







Merge k sorted linked lists and return it as one sorted list. Analyze and describe its complexity.
Example:
Input:
[
1->4->5,
1->3->4,
2->6
]
Output: 1->1->2->3->4->4->5->6方法一: Brute Force
Intuition & Algorithm
- Traverse all the linked lists and collect the values of the nodes into an array.
- Sort and iterate over this array to get the proper value of nodes.
- Create a new sorted linked list and extend it with the new nodes
Complexity Analysis
-
Time complexity : O(NlogN) where N is the total number of nodes.
- Collecting all the values costs O(N) time.
- A stable sorting algorithm costs O(NlogN) time.
- Iterating for creating the linked list costs O(N) time.
-
Space complexity : O(N).
- Sorting cost O(N) space (depends on the algorithm you choose).
- Creating a new linked list costs O(N) space.
方法二:Compare one by one
Algorithm
- Compare every k nodes (head of every linked list) and get the node with the smallest value.
- Extend the final sorted linked list with the selected nodes.
Complexity Analysis
-
Time complexity : O(kN) where k is the number of linked lists.
- Almost every selection of node in final linked costs O(k) (k-1 times comparison).
- There are N nodes in the final linked list.
-
Space complexity :
- O(n) Creating a new linked list costs O(n) space.
- O(1) It's not hard to apply in-place method - connect selected nodes instead of creating new nodes to fill the new linked list.
自己想的一个比较直观的方法是,创建一个vector<bool>用来记录lists中的相应位置的链表是否都已经被链接进结果链表中,如果是则设为true,否则为false。然后每一次while循环均将当前还未链接完的所有链表中最小的那个头结点链接入结果链表中。
class Solution {
public:
ListNode * mergeKLists(vector<ListNode*>& lists) {
auto list_size = lists.size();
vector<bool> record(list_size, false); //当相应链表还未被完全链接到结果链表时,其对应的值为false。否则为true
for (int i = 0; i < list_size; ++i) {
if (lists[i] == nullptr) {
record[i] = true;
}
}
ListNode *head = nullptr, *now = nullptr;
while ( needContinue(record) ) {
int List_number = FindMinNumber(lists, record);
if (head == nullptr) {
head = lists.at(List_number);
now = head;
if (lists.at(List_number)->next == nullptr) {
//该链表已被全部链入
record[List_number] = true;
}
else {
lists.at(List_number) = lists.at(List_number)->next;
}
}
else {
now->next = lists.at(List_number);
now = now->next;
if (lists.at(List_number)->next == nullptr) {
//该链表已被全部链入
record[List_number] = true;
}
else {
lists.at(List_number) = lists.at(List_number)->next;
}
}
}
return head;
}
//是否还有链表未完全处理完
bool needContinue(vector<bool> &record) {
for (auto temp : record) {
if (temp == false) {
//还有链表未全部处理
return true;
}
}
return false;
}
//找到lists中所有链表中首节点最小的那个链表在vector中的序号
int FindMinNumber(vector<ListNode*>& lists,vector<bool>& record) {
int res = -1;
for (int i = 0; i < lists.size(); ++i) {
if (record.at(i) == true)
continue;
if (res == -1) {
res = i;
}
else {
if (lists.at(i)->val < lists.at(res)->val) {
res = i;
}
}
}
return res;
}
};方法三:Optimize Approach 2 by Priority Queue
Algorithm
Almost the same as the one above but optimize the comparison process by priority queue.
参考:
struct compare {
bool operator()(const ListNode* l, const ListNode* r) {
return l->val > r->val;
//表达式comp(a,b),如果a被认为是在函数定义的严格弱排序中的b之前(即b的优先级更高),则返回true。
}
};
ListNode *mergeKLists(vector<ListNode *> &lists) { //priority_queue
priority_queue<ListNode *, vector<ListNode *>, compare> q;
for(auto l : lists) {
if(l) q.push(l);
}
if(q.empty()) return NULL;
ListNode* result = q.top();
q.pop();
if(result->next) q.push(result->next);
ListNode* tail = result;
while(!q.empty()) {
tail->next = q.top();
q.pop();
tail = tail->next;
if(tail->next) q.push(tail->next);
}
return result;
}Complexity Analysis
-
Time complexity : O(Nlogk) where k is the number of linked lists.
