




首先,这里已经假设读者已经了解TLD(tracking,learning,detection)是什么,故不做背景介绍,若还不知道这是什么,请自行百度稍微了解,把TLD的源码也下载下来,大概浏览一遍再来观看本系列文章。
本系列文章大概分为
1.算法框架与各部分(tracking,learning,detection)如何协同合作 2.目标在线模型的建立
3.tracking模块详解
4.detection模块详解
5.learning模块详解
本章导读: 这一篇主要讲程序框架和算法思路,我们先从整体上把握TLD算法,了解各部分模块如何通信,如何合作,当中会涉及每个模块的一些细节,若不明白,后面系列会有详细的介绍,本章目的应是从整体上把握该算法。
程序运行框架
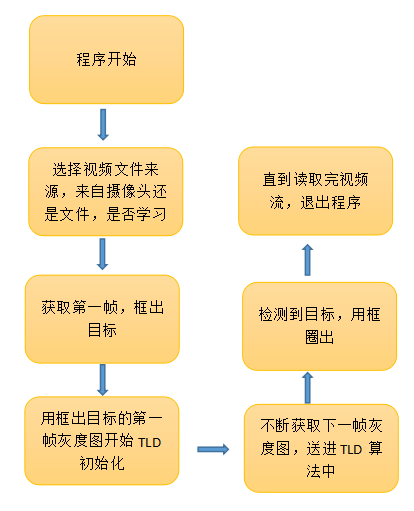
程序运行时是不断读取视频流的图片,转化为灰度图,最后交由TLD算法得出跟踪的目标,重复上述步骤。
接下来,我们就要讲解算法主要框架了。顾名思义,tracking,learning,detection有三个模块,我们可以简单理解为tracking是跟踪目标,detection通过learning学习到的在线模型进行目标预测,最后通过tracking和detection预测到的目标进行加权平均,最后确定到下一帧目标,最后learning模块学习训练在线模型。
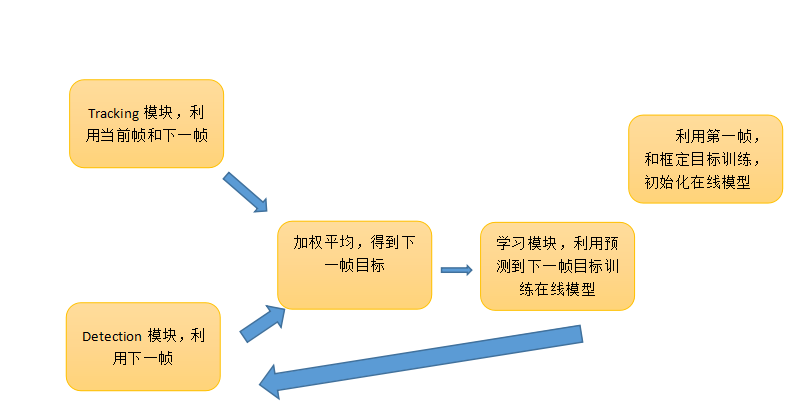
这里我们发现有一个初始化在线模型的操作,这里其实可以对应到程序运行框架里的TLD初始化,就是利用第一帧图片进行训练,得到初始的在线模型。那到底什么是在线模型呢?是如何训练的?tracking模块如何实现的?detection和在线模型之间的关系是什么?别急,里面内容太多了,接下来一步步讲解。
tracking模块是利用金字塔光流法和ncc(norm cross correlation)用当前帧预测下一帧目标。
1.先从当前帧目标均匀取10*10个点,记为n1。
2.利用这些点用光流法预测取下一帧对应的点n2,再用这些对应的点用光流法返回预测当前帧所在的点n3,n1和n3的距离就是FB_error
3.ncc是利用n1的每个点和n2每个点为中心提取10*10的像素矩阵,使用亚像素精度,两者进行计算互相关归一化模板匹配,得出相似值。
4.取大于ncc相似值中值和小于FB_error的n2点和对应的n1点,基于这些点计算原目标缩放和位移。

detection模块是一个三层的级联分类器(我喜欢叫做滤波器,把不适合的图像片去掉,剩余就是可能是目标的图像片)
第一层:方差分类器,若图像片(这里稍微解释一下,这个算法根据目标大小把一帧图像分割为很多不同尺寸的图像片,以后系列会有更详细介绍)的方差小于方差在线模型的一半,则认为这些是背景(认为目标方差比较大),丢弃这些图像片不要。
第二层:RandomFern分类器,利用RandomFern在线模型计算每个图像片的后验概率(这里稍微解释一下,训练时把图像片与在线模型重叠度大于0.6分为好的box,小于0.2坏的box,在每个图像片会产生13个点对,利用这些点对产生13位二进制码,在这上二进制码记为1,最后用好的box产生的每个二进制码出现次数/(好+坏),便得出每个不同二进制码的概率),若小于阈值,则可以丢弃这些图像片。
第三层:最近邻分类器,利用最近邻在线模型计算出图像片与在线模型的相关相似度,(具体计算方法,后面系列文章会谈到)。若相关相似度大于阈值,才能通过分类器,否则就被丢弃。
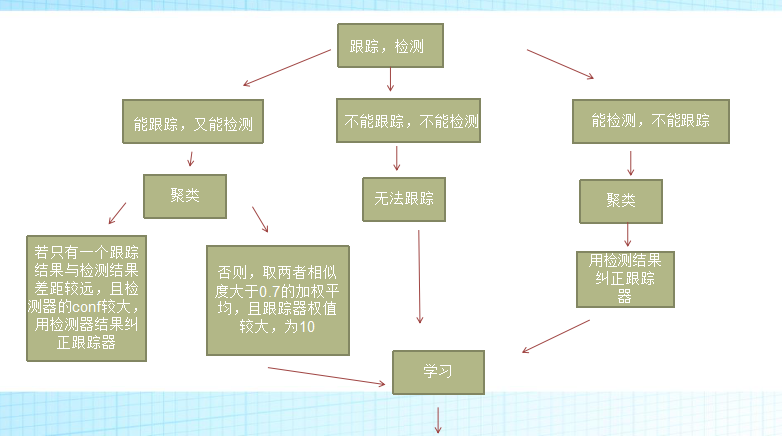
接下来,就是根据跟踪器和检测器预测下一帧目标所在位置了。
图片描述得很详细,就不加以文字描述了。

还有一个图助于理解
learning模块其实就是用预测到的下一帧目标来学习修正Randomfern在线模型和最近邻在线模型,当再到下一帧时,检测模块的检测都是基于最符合当前跟踪到的目标而检测的。至于如何学习修正,必须先了解一开始的建立模型的初始化工作,这留在下一章再解释。
http://ieeexplore.ieee.org/document/7984646/

















 783
783

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









