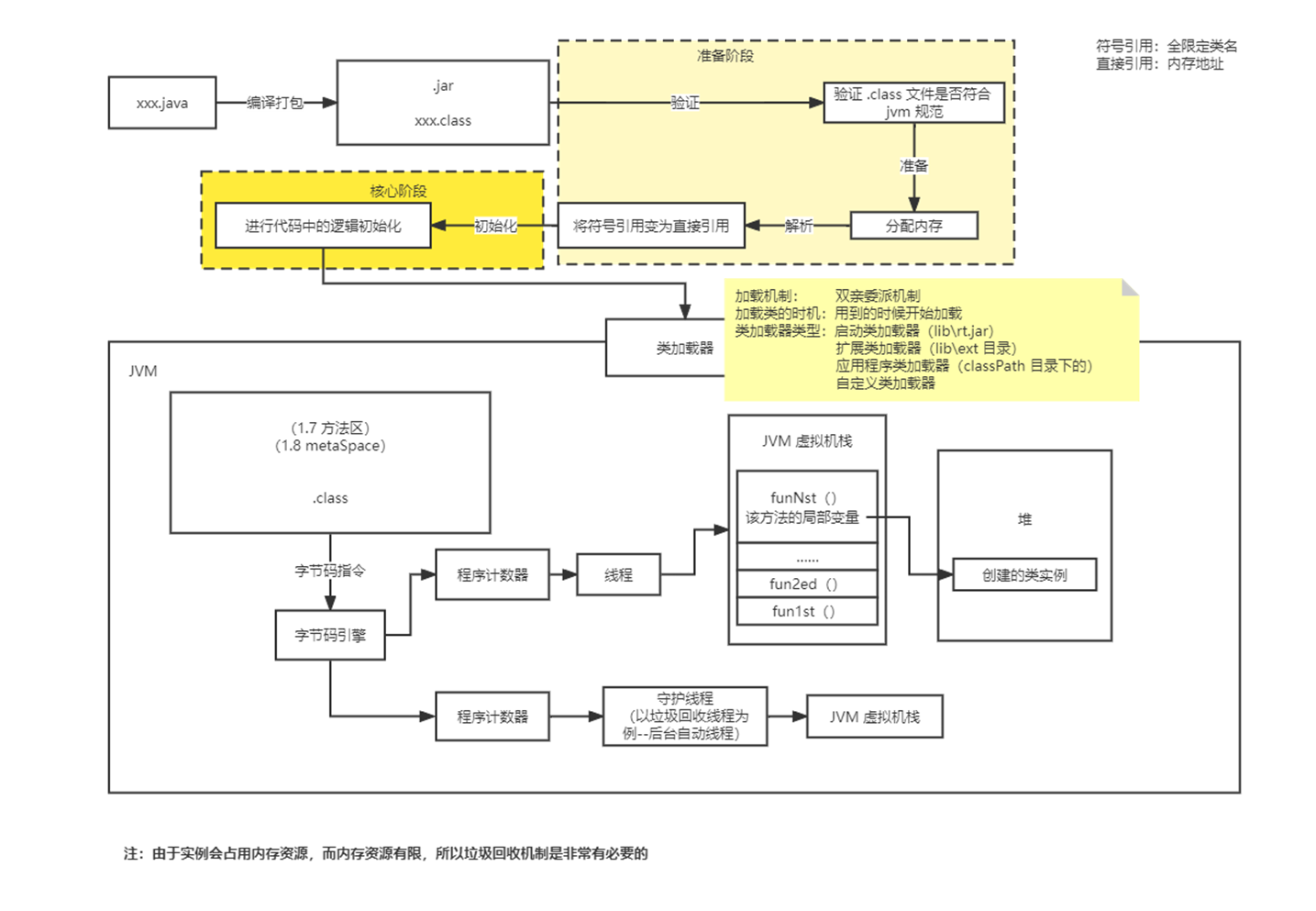
- 加载机制:双亲委派机制
- 加载类的方式:懒加载(使用时加载)
- 类加载器类型:
- 启动类加载器(lib\rt.jar)
- 扩展类加载器(lib\ext目录)
- 应用程序类加载器(classPath目录)
- 自定义类加载器
JVM内存调优参数
对应过程图的方法区、JVM虚拟机栈、JVM堆内存的参数调优
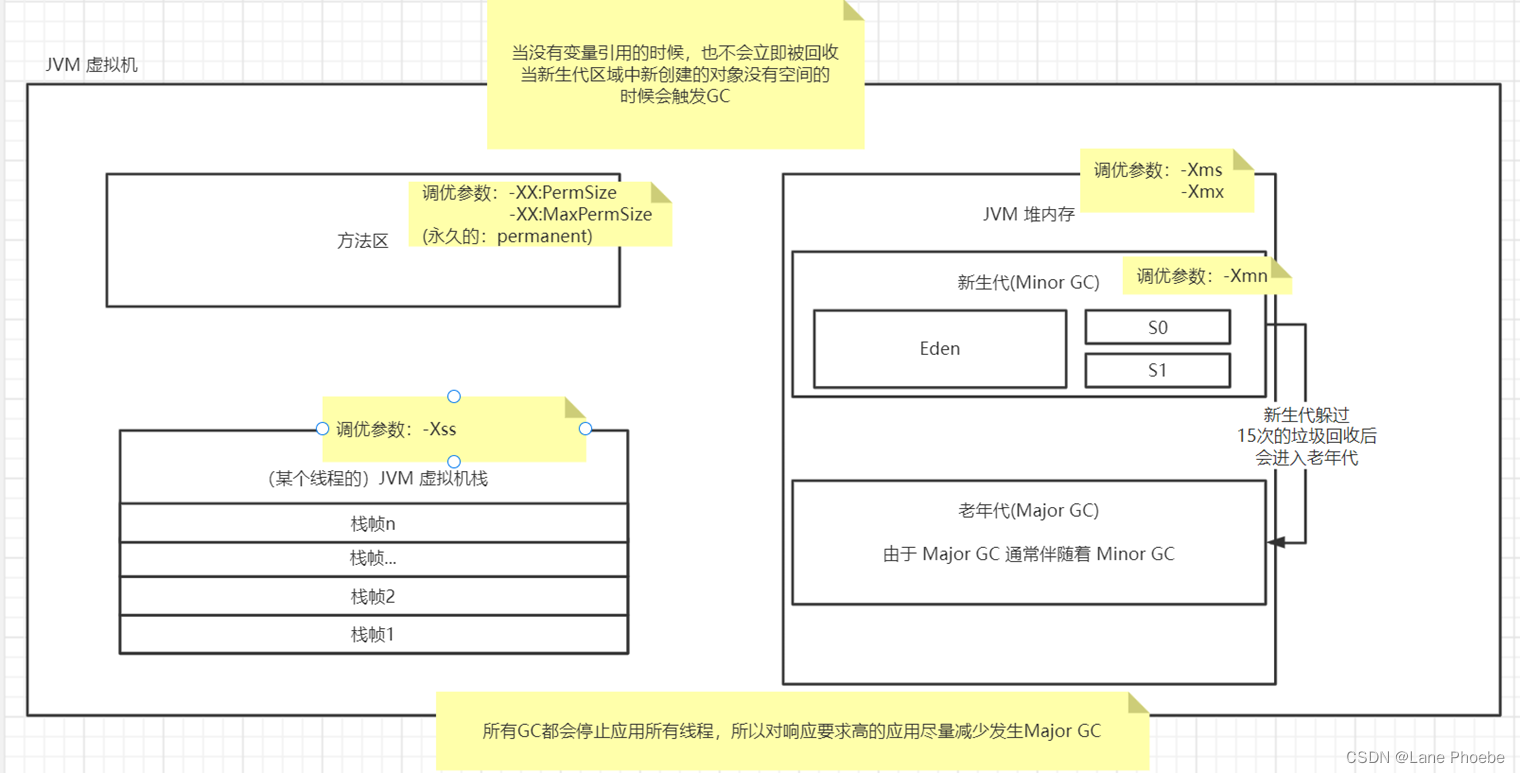
| 内存区域 | 调优参数 |
|---|---|
| 方法区 | -XX:PermSize -XX:MaxPermSize (永久的: permanent) |
| JVM堆内存 | -Xms -Xmx |
| 新生代(Minor GC)老年代(Major/Old GC) | -Xns -Xmn -XX:SurvivorRatio=8 (年轻代中Eden区与Survivor区的容量比例值,默认为8,即8:1) |
| JVM虚拟机栈 | -Xss |
内存大小设置
问:为什么需要对内存大小设置?