- The comparison cost will be reduced to O(logk) for every pop and insertion to priority queue. But finding the node with the smallest value just costs O(1) time.
- There are N nodes in the final linked list.
-
Space complexity :
- O(n) Creating a new linked list costs O(n) space.
- O(k) The code above present applies in-place method which cost O(1) space. And the priority queue (often implemented with heaps) costs O(k) space (it's far less than N in most situations).
Difference between Priority-Queue and Heap
Concept:
1.Heap is a kind of data structure. It is a name for a particular way of storing data that makes certain operations very efficient. We can use a tree or array to describe it.
18
/ \
10 16
/ \ / \
9 5 8 12
18, 10, 16, 9, 5, 8, 12
2.Priority queue is an abstract datatype. It is a shorthand way of describing a particular interface and behavior, and says nothing about the underlying implementation.
A heap is a very good data structure to implement a priority queue. The operations which are made efficient by the heap data structure are the operations that the priority queue interface needs.
Implementation: c++
1.priority_queue: we can only get the top element (具体实现即方法三的代码)
2.make_heap: we can access all the elements(具体实现如下)
static bool heapComp(ListNode* a, ListNode* b) {
return a->val > b->val;
}
ListNode* mergeKLists(vector<ListNode*>& lists) { //make_heap
ListNode head(0);
ListNode *curNode = &head;
vector<ListNode*> v;
for(int i =0; i<lists.size(); i++){
if(lists[i]) v.push_back(lists[i]);
}
make_heap(v.begin(), v.end(), heapComp); //vector -> heap data strcture
while(v.size()>0){
curNode->next=v.front();
pop_heap(v.begin(), v.end(), heapComp);
v.pop_back();
curNode = curNode->next;
if(curNode->next) {
v.push_back(curNode->next);
push_heap(v.begin(), v.end(), heapComp);
}
}
return head.next;
}方法四: Merge lists one by one
Algorithm
Convert merge k lists problem to merge 2 lists (k-1) times. Here is the merge 2 lists problem page.
ListNode *mergeKLists(vector<ListNode *> &lists) {
if(lists.empty()){
return nullptr;
}
while(lists.size() > 1){
lists.push_back(mergeTwoLists(lists[0], lists[1]));
lists.erase(lists.begin());
lists.erase(lists.begin());
}
return lists.front();
}
/*
*第一次进入if(l1->val < l2->val) 判断的时候的return即为最终返回的头结点。这个函数的目的是返回
*当前两个参数中val值较小的那个节点指针,并令这个指针指向下一个val值最小的节点。当两个参数中有一
*个为nul时,直接将另一个参数剩余的所有链表直接连接在要返回的链表后面。
*/
ListNode *mergeTwoLists(ListNode *l1, ListNode *l2) {
if(l1 == nullptr){
return l2;
}
if(l2 == nullptr){
return l1;
}
if(l1->val <= l2->val){
l1->next = mergeTwoLists(l1->next, l2);
return l1;
}
else{
l2->next = mergeTwoLists(l1, l2->next);
return l2;
}
}Complexity Analysis
-
Time complexity : O(kN) where k is the number of linked lists.
- We can merge two sorted linked list in O(n) time where n is the total number of nodes in two lists.
- Sum up the merge process and we can get:
-
Space complexity : O(1)
- We can merge two sorted linked list in O(1) space.
