







什么是漏斗分析?
所谓的用户行为分析,就是通过对用户在产品(比如APP、网站等)上的行为数据进行收集、处理和分析,来洞察用户的真实需求和特征。这些行为数据包含用户的浏览记录、点击行为、购买、收藏等数据。通过分析这些收集的数据,企业能够更准确地了解用户的行为习惯和购买偏好等,为产品优化和营销策略制定提供有力支持。那么漏斗分心模型是用户行为分析中最重要的模型,漏斗分析是一种常用于产品分析、市场营销和用户行为分析的方法,用来跟踪用户在完成特定目标的过程中,从一个步骤到另一个步骤的流失情况。通常呈现为一个“漏斗”形状,表示的是一系列步骤,用户在每个步骤上都有机会流失。漏斗的宽度代表了每一步的用户数量,而随着步骤的进行,用户数量逐渐减少,因此漏斗呈现出逐渐变窄的形态。举个例子,当你打开某宝想买东西的时候,你至少会经历以下几步:
-
打开APP进入首页
-
进去商品详情页,看了觉得还不错,点购物车
-
进入购物车页面
-
填写相关信息,提交订单
-
进入支付页面,完成支付,商家发货
这些具体的步骤在数据上的体现,是人会越来越少,那我们可以用图形来表达,这个图类似一个漏斗,如下图:

漏斗分析的要点和分类
从上图我们也可以观察出漏斗分析自身特性,可以总结为以下几点:
1.事件:用户在使用APP或者浏览网页的时候,各种行为数据组成,比如浏览行为、点击行为、购物行为等,这些行为统称为事件,也是用户分析的主体,在漏斗分析中,每一层的漏斗,就是一个事件。其中,核心的指标就是转化率,具体公式如下:转化率 = 本层事件人数/上层事件人数。
2.步骤:漏斗的每一步就是我们上面说的事件,这些事件都是我们分析的关键点,那么他们之间的关系,可以展现出漏斗的转化和流失情况。
3.时间:指漏斗分析的转化窗口期。也就是漏斗从第一层转化到最后一层的时间段,整个流程都在这个时间段里,用户在设定的窗口期内完成完整的转化流程才算做转化成功。
漏斗可以分为两类:有序漏斗和无序漏斗
有序漏斗:在漏斗的周期内,严格限定每个步骤之间的发生顺序,用户必须先完成某个步骤才能进入下一个步骤。各步骤之间存在明确的先后顺序和依赖关系,前一个步骤是后一个步骤的前提,用户的转化路径相对固定。比如:电商网站的购买流程,用户通常需要先登录或注册,然后浏览商品、加入购物车、提交订单、支付等,这些步骤的顺序基本固定,不能颠倒。
无序漏斗:不限定漏斗中多个步骤之间事件发生的顺序,用户的行为顺序可以是任意的。用户在不同步骤之间的操作没有严格的先后顺序要求,可能会根据自身的需求和偏好,以不同的顺序完成各个环节。比如:社交媒体平台上用户从初次接触到最终成为活跃用户的过程,可能先关注了品牌账号,然后查看相关内容,接着进行评论、分享,最后才决定是否点赞或参与活动等,这些行为的顺序并不固定。
如何制作漏斗模型
制作漏斗并不是简单我们可以看见的一张图那么简单,具体涉及底层数据的收集和清洗,根据数据构建漏斗模型,如果要构建一个漏斗模型的话,起码需要满足三个基本条件:
条件一:整体流程上,要有前后关联的N个步骤:
比如上面我们将的例子中购物网首页→详情页→购物车→支付就是一个前后有关联的流程。在做漏斗分析前,要认真梳理自己分析的流程,看清楚到底有几步组成。
条件二:数据收集,每个步骤得有数据记录。
没有数据根据做不了漏斗,这一点非常重要,决定了漏斗分析到底能不能做。数据由数据开发人员收集,存储与数据仓库中,当我们构建漏斗时,需要把数据拿出来构建漏斗需要的格式。其实也存在几个前后有关联的步骤,但是很多情况下没有数据,这个时候就无法做漏斗了。互联网电商企业也是类似,如果没有做好埋点的话,也会缺失过程数据,所以平时的用户行为数据的收集至关重要。
条件三:统计上,从完成第一个环节开始统计。
这一点也非常重要,涉及统计准确性。还以上面的例子,实际上用户行为不会从购物网首页→详情页→购物车→支付一下到底,而是相当随性的。比如先点击首页以后退出去看看别的商品,回头想想第一次看的商品好,于是又搜索了商品名称,转回来商品详情页,这个中间会发生很多事件。所以此时统计漏斗数据时候,需要按照指定好的步骤进行统计,也就是我们自己定义步骤,完成上一个步骤,才统计下一个步骤行为。
漏斗开发具体步骤:
1)收集业务流程节点
梳理业务环节:明确整个业务流程中涉及的各个关键步骤,例如在电商领域,可能包括访问量、注册用户、加入购物车、提交订单、成交客户等;在社交媒体营销中,可能是曝光、点击、关注、互动、转化等。确保节点完整性和准确性:业务流程节点应涵盖从潜在客户到最终转化或目标达成的全过程,且各节点的定义要清晰明确,避免模糊不清导致后续数据收集和分析出现问题。
2)收集并统计每个步骤的数据
选择数据收集方法:根据业务特点和数据来源选择合适的工具,如网页埋点日志数据收集、业务数据库等。同时,确定数据收集的时间范围,以确保数据的时效性和可比性。
准确记录和整理数据:按照确定的业务流程节点,逐一收集每个步骤的相关数据,并进行整理和分类。确保数据的准确性和完整性,对于缺失或异常的数据要及时进行核实和补充。