答:由于内存资源有限,所以需要垃圾回收机制。内存大小设置作用于垃圾回收
- 对垃圾回收区域的内存设置太小:可能造成垃圾回收过于频繁,轻者导致服务卡顿,重者导致服务崩溃,因为所有GC都会导致所有应用线程停止
- 如果对于垃圾回收区域的内存设置过大:可以保证当前服务的正常运行,但会对资源造成浪费,在同一台机器上的其他服务可分配到的内存资源减少
预估需要的内存大小(预算步骤)
- 计算单个对象大概需要的内存大小
- 计算服务处理每个请求需要耗时多久
- 计算服务处理每个请求大概需要多大内存
- 计算服务每秒需要处理多少请求
- 计算服务每秒处理请求需要占有多大内存
- 服务运行分析
- 对完整服务进行内存占用大小预估
计算单个对象大概需要的内存大小
>> 约3000B,即3KB
| 数据表 | 字段名 | 根据业务需求,计算单个对象大概需要的内存大小 |
|---|---|---|
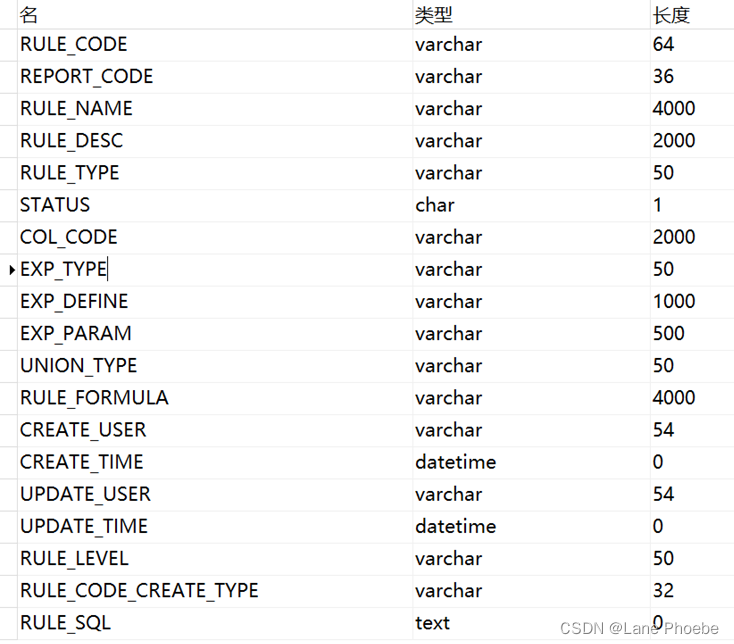 | RULE_CODE REPORT_CODE RULE_NAME RULE_DESC RULE_TYPE STATUS COL_CODE EXP_DEFINE EXP_PARAM UNION_TYPE RULE_FORMULA CREATE_USER CREATE_TIME UPDATE_USER UPDATE_TIME RULE_LEVEL RULE_CODE_CREATE_TYPE RULE_SQL | 30B 30B 200B 200B 3B 1B 20B 30B 20B 1B 300B 50B 8B 50B 8B 10B 1B 2000B |
计算服务处理每个请求需要耗时多久
每个查询请求的处理时间按170ms计算
