







一、题目
有 n 个人被分成数量未知的组。每个人都被标记为一个从 0 到 n - 1 的 唯一ID 。
给定一个整数数组 groupSizes ,其中 groupSizes[i] 是第 i 个人所在的组的大小。例如,如果 groupSizes[1] = 3 ,则第 1 个人必须位于大小为 3 的组中。
返回一个组列表,使每个人 i 都在一个大小为 groupSizes[i] 的组中。
每个人应该 恰好只 出现在 一个组 中,并且每个人必须在一个组中。如果有多个答案,返回其中 任何 一个。可以 保证 给定输入 至少有一个 有效的解。
二、示例
2.1> 示例 1:
【输入】groupSizes = [3,3,3,3,3,1,3]
【输出】[[5],[0,1,2],[3,4,6]]
【解释】
第一组是 [5],大小为 1,groupSizes[5] = 1。
第二组是 [0,1,2],大小为 3,groupSizes[0] = groupSizes[1] = groupSizes[2] = 3。
第三组是 [3,4,6],大小为 3,groupSizes[3] = groupSizes[4] = groupSizes[6] = 3。
其他可能的解决方案有 [[2,1,6],[5],[0,4,3]] 和 [[5],[0,6,2],[4,3,1]]。
2.2> 示例 2:
【输入】groupSizes = [2,1,3,3,3,2]
【输出】[[1],[0,5],[2,3,4]]
提示:
- groupSizes.length == n
- 1 <= n <= 500
- 1 <= groupSizes[i] <= n
三、解题思路
3.1> 思路1:哈希表 + 取余分组
根据题目表述,我们会获得一个数组groupSizes,该数组中的下标index表示的是某个人的唯一标识,大家可以把它当做是userId;那么数组中对应的元素值,即:groupSIzes[userId],表示的就是这个User所在的数组的长度值。也就是说,如果userId等于3(index=3),它对应的数组中元素值为2(groupSIzes[2]),那么说明userId等于3的这个人,应该存在于一个数组长度等于2的数组中。
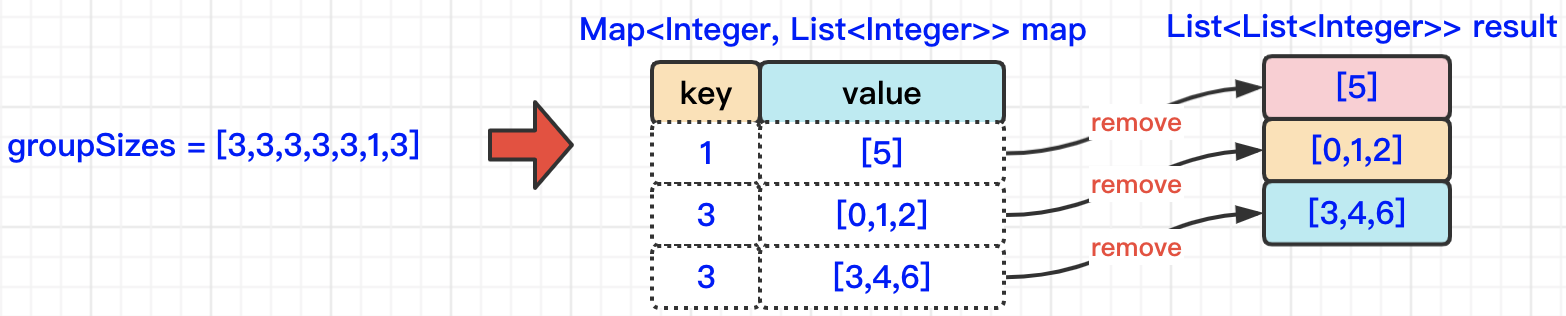
既然了解明白了题意,我们在思路一种,首先想到的是,要把原有的数组groupSizes中的每个元素,进行一个迁移操作。那迁移到哪里去会比较好呢?因为这里面涉及到userId与所在数组长度的对应关系,所以,我们第一个想到的就应该是迁移到Map结构中,Map中的key保存数组长度,value保存userId。那么以groupSizes=[3,3,3,3,3,1,3]为例,当迁移到map结构中以后,对应的key=1,value=[5];key=3,value=[0,1,2,3,4,6]。
那么,在后续的操作,跟我们打交道的就是这个map了。我们通过获得map中的每一个Entry对象,从而循环进行遍历操作。比如,我们获得map中的第一个Entry对象,它的key等于1,value等于[5]。那么我们就可以创建一个长度为1的ArrayList集合,然后将元素5放入其中。
当我们获得第二个Entry对象的时候,key等于3,value等于[0,1,2,3,4,6],在这种情况下,我们就面临着要拆分集合操作了。怎么拆分呢?这里我们通过value中元素的index与数组size取余,如果发现结果等于0了,就说明该执行拆分了。以上面的第二个Entry为例,key等于3,所以长度size也就等于3,那么,index等于0、1、2的时候,与3取余都不为0,只有当index=3的时候,与3取余等于0,所以,index等于3、4、5的时候,是放入另外一个集合中的。具体操作,如下图所示:

确定了解题思路,代码实现就比较简单了。具体代码实现,请参见4.2> 实现1:哈希表 + 取余分组
3.2> 思路2:哈希表 + 长度判断
其实我们仔细分析题意,我们会发现,元素的个数与数组长度是相匹配的。什么意思呢?我们还是以groupSizes=[3,3,3,3,3,1,3]为例,我们发现,最终结果里,分组长度为3的一共有两组,分别是[0,1,2]和[3,4,6],长度为3的集合里,存储了正好3个元素,那可不可以只存储2个元素呢?也就是说,如果入参是groupSizes=[3,3,3,1,3]的时候,不就满足了长度为3的两个集合中,一个存储了[0,1,2],另外一个存储了[4]嘛。 那是,其实在题目中的约束里,是不允许的。比如,我们修改一下测试用例,就会给我们如下的提示:

那么既然分组中都会填满元素,那么我们就可以有另外一种更便捷的解题思路了。也就是说,我们将groupSizes数组转换为Map这一步骤没有变化,但是呢,每当从groupSizes中获取一个元素,然后添加到Map的时候,我们都要判断一下,此时的value中的size是不是等于了key值,如果等于,说明value中存储的元素已经可以作为一个分组放入的最终结果的result集合中了,那么通过调用Map的remove()方法将数据迁移到result中。这种方式代码量会减少很多,而且执行效率也比较高。具体操作,如下图所示:
关于思路2中的代码实现,请参见4.2> 实现2:哈希表 + 长度判断
四、代码实现
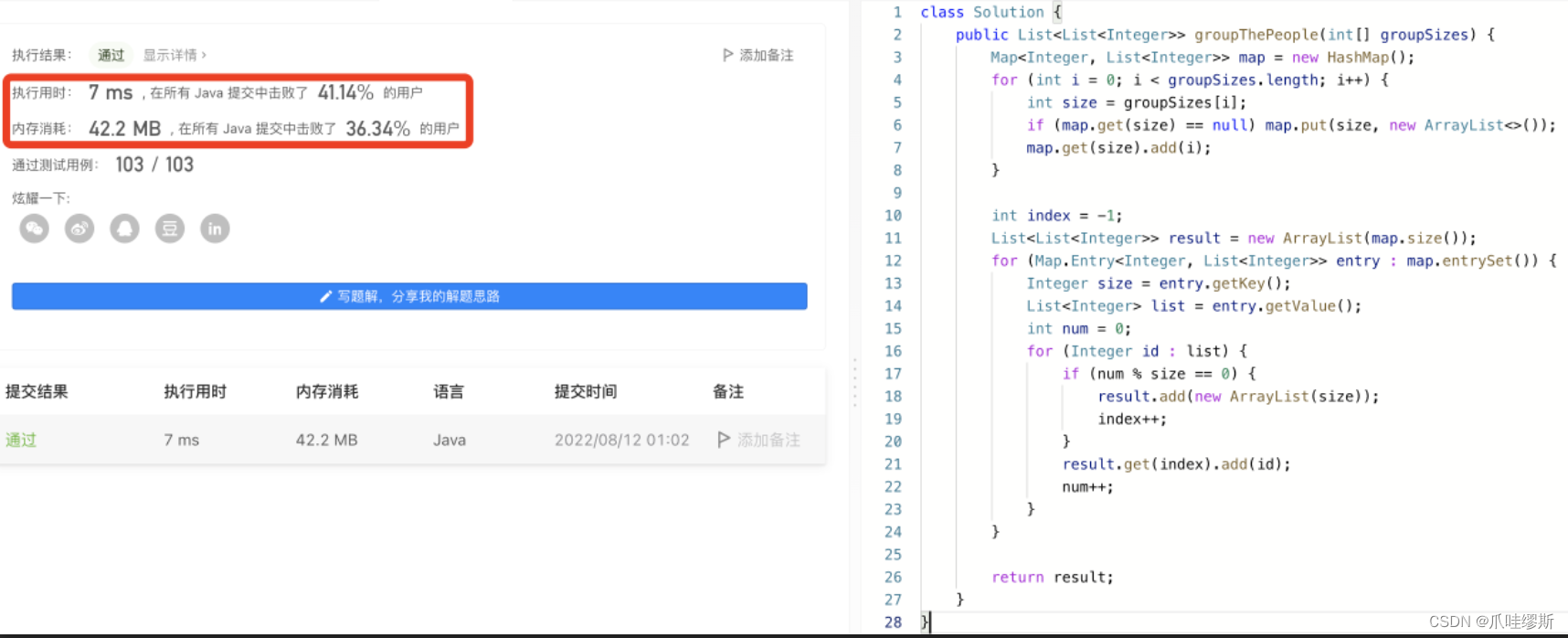
4.1> 实现1:哈希表 + 取余分组
class Solution {
public List<List<Integer>> groupThePeople(int[] groupSizes) {
Map<Integer, List<Integer>> map = new HashMap();
for (int i = 0; i < groupSizes.length; i++) {
int size = groupSizes[i];
if (map.get(size) == null) map.put(size, new ArrayList<>());
map.get(size).add(i);
}
int index = -1;