3)构建用户行为分析系统(包含漏斗分析功能)
如果要做漏斗分析,一般企业都会构建自己的分析系统,然后需要漏斗分析的时候,选择自己要构造漏斗的类型,创建漏斗模型。
4) 添加漏斗事件步骤
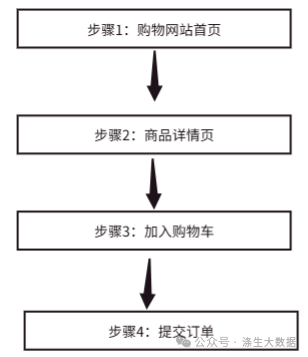
漏斗步骤就是漏斗分析的核心部分,步骤间统计数据的对比,就是我们分析步骤间数据的转化和流失的关键指标。比如我们以一个“买东西”的活动为例。预设的用户的行为路径是:用户首先进入【购物网站首页】,浏览商品,然后发现自己喜欢的商品,点击进入【商品详情页】,根据提示跳转到【加入购物车】,选择自己感兴趣的应用下载,完成后,进入【提交订单】领取活动奖励。从上面描述的场景中,我们可以提取出以下关键的四步。
5) 确定漏斗的时间区间和周期
这里多了一个时间区间的概念,与前文介绍的周期容易混淆。一般来说,此类数据的数仓表是按照时间分区的。所以选择时间区间,本质就是选择要计算的数据范围。
周期是指一个漏斗从第一步流转到最后一步的时间限制,即是用来界定怎样才是一个完整的漏斗。在本例中,我们按照天为周期进行处理,选择时间区间为“2021-05-27”、“2021-05-28”、“2021-05-29”。
6) 漏斗数据的展示
依据我们设计的漏斗模型(具体模型设计,下文会提及),可以计算出下表的数据:
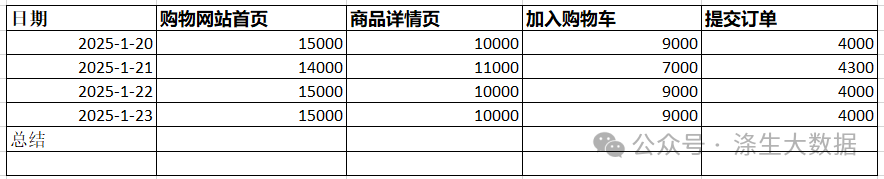
总之,通过优化做的不好的环节,提升整体转化率,是最终目标。
ClickHouse中的实现
整体工程主要分为配置、计算、存储三阶段。具体架构如下图:
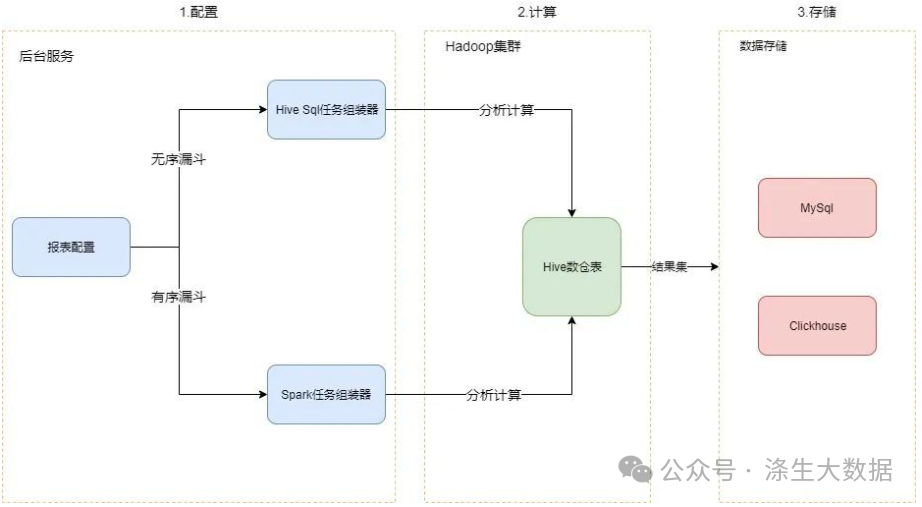
用户可以在前端按照自身需求设置漏斗类型、漏斗步骤、筛选条件、时间区间和周期等配置。然后服务后台收到配置请求后,依据漏斗类型选择不同任务组装器进行任务的组装。其中,使用的Hive SQL 或者Spark任务组装器。组装后生成的任务包含了漏斗模型的计算逻辑,比如 Hive SQL或者 Spark 任务。平台根据接收到的任务的类型,选择Hive或者 Spark引擎进行分析计算。最后计算结果同步到 ClickHouse集群。ClickHouse强大的即时计算和分析能力,为用户提供所查即所得的使用体验。用户可以根据自身业务需求选择即时查询或者离线报表。
ClickHouse 主要函数使用(具体作用参考官方文档):
1.windowFunnel(window, [mode, [mode, ... ]])(timestamp, cond1, cond2, ..., condN)2.arrayWithConstant(length,param)3.arrayEnumerate(arr)4.groupArray(x)
为了更加清晰的讲解整个过程,我们举一个例子演示一下整个过程。
首先构建一个ClickHouse表funnel_test,包含用户唯一标识userId,事件名称event,事件发生日期day。
建表语句如下:
create table ods_game_dev.t_funnel_all_d
(
userId String,
event String,
day DateTime
)
insert into ods_game_dev.t_funnel_all_d values(1,'启动','2025-01-20 11:00:00');
insert into ods_game_dev.t_funnel_all_d values(1,'首页','2025-01-20 11:10:00');
insert into ods_game_dev.t_funnel_all_d values(1,'详情','2025-01-20 11:20:00');
insert into ods_game_dev.t_funnel_all_d values(1,'点击','2025-01-20 11:30:00');
insert into ods_game_dev.t_funnel_all_d values(1,'下单','2025-01-20 11:40:00');
insert into ods_game_dev.t_funnel_all_d values(2,'启动','2025-01-21 11:00:00');
insert into ods_game_dev.t_funnel_all_d values(2,'首页','2025-01-21 11:10:00');
insert into ods_game_dev.t_funnel_all_d values(2,'点击','2025-01-21 11:20:00');
insert into ods_game_dev.t_funnel_all_d values(2,'下单','2025-01-21 11:30:00');