计算服务处理每个请求大概需要多大内存
请求一页10条数据,不涉及复杂业务。一页10个对象,即3KB * 10
计算服务处理每个请求大概需要多大内存
由于业务是2B业务,因此每秒接受的请求量不是很大。一天产生10W个请求,日常工作时间8H,每秒3~4个请求
计算服务每秒处理请求需要占有多大内存
3*30KB ~ 4*40KB
服务运行分析
1s 产生的对象占空间是 KB 级别,但是每个请求结束,这些对象就没有人引用了,就成了新生代中 eden 区的垃圾。
下一秒请求过来,服务持续创建对象,eden 区中的对象会持续增加。直到某一个 eden 区被占满,触发 Minor GC,清除垃圾后,将非垃圾对象迁至 s0 区。
此时 eden 区腾出空间,可以继续在 eden 区分配新的对象。
对完整程序进行内存占用大小预估
前面的预估仅是基于一个小的对象来分析的,只是整个服务中很小的一部分,真实的运行情况,一定是每秒会创建大量的其他对象
所以预估的时候可以先按照扩大 10 - 20 倍的体量来预估是差不多的。
所以一秒按 120KB * 10 = 1200KB,约1MB。也就是每秒大约产生 1MB 的垃圾对象,循环多次后,新生代的 eden区满了,触发 GC。
JVM对内存的设置方法
一般线上用 2核4G 或者 4核8G。
经过上面的预算,一秒大约产生 1MB 左右的垃圾,如果新生代只分配 几百MB,几百秒后新生代就满了,就会触发 MinorGC。假设给 JVM 进程至少给 4G 以上,新生代就可以分配 2G,触发 Minor GC 的频率可以降低到0.5h-1h,因为任何 GC 都会导致应用线程的停用。所以低频率的触发 GC 一定比高频率触发 GC 好很多。
