







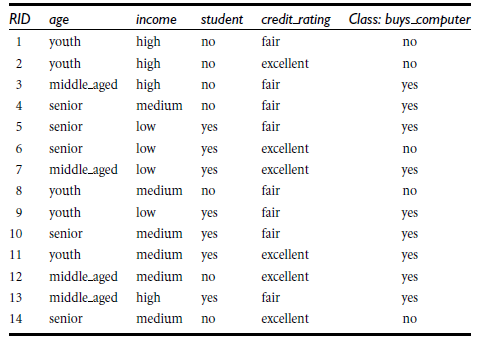
原始数据:
1.reader.next()报错
Python3#DictVectorizer,只支持integer,不支持类型数据
from sklearn.feature_extraction import DictVectorizer
#csvpython自带包
import csv
#
from sklearn import tree
from sklearn import preprocessing
from sklearn.externals.six import StringIO
#
decision = open(r'G:\Machine_Learning\Machine_Learning\decision\DecisionTree.csv','rb')
reader = csv.reader(decision)
headers = next(reader)
print(headers)
此处显示报错,原因是pyuthon3中已经没有了".next()",因此修改代码如下:
#DictVectorizer,只支持integer,不支持类型数据
from sklearn.feature_extraction import DictVectorizer
#csvpython自带包
import csv
#
from sklearn import tree
from sklearn import preprocessing
from sklearn.externals.six import StringIO
#
decision = open(r'G:\Machine_Learning\Machine_Learning\decision\DecisionTree.csv','rb')
reader = csv.reader(decision)
headers = reader.next()
print(headers)即将‘rb’修改成‘rt’,同时将reader.next()修改为next(reader),打印结果为:

显示成功。
2.遍历数据
#每一行遍历
for row in reader:
#取每一行的最后一个值加到labellist
lablelist.append(row[len(row)-1])
#构建一个字典
rowDict ={}
#
for i in range(1,len(row)-1):
#字典中的key对应的是属性,如age。具体的值就是取出的值
rowDict[headers[i]]=row[i]
featurelist.append(rowDict)
#打印出特征值得类型
print(lablelist)
print(featurelist)
3.将原始数据转换成0-1向量
#Vetorize features将原始数据转换成0,1的类型
vec = DictVectorizer()
dummyX = vec.fit_transform(featurelist).toarray()#打印出转换的矩阵形式
print("dummyX: \n"+str(dummyX))#获取到特征值名称
print(vec.get_feature_names())
#标记值同样操作
#Vectorize class labels
lb = preprocessing.LabelBinarizer()
dummyY = lb.fit_transform(lablelist)
print("dummyY: "+str(dummyY))
#使用决策树进行分类
#clf= tree.DecisionTreeClassifier()
#此处采用的交叉熵的形式
clf = tree.DecisionTreeClassifier(criterion='entropy')
clf=clf.fit(dummyX,dummyY)
print("clf: "+str(clf))
#保存可视化模型
with open(".\DecisionTree\decisonTree.dot",'w')as f:
f = tree.export_graphviz(clf,feature_names=vec.get_feature_names(),out_file=f)
oneRowX = dummyX[0,:]
print("oneRowX: "+str(oneRowX))
#测试分类效果
newRowX = oneRowX
newRowX[0]=1
newRowX[2]=0
print("newRowx: "+str(newRowX))
prpredictedY = clf.predict(newRowX)
print("predictedY: "+str(prpredictedY))
将.dot文件转化为pdf文件可视化决策树的操作:
win+r,输入cmd进入到命令行窗口,进入到.dot所在的文件夹
输入命令:dot -Tpdf decisionTree.dot -o outpu.pdf之后即可在dot文件夹下找到可视化决策树的pdf文件
注:outpu为输出的文件夹名















 2128
2128











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