insert into ods_game_dev.t_funnel_all_d values(3,'启动','2025-01-20 11:00:00');
insert into ods_game_dev.t_funnel_all_d values(3,'首页','2025-01-21 11:00:00');
insert into ods_game_dev.t_funnel_all_d values(3,'详情','2025-01-22 11:00:00');
insert into ods_game_dev.t_funnel_all_d values(3,'下单','2025-01-23 11:00:00');
insert into ods_game_dev.t_funnel_all_d values(4,'启动','2025-01-22 11:00:00');
insert into ods_game_dev.t_funnel_all_d values(4,'首页','2025-01-22 11:01:00');
insert into ods_game_dev.t_funnel_all_d values(4,'首页','2025-01-22 11:02:00');
insert into ods_game_dev.t_funnel_all_d values(4,'详情','2025-01-22 11:03:00');
insert into ods_game_dev.t_funnel_all_d values(4,'详情','2025-01-22 11:04:00');
insert into ods_game_dev.t_funnel_all_d values(4,'下单','2025-01-22 11:05:00');假定,漏斗的步骤为:启动->首页->详情→下单,1)首先使用ClickHouse的漏斗构建函数windowFunnel()查询。
SELECT userId,
windowFunnel(86400)(
day,
event = '启动',
event = '首页',
event = '详情',
event = '下单'
) AS level
FROM (
SELECT day, event, userId
FROM t_funnel_all_d
WHERE toDate(day) >= '2025-01-20'
and toDate(day) <= '2025-01-23'
)
GROUP BY userId;1)获取每个用户在每个层级的明细数据
SELECT userId,
arrayWithConstant(level, 1) levels,
arrayJoin(arrayEnumerate(levels)) level_index
FROM (
SELECT userId,
windowFunnel(86400)(
day,
event = '启动',
event = '首页',
event = '详情',
event = '下载'
) AS level
FROM (
SELECT day, event, userId
FROM t_funnel_all_d
WHERE toDate(day) >= '2025-01-20'
and toDate(day) <= '2025-01-23'
)
GROUP BY userId
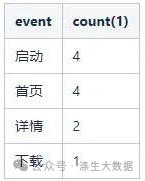
);2)计算漏斗各层的用户数,将上面步骤得到的明细数据按照漏斗层级分组聚合,就得到了每个层级的用户数。总体逻辑如下:
SELECT transform(level_index,[1,2,3,4],['启动','首页','详情','下载'],'其他') as event,
count(1)
FROM (
SELECT userId,
arrayWithConstant(level, 1) levels,
arrayJoin(arrayEnumerate(levels)) level_index
FROM (
SELECT userId,
windowFunnel(86400)(
day,
event = '启动',
event = '首页',
event = '详情',
event = '下载'
) AS level
FROM (
SELECT day, event, userId
FROM t_funnel_all_d
WHERE toDate(day) >= '2025-01-20'
and toDate(day) <= '2025-01-23'
)
GROUP BY userId
)
)
group by level_index结果为:


















 1139
1139

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