设置 -Xms 和 -Xmx 均为 3G,-Xns 和 -Xmn 均为 2G,即整个堆内存分配 3G,新生代分配 2G。
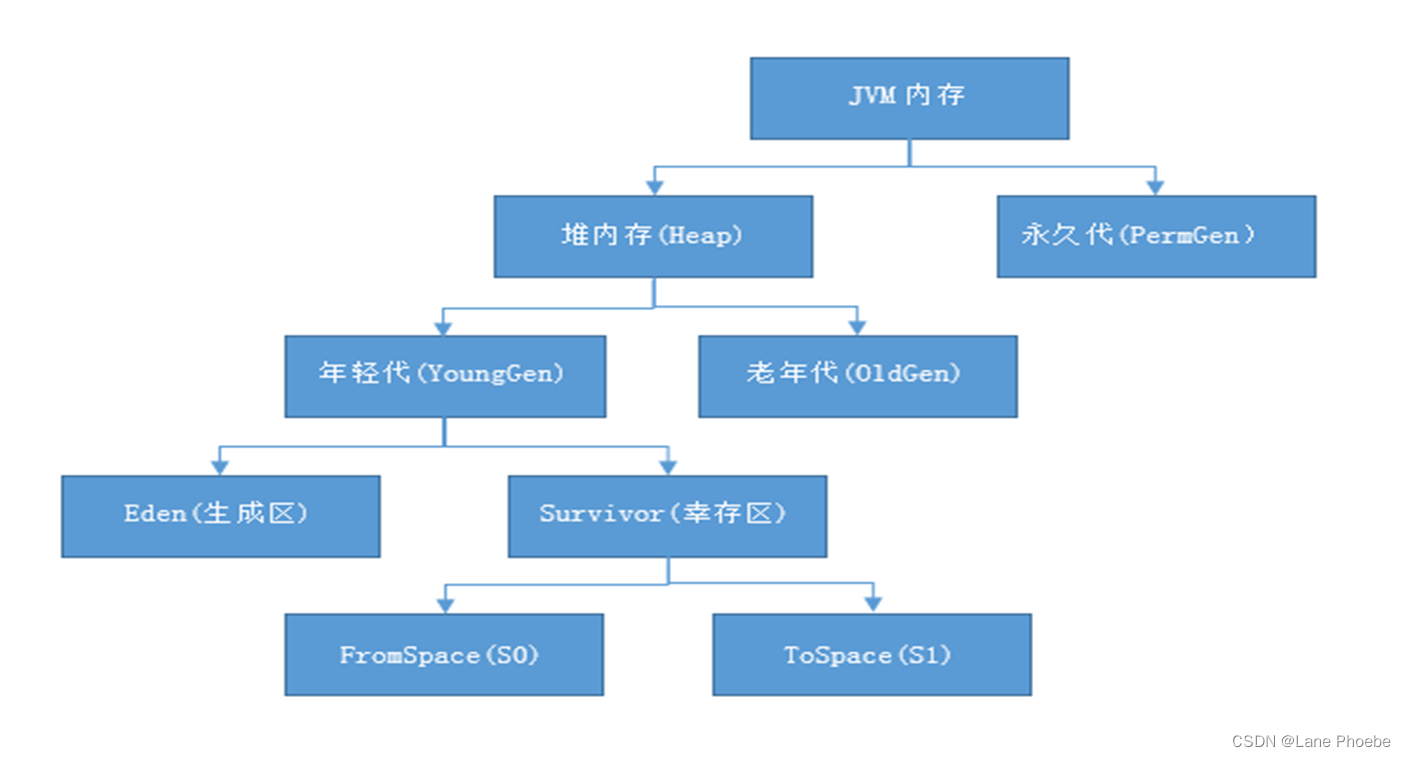
JVM内存分代模型
方法体中创建的实例对象,都会进入到java堆内存中
两个例子说明代码与内存加载模型对应关系
| 代码 | 虚拟机模型 |
|---|---|
 | 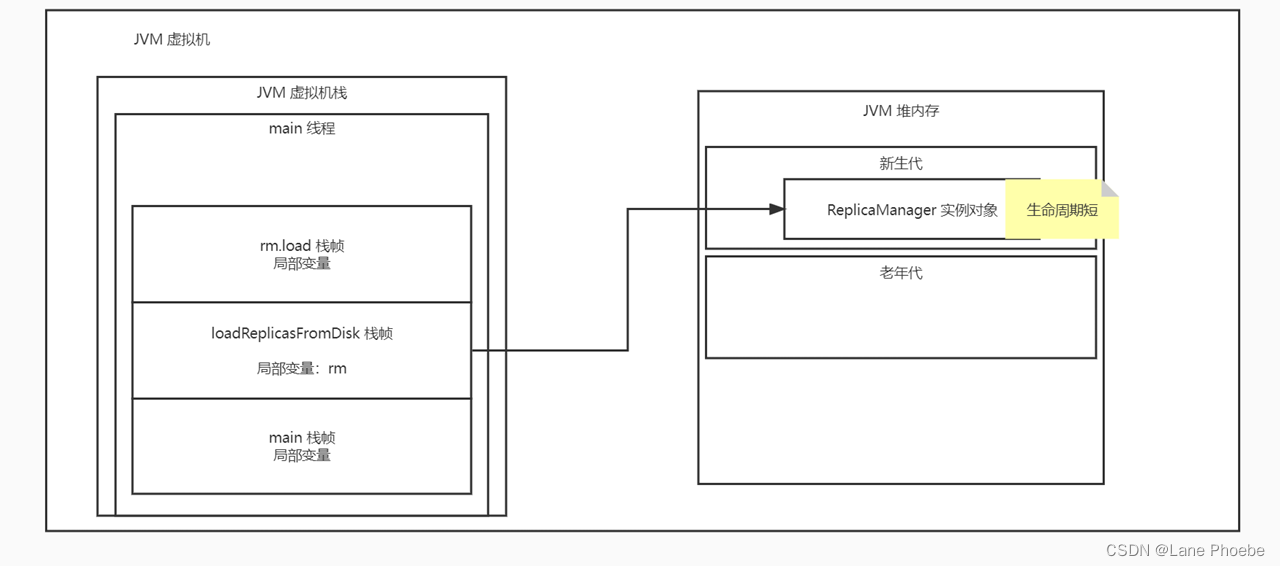 |
 | 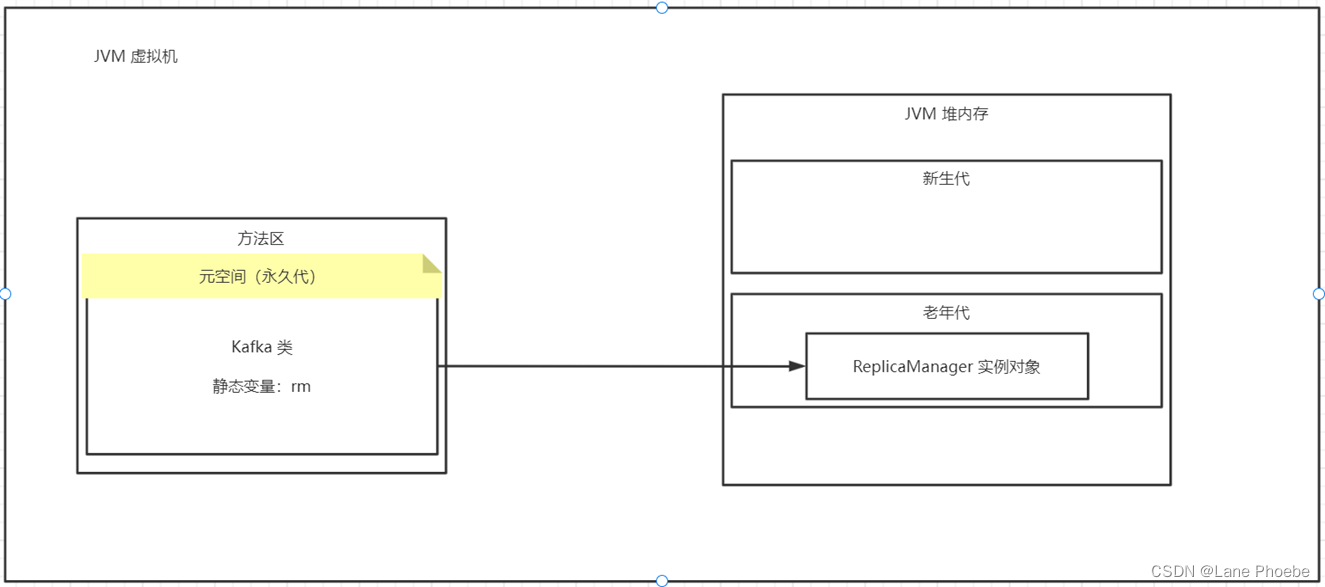 |
新生代流向老年代的情况(活动年龄算法)
- 躲过15次GC(小对象)
- 大量小对象,小对象超过一半内存
- 新生代发生minor GC 过大,直接进入老年代
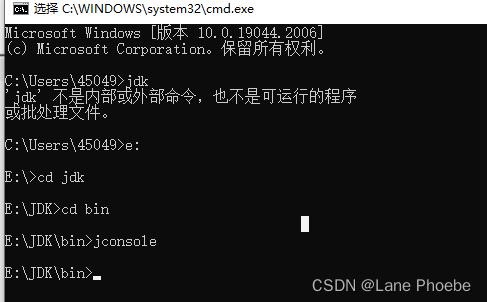
内存监控工具
在 jdk 的 bin 目录下执行命令:jconsole

垃圾回收器的选择
垃圾回收算法
- 复制 — 空间问题
- 标记-清除 — 碎片问题
- 标记-整理
垃圾回收器的选择

- Serial — 使用复制算法,进行垃圾收集时,必须暂停所有的工作线程,直到完成
- ParNew — 是Serial的多线程版本
- CMS(Concurrent Mark Sweep)收集器的执行过程。注:在初始标记与重新标记两个阶段,所有的应用线程都要暂停,在并发标记和并发清除两个阶段,虽然会耗费很多时间,但由于并发执行,所以对系统影响小
- 初始标记:标记GC Roots能直接关联到的对象,速度很快
- 并发标记:标记可回收对象,对所有的对象进行追踪,所以最耗时
- 重新标记:修正并发标记期间因程序继续运作导致标记变动的那一部分对象的标记记录
- 并发清除:会耗费很多时间
