







模型压缩常用的方法有:剪枝,分解、蒸馏、量化、轻量级网络模型。记录学习量化时小结。
背景:当前神经网络通常使用浮点数格式存储权重、网络结构等,这是保持模型准确性的有效而且最简单的方法,GPU也可以较好的加速这些计算。但是随着模型加载次数的增加前向推导计算也成正比增加,Quentization能有效解决此问题,它比32位更紧凑的格式来存储数字,并进行计算。
可行性:低精度计算是噪音的另一个来源(待确认??)
作用: 能减小模型所占空间。
量化方法及计算例子(8bit为例子):
法一:存储每个层的最小值和最大值,然后将每个浮点值压缩成一个8位整数,在最大值、最小值范围内空间线性划分 256 段,每段用一个唯一的 8-bit 整数表示在该段内的实数值,计算时再转换为浮点数;
例子: 某一层参数最小、最大值:-10,10。将其非常256段,0段表示-10,第256段表示10,故128段表示0数值,64段表示-5等等。
之间的浮点数与段数关系为:

其中X为浮点数,N为段数
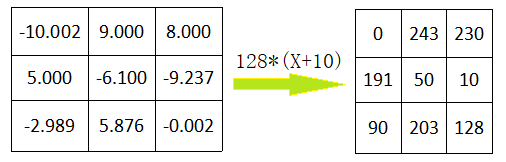
左表是真实的网络参数(浮点数),右表是经过quantization量化后的段数。存储量,下降为原本的1/4,运行模型时转换为浮点型,转换公式如下:
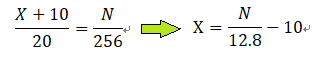
其中X为浮点数,N为段数















 813
813











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









