









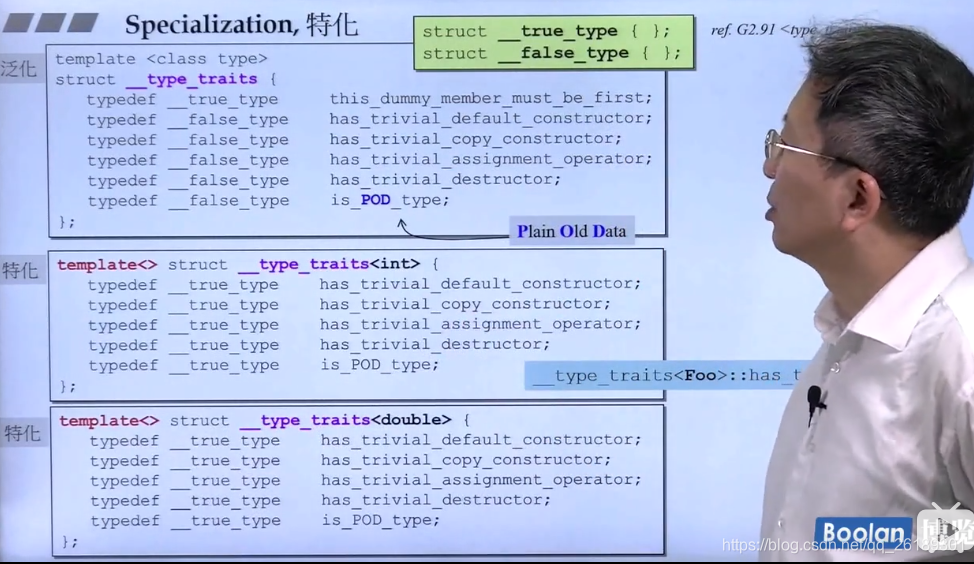
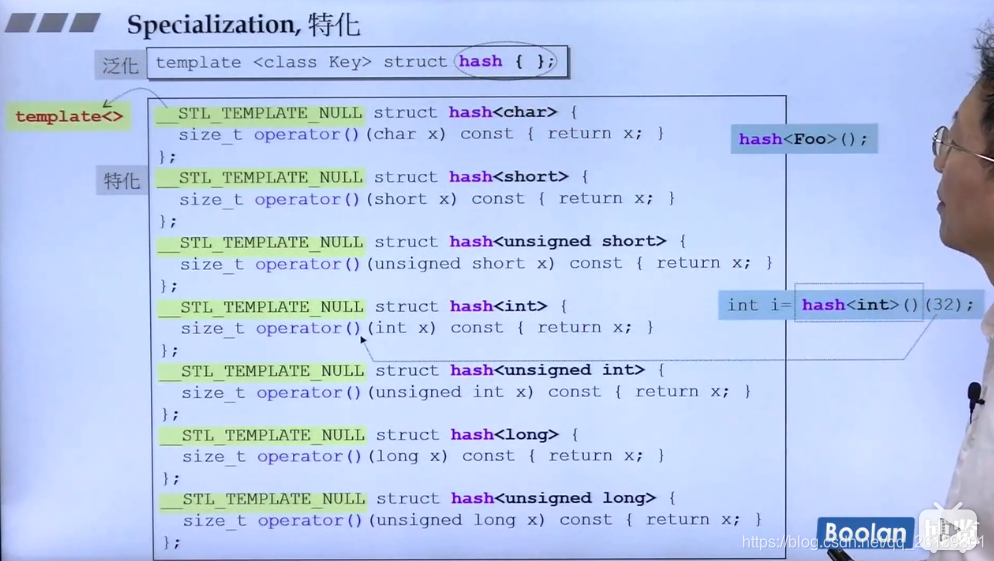
template<>出现,就表示要特化了

