






https://createmomo.github.io/2017/09/12/CRF_Layer_on_the_Top_of_BiLSTM_1/
概览
- 介绍 在NER任务中,BiLSTM后接的CRF层
- 详细解释CRF层运作step-by-step
- 使用chainer完成一个CRF层
知识储备
只需要了解什么是NER即可(通俗地说,只要是用户想要了解的实体,即可以认为是实体识别)。在文中将会提到CRF以及任何相关的知识。BiLSTM和CRF是在NER中的两个不同的层。
before start
假定有两个实体类型,Person和Organization。这样我们就需要5个标签来表示,分别为B-Person, I-Person, B-Organization, I-Organization, O。
假定有5个单词,w0 w1, w2, w3, w4, w5 ,并假设[w1,w2]是Person,[w3]是Organization,其他为O。
BiLSTM-CRF 模型
- 首先,句子中的每个单词 wi 一个向量,这个向量的形式可以是character级别的embedding,也可以是word级别的embedding。前者是随机初始化的,后者通常是一个预训练的word-embeding。这些embedding会在训练的过程中进行微调。
- 第二,BiLSTM-CRF的输入是刚刚提到的embedding向量;输出是句子预测出来的label。就是figure1.1中最上方的B-Person, I-Person等五个。
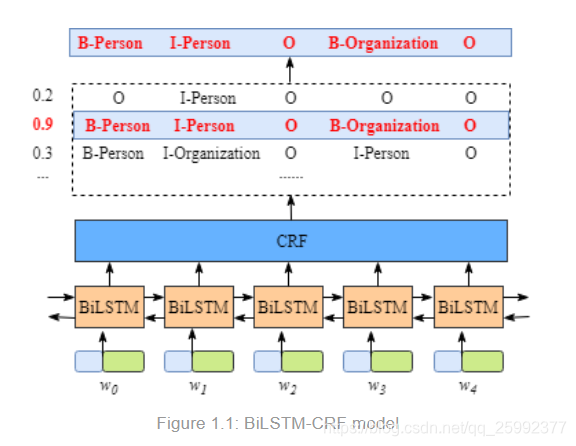
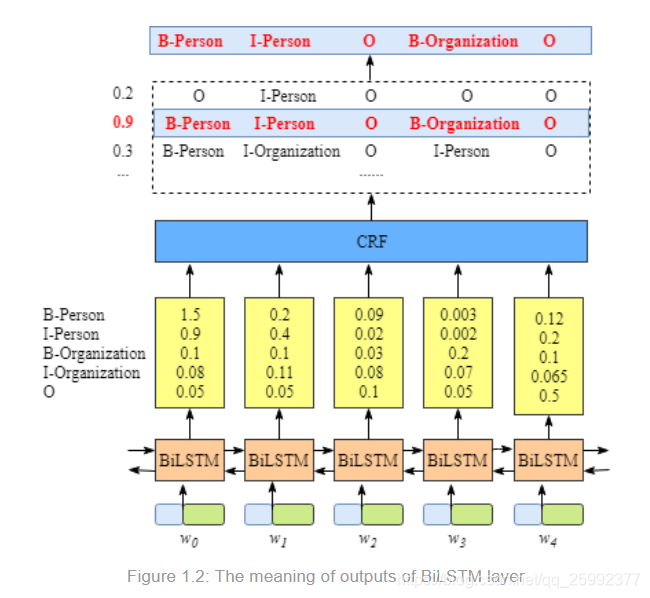
暂时不需要了解BiLSTM内部是如果运作的,只需要知道BiLSTM输出的内容是每一个标签的分数。例如对于,w0 来说,BiLSTM在这个单词上的输出为[1.5,0.9,0.1,0.08,0.05],这些分数将会成为CRF的输入。将所有的label的分数都送入CRF层中,在CRF层中将会以某种方式取出具有最高的预测分值的一个序列作为最佳标签序列。
CRF的优点
如果不使用CRF,如下图所示,仅仅对每个标签进行最大分值对应的label选取。在figure1.3和1.4上,只有在1.3的情况下,通过这种方法是正确的,而在1.4的情况下,将会得到错误的序列标签(这里的方法应该就是单纯的使用了softmax)。
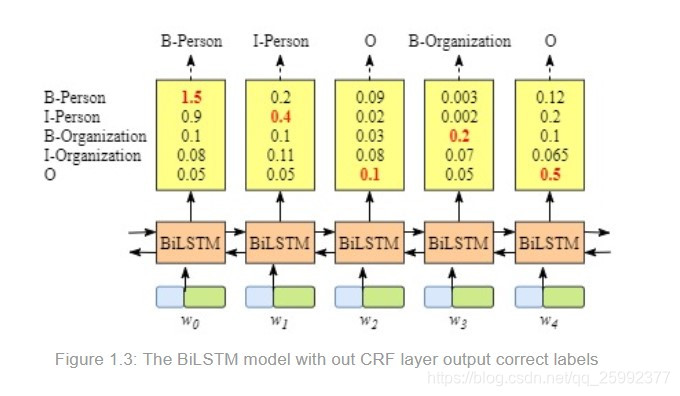
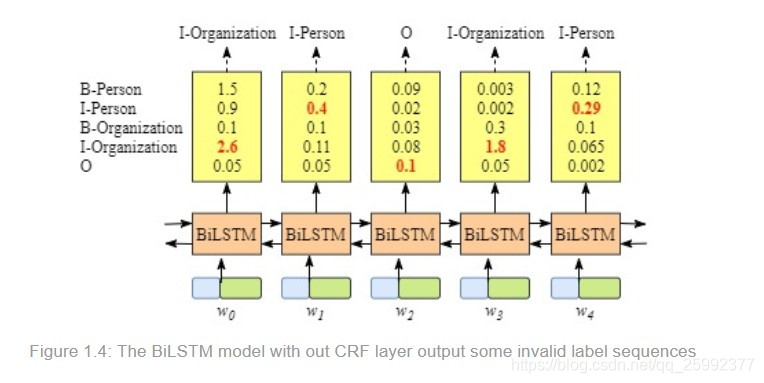
CRF层其实会对标签及BiLSM进入其的输入做一些限制,通过训练可以优化这些参数,从而进行预测。
这些限制包括:
- 一句话的起始位置应该是B-或者O-,而不会是I-
- B-label1 I-label2 I-label3是合法的,而B-Person I-Organization是非法的。
- O I-label1是非法的,I-label1不可以作为一个区块中的开始,需要是 O, B-label1
next
接下来会讲到CRF loss,这个loss函数是如何通过训练数据学习这些标签限制的。
翻译大概花费了(30-40分钟)















 1600
1600











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