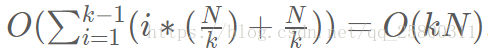
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
ListNode* mergeKLists(vector<ListNode*>& lists) {
if(lists.empty()) return nullptr;
if(lists.size()==1) return lists.at(0);
ListNode *resP = lists.at(0);
for(int i=1; i<lists.size(); ++i){
resP = mergeTwoLists(resP, lists.at(i));
}
return resP;
}
ListNode* mergeTwoLists(ListNode* head1, ListNode* head2){
if(head1==nullptr && head2==nullptr) return nullptr;
else if(head1==nullptr && head2!=nullptr) return head2;
else if (head1 != nullptr && head2 == nullptr) return head1;
ListNode *p1 = head1;
ListNode *p2 = head2;
ListNode *resP = nullptr;
ListNode *p3 = nullptr;
if(p1->val <= p2->val){
p3 = p1;
resP = p1;
p1 = p1->next;
}else{
p3 = p2;
resP = p2;
p2 = p2->next;
}
while(p1!=nullptr && p2!=nullptr){
if(p1->val <= p2->val){
p3->next = p1;
p3 = p3->next; //注意别掉了这一句
p1 = p1->next;
}else{
p3->next = p2;
p3 = p3->next; //注意别掉了这一句
p2 = p2->next;
}
}
if(p1!=nullptr){
p3->next = p1;
}else{
p3->next = p2;
}
return resP;
}
};方法五:分治法
Intuition & Algorithm
This approach walks alongside the one above but is improved a lot. We don't need to traverse most nodes many times repeatedly
-
Pair up k lists and merge each pair.
-
After the first pairing, k lists are merged into k/2 lists with average 2N/k length, then k/4, k/8 and so on.
-
Repeat this procedure until we get the final sorted linked list.
Thus, we'll traverse almost NN nodes per pairing and merging, and repeat this procedure about log2k times.
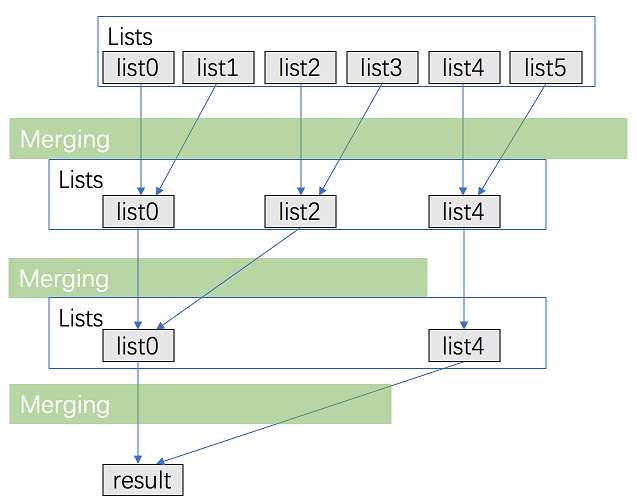
for each level, the total comparison is N, there are log K levels. so the runtime is O(N log K).
for the first level, as you said, we merge K/2 lists. but every list only has N/K length. for second level, we merge K/4 lists with 2N/K length. so on and so forth.
ListNode* mergeKLists(vector<ListNode*>& lists) {
int k = (int)lists.size();
if(k==0) return NULL;
if(k==1) return lists[0];
return doMerge(lists, 0, (int)lists.size()-1);
}
ListNode* doMerge(vector<ListNode*>& lists, int left, int right) {
if(left==right) return lists[left];
else if(left+1==right) return merge2Lists(lists[left], lists[right]);
ListNode* l1 = doMerge(lists, left, (left+right)/2);
ListNode* l2 = doMerge(lists, (left+right)/2+1, right);
return merge2Lists(l1, l2);
}
/*
*第一次进入if(l1->val < l2->val) 判断的时候的return即为最终返回的头结点。这个函数的目的是返回
*当前两个参数中val值较小的那个节点指针,并令这个指针指向下一个val值最小的节点。当两个参数中有一
*个为nul时,直接将另一个参数剩余的所有链表直接连接在要返回的链表后面。
*/
ListNode *merge2Lists(ListNode *l1, ListNode *l2) {
if(l1 == nullptr){
return l2;
}
if(l2 == nullptr){
return l1;
}
if(l1->val <= l2->val){
l1->next = merge2Lists(l1->next, l2);
return l1;
}
else{
l2->next = merge2Lists(l1, l2->next);
return l2;
}
}














 588
588











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