- G1(Garbage First)收集器
- 设计思想:将堆内训划分多个大小相等的独立区域(Region),并且能预测暂停时间,它能避免对整个堆进行全区收集。G1跟踪各个Region里的垃圾堆积价值大小(所获得空间大小以及回收所需时间),在后台维护一个优先列表,每次根据允许的收集时间,优先回收价值最大的Region,从而保证里在有限时间内获得最高的手机效率
- 执行过程
- 初始标记
- 并发标记
- 最终标记
- 筛选回收:对各个Region回收价值和成本进行排序,根据用户所期望的GC暂停时间来执行回收
- 适用场景及调优参数
- 实时数据占用超过一半的堆内存
- 对象分配或者晋升的速度变化大
- 希望消除长时间的GC停顿(超过0.5-1s)
- G1设置参数:
- -XX:+UseG1GC 启动GC
- -XX:G1HeadRegionSize=size
- -XX:MaxGCPauseMillis=200(默认200ms)
垃圾回收器的对比
| 垃圾回收器 | CMS收集器(Concurrent Mark Sweep) | G1收集器(Garbage First) |
|---|---|---|
| 设计目的 | 缩短暂停应用时间为目标 基于标记-清除算法实现 | 可预测垃圾回收使用时间 |
| 使用范围 | GMS是老年代收集器,可以配合新生代的ParNew收集器一起使用 | 新生代 + 老年代,不需要配合其他收集器 |
| 选择算法 | 标记-清除 | 标记-整理 |














 2309
2309











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