List<List<Integer>> result = new ArrayList(map.size());
for (Map.Entry<Integer, List<Integer>> entry : map.entrySet()) {
Integer size = entry.getKey();
List<Integer> list = entry.getValue();
int num = 0;
for (Integer id : list) {
if (num % size == 0) {
result.add(new ArrayList(size));
index++;
}
result.get(index).add(id);
num++;
}
}
return result;
}
}
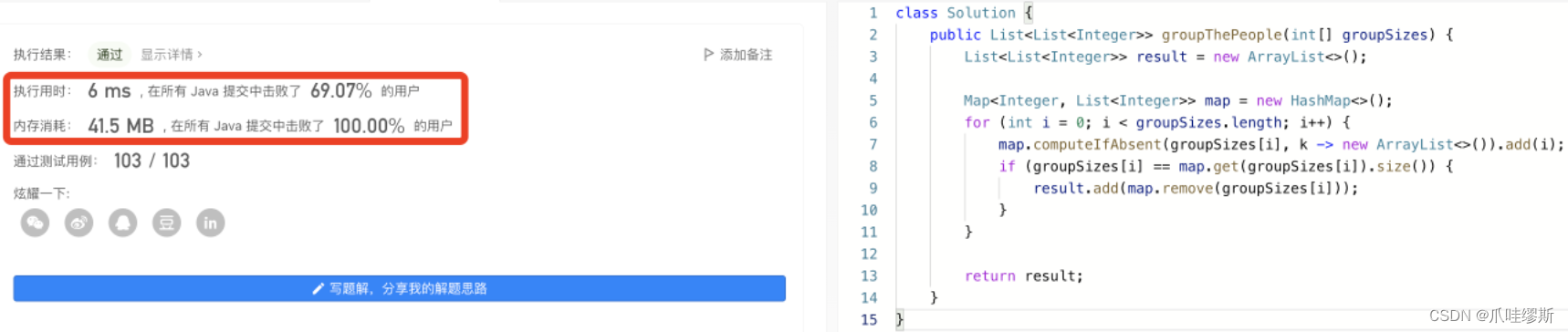
4.2> 实现2:哈希表 + 长度判断
class Solution {
public List<List<Integer>> groupThePeople(int[] groupSizes) {
List<List<Integer>> ans = new ArrayList<>();
Map<Integer, List<Integer>> map = new HashMap<>();
for (int i = 0; i < groupSizes.length; i++) {
map.computeIfAbsent(groupSizes[i], k -> new ArrayList<>()).add(i);
if (groupSizes[i] == map.get(groupSizes[i]).size()) {
ans.add(map.remove(groupSizes[i]));
}
}
return ans;
}
}
今天的文章内容就这些了:
写作不易,笔者几个小时甚至数天完成的一篇文章,只愿换来您几秒钟的 点赞 & 分享 。
更多技术干货,欢迎大家关注公众号“爪哇缪斯” ~ \(^o^)/ ~ 「干货分享,每天更新」
















 211
211











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









