






https://createmomo.github.io/2017/10/08/CRF-Layer-on-the-Top-of-BiLSTM-3/
CRFloss由真实标签序列分数和所有可能标签序列的分值组成。真实标签序列的分数在所有可能的标签序列中,应当是得分最高的一个。
如下图所示,假设一个句子由5个单词组成,这个句子的所有标签序列的可能结果有N个,第i个标签序列的分值为p(i)。

那么总分值如下(这个公式在徐义达的HMM课程中有讲):
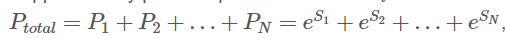
假定第10个标签序列是真实的标签序列,该标签序列是由我们的训练集提供的(好像由负采样的影子啊)
CRF的loss函数如下:训练的目标是提高P(realpath)的比重。
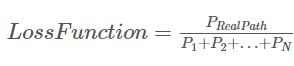
那么问题来了:
- 如何定义一个序列标签的分数呢,即S(i)
- 怎么样计算P(total)。从上面公式中可以看出,是求了e的S(i)次幂.
- 当计算出P(total)时,我们需要列出所有的可能的标签序列嘛?并不需要
next
- 如何计算一个句子的真实标签序列的分值。
- 如何计算一个句子所有可能的标签序列的分值的综合。















 343
343











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









