







最近在看coursera上的机器学习课程。总体感觉难度不大,应该是针对刚入门机器学习的初学者的。并且课程安排和作业的形式非常好,有截止日期的限制,所以学起来比较有动力。网上关于此课程的笔记很多也很全,所以我就按照自己觉得重要的部分进行了总结,并且加上额外搜集的知识点和自己的理解进行扩展。
导数


反映了某一点处沿x正方向的变化速率,几何上表示了该点切线的斜率。
偏导数
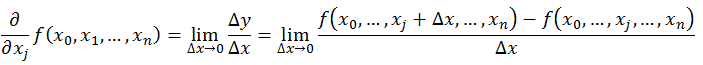
一元函数在X轴正方向上的变化率可以用导数表示,多元函数有多个自变量,在讨论其中一个方向的变化率而其他方向不变的时候,可以用偏导数表示。
方向导数
在函数图像上取一点P(x_p,yp),其在邻域内有定义,从P点任意引一射线l,并设P'(x+△x,+△)为射线上的一点,P‘也在邻域有定义。考虑函数的增量与P和P’之间的距离的比值的极限,若存在,则称此极限为函数在P点沿l方向的方向导数。
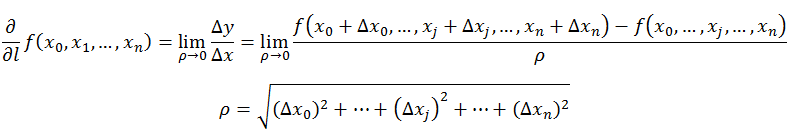
梯度
梯度定义为当函数某一点存在一阶连续偏导数的时候,其各个轴正方向上的变化率(该点沿某轴的偏导数)乘以某轴对应的单位向量的和,是一组向量。以z=f(x,y)为例:在该点如上文所述,做一条射线l,射线l方向的单位向量为e,则该点沿此方向的方向导数可求。推导公式可得此方向函数为梯度和e这两个向量的乘积,可以表示为梯度的模乘以cos(梯度方向和e的夹角)。当梯度方向和e的方向一致,此方向函数最大。
所以沿梯度方向的方向导数达到最大值,也就是说,梯度的方向是函数在这点增长最快的方向。

损失函数(cost function)
通过Hypothesis和实际得到数据的方差来衡量Hypothesis的准确性。一共有m个样本,所以方差除以了m。为了便于在求梯度的时候,使方差函数的导数项抵消,所以乘以了1/2。以只有一个自变量的函数的Hypothesis为例:
则损失函数为:

梯度下降
是一种迭代方法。求解损失函数的最小值时,可以通过梯度下降法来一步步的迭代求解,得到最小化的损失函数和模型参数值。在机器学习中,基于基本的梯度下降法发展了两种梯度下降方法,分别为随机梯度下降法和批量(Batch)梯度下降法(即每一次迭代都要用所有的训练集样本)。用这种方法,沿着梯度下降的方向,逐步跌代损失函数中的参数,使Hypothesis得到的结果逼近损失函数的极小值。(注意:需要同步更新)
想象损失函数J(θ0,θ1)是一个有坡度的面,整个坐标系有三个轴,两个自变量θ0和θ1。从某一点(θ0,θ1)出发,用原来的两个轴的坐标值减去步长a乘以这两个轴方向的偏导数,相当于把这个点逐步向这个面的最低点挪动。直到θ0:=θ0−α∗0和θ1:=θ1−α∗0,即两个方向上的偏方差都为0了,那么说明已经到了convergence,停止更新这点的位置,这个点坐标对应的θ0和θ1就是Hypothesis中需要求的参数。然后可以用这个模型根据任意自变量预测因变量。但是如果步长过小,梯度下降会很慢,步长过大,则不会收敛或者会有误差。



参考
http://netedu.xauat.edu.cn/jpkc/netedu/jpkc/gdsx/homepage/5jxsd/51/513/5308/530807.htm
http://blog.csdn.net/walilk/article/details/50978864















 2450
2450











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