为什么要特化呢?泛化不就是为了解决数据类型不一致吗?
泛化是通用,特化是优化,缺一不可
特化,又被成为全特化 full-specialization
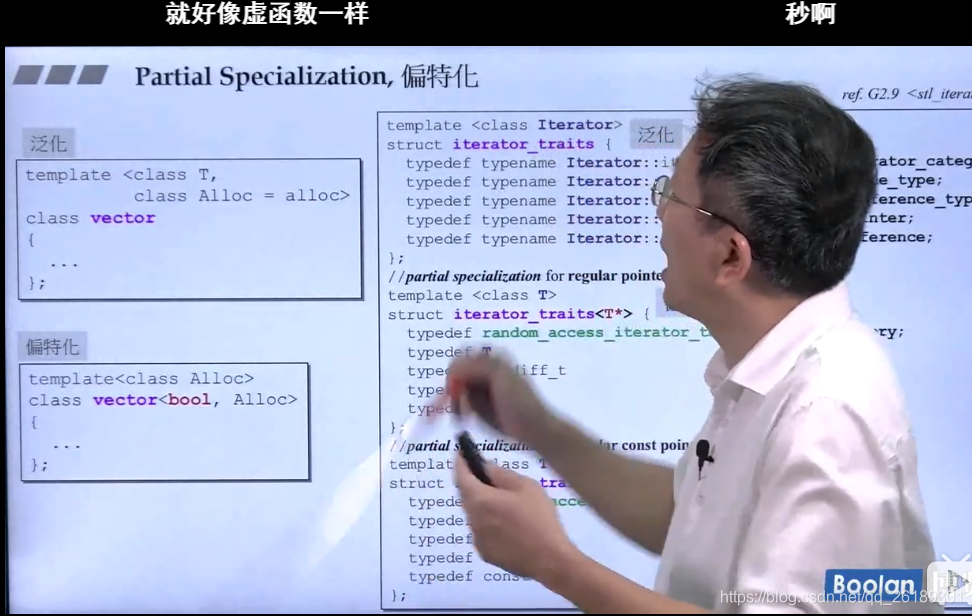
偏特化 Partial specialization
接受两个模板参数,绑定其中一个模板参数,变成只有一个了(比如关联式容器)

vector<bool>是一个特化版本。
下图中的偏特化,一个是指针,另一个是const 指针:

特化
函数模板能被重载,而类模板不可以,我们可以通过特化来实现相似的效果,从而可以透明地获得具有更高效率的代码。
特化也分为了两种,全特化和偏特化。
- 不能将特化和重载混为一谈
- 全特化和偏特化都没有引入一个全新的模板或者模板实例。它们只是对原来的泛型(或者非特化)模板中已经隐式声明的实例提供另一种定义。
- 在概念上,这是一个相对比较重要的现象,也是特化区别于重载模板的关键之处。
- 函数模板重载样例
#include <iostream>
using namespace std;
//函数模板
template <typename T>
int fun(T){
return 1;
}
//函数模板的重载
template <typename T>
int fun(T*){
return 2;
}
int main(){
cout << fun<int*>((int*)0) << endl;
cout << fun<int>((int*)0) << endl;
return 0;
}
全特化
全特化是模板的一个唯一特例,指定的模板实参列表必须和相应的模板参数列表一一对应。
我们不能用一个非类型值来替换模类型参数。但是如果模板参数具有缺省模板实参,那么用来替换实参就是可选的。
全特化样例:
#include <iostream>
using namespace std;
template<typename T1, typename T2>
class A{
public:
void function(T1 value1, T2 value2){
cout<<"value1 = "<<value1<<endl;
cout<<"value2 = "<<value2<<endl;
}
};
template<>
class A<int, double>{ // 类型明确化,为全特化类
public:
void function(int value1, double value2){
cout<<"intValue = "<<value1<<endl;
cout<<"doubleValue = "<<value2<<endl;
}
};
int main(){
A<int, double> a;
a.function(12, 12.3);
return 0;
}
偏特化
偏特化是介于普通模板和全特化之间,只存在部分的类型明确化,而非将模板唯一化。
再次划重点 函数模板不能被偏特化。
偏特化类样例:
#include <iostream>
using namespace std;
template<typename T1, typename T2>
class A{
public:
void function(T1 value1, T2 value2){
cout<<"value1 = "<<value1<<endl;
cout<<"value2 = "<<value2<<endl;
}
};
template<typename T>
class A<T, double>{ // 部分类型明确化,为偏特化类
public:
void function(T value1, double value2){
cout<<"Value = "<<value1<<endl;
cout<<"doubleValue = "<<value2<<endl;
}
};
int main(){
A<char, double> a;
a.function('a', 12.3);
return 0;
}
偏特化的特殊例子
//这段代码是STL源码中的一部分
template <class Iterator>
struct iterator_traits {
typedef typename Iterator::iterator_category iterator_category;
typedef typename Iterator::value_type value_type;
typedef typename Iterator::difference_type difference_type;
typedef typename Iterator::pointer pointer;
typedef typename Iterator::reference reference;
};
/*
* 偏特化版本,我们可以看到他的唯一不同之处就是T*,这也是偏特化的一种
*/
template <class T>
struct iterator_traits<T*> {
typedef random_access_iterator_tag iterator_category;
typedef T value_type;
typedef ptrdiff_t difference_type;
typedef T* pointer;
typedef T& reference;
};
重点总结
类模板和函数模板都可以被全特化;
类模板能偏特化,不能被重载;
函数模板全特化,不能被偏特化。
模板类调用优先级
对主版本模板类、全特化类、偏特化类的调用优先级从高到低进行排序是:
全特化类>偏特化类>主版本模板类
这样的优先级顺序对性能也是最好的
面试tag:
(请问函数模板和类模板有什么区别?)
除了上面所说的以外:
- 函数模板的实例化是由编译程序在处理函数调用时自动完成的,而类模板的实例化必须由程序员在程序中显式地指定。
- 即函数模板允许隐式调用和显式调用而类模板只能显式调用
- 与函数模板不同的是,类模板在实例化时必须显式地指明数据类型,编译器不能根据给定的数据推演出数据类型。
- 这期间有涉及到函数模板与模板函数,类模板与模板类的概念(类似于类与类对象的区别)。请看下面例子
- 注意:模板类的函数声明和实现必须都在头文件中完成,不能像普通类那样声明在.h文件中实现在.cpp文件中。
- 即,模板不支持分离编译 。如下是之前总结的模板为什么不支持分离编译
https://blog.csdn.net/wyn126/article/details/76733943 - 含义是:在定义模板的头文件.h时,模板的成员函数实现也必须写在头文件.h中,而不能像普通的类(class)那样,class的声明(declaration)写在.h文件中,class的定义(definition)写在.cpp文件中
- 类模板可以全特化和偏特化,而函数模板不能够偏特化,只能全特化。类模板如果需要一个接收指针的偏特化版本,那么就可以指针偏特化实现;而函数模板不存在偏特化。例如,在STL中需要设计的Iterator Traits,用于提取迭代器类的五种关联类型,而同时要使得算法对指针(理解为退化的迭代器)也能使用,而指针不是一个类,如何获取内部的5个类型呢?这里就用到了类模板类的指针偏特化来区分开T的指针 和T 的迭代器。
复习一下函数重载:
为了交换不同类型的变量的值,我们通过函数重载定义了四个名字相同、参数列表不同的函数,如下所示:
#include <iostream>
using namespace std;
//交换 int 变量的值
void Swap(int *a, int *b){
int temp = *a;
*a = *b;
*b = temp;
}
//交换 float 变量的值
void Swap(float *a, float *b){
float temp = *a;
*a = *b;
*b = temp;
}
//交换 char 变量的值
void Swap(char *a, char *b){
char temp = *a;
*a = *b;
*b = temp;
}
//交换 bool 变量的值
void Swap(bool *a, bool *b){
char temp = *a;
*a = *b;
*b = temp;
}
int main(){
//交换 int 变量的值
int n1 = 100, n2 = 200;
Swap(&n1, &n2);
cout<<n1<<", "<<n2<<endl;
//交换 float 变量的值
float f1 = 12.5, f2 = 56.93;
Swap(&f1, &f2);
cout<<f1<<", "<<f2<<endl;
//交换 char 变量的值
char c1 = 'A', c2 = 'B';
Swap(&c1, &c2);
cout<<c1<<", "<<c2<<endl;
//交换 bool 变量的值
bool b1 = false, b2 = true;
Swap(&b1, &b2);
cout<<b1<<", "<<b2<<endl;
return 0;
}
注意,参数列表不同包括参数的个数不同、类型不同或顺序不同,仅仅参数名称不同是不可以的。函数返回值也不能作为重载的依据。
函数的重载的规则:
- 函数名称必须相同。
- 参数列表必须不同(个数不同、类型不同、参数排列顺序不同等)。
- 函数的返回类型可以相同也可以不相同。
- 仅仅返回类型不同不足以成为函数的重载。
C++ 是如何做到函数重载的
C++代码在编译时会根据参数列表对函数进行重命名,例如void Swap(int a, int b)会被重命名为_Swap_int_int,void Swap(float x, float y)会被重命名为_Swap_float_float。当发生函数调用时,编译器会根据传入的实参去逐个匹配,以选择对应的函数,如果匹配失败,编译器就会报错,这叫做重载决议(Overload Resolution)。
- 不同的编译器有不同的重命名方式,这里仅仅举例说明,实际情况可能并非如此。
从这个角度讲,函数重载仅仅是语法层面的,本质上它们还是不同的函数,占用不同的内存,入口地址也不一样。
关于函数模板和函数重载
接着上面讲;
这些swap函数虽然在调用时方便了一些,但从本质上说还是定义了三个功能相同、函数体相同的函数,只是数据的类型不同而已,这看起来有点浪费代码,能不能把它们压缩成一个函数呢?
可以借助本节讲的函数模板。
模板总结:
优点:
- 模板复用了代码,节省资源,C++标准库因此而产生
增强了代码的灵活性
缺点:
- 模板让代码变得凌乱复杂,不易维护,增加了编译时间
- 出现模板编译错误时,错误信息非常凌乱,不易维护
- 每种类型的参数都会产生额外的代码,导致文件膨胀,代码量过长
参考:模板的定义、使用及特化_跑够一万公里就结婚-CSDN博客_定义特化模板 https://blog.csdn.net/wyn126/article/details/79847665














 1015
1015











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









