





一、引言
在最开始的时候,我本来准备学习的是C4.5算法,后来发现C4.5算法的核心还是ID3算法,所以又辗转回到学习ID3算法了,因为C4.5是他的一个改进。至于是什么改进,在后面的描述中我会提到。
二、ID3算法
ID3算法是一种分类决策树算法。他通过一系列的规则,将数据最后分类成决策树的形式。分类的根据是用到了熵这个概念。熵在物理这门学科中就已经出现过,表示是一个物质的稳定度,在这里就是分类的纯度的一个概念。公式为:
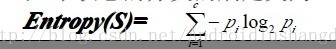
在ID3算法中,是采用Gain信息增益来作为一个分类的判定标准的。他的定义为:

每次选择属性中信息增益最大作为划分属性,在这里本人实现了一个java版本的ID3算法,为了模拟数据的可操作性,就把数据写到一个input.txt文件中,作为数据源,格式如下:
- DayOutLookTemperatureHumidityWindPlayTennis
- 1SunnyHotHighWeakNo
- 2SunnyHotHighStrongNo
- 3OvercastHotHighWeakYes
- 4RainyMildHighWeakYes
- 5RainyCoolNormalWeakYes
- 6RainyCoolNormalStrongNo
- 7OvercastCoolNormalStrongYes
- 8SunnyMildHighWeakNo
- 9SunnyCoolNormalWeakYes
- 10RainyMildNormalWeakYes
- 11SunnyMildNormalStrongYes
- 12OvercastMildHighStrongYes
- 13OvercastHotNormalWeakYes
- 14RainyMildHighStrongNo
- packageDataMing_ID3;
- importjava.io.BufferedReader;
- importjava.io.File;
- importjava.io.FileReader;
- importjava.io.IOException;
- importjava.util.ArrayList;
- importjava.util.HashMap;
- importjava.util.Iterator;
- importjava.util.Map;
- importjava.util.Map.Entry;
- importjava.util.Set;
- /**
- *ID3算法实现类
- *
- *@authorlyq
- *
- */
- publicclassID3Tool{
- //类标号的值类型
- privatefinalStringYES="Yes";
- privatefinalStringNO="No";
- //所有属性的类型总数,在这里就是data源数据的列数
- privateintattrNum;
- privateStringfilePath;
- //初始源数据,用一个二维字符数组存放模仿表格数据
- privateString[][]data;
- //数据的属性行的名字
- privateString[]attrNames;
- //每个属性的值所有类型
- privateHashMap<String,ArrayList<String>>attrValue;
- publicID3Tool(StringfilePath){
- this.filePath=filePath;
- attrValue=newHashMap<>();
- }
- /**
- *从文件中读取数据
- */
- privatevoidreadDataFile(){
- Filefile=newFile(filePath);
- ArrayList<String[]>dataArray=newArrayList<String[]>();
- try{
- BufferedReaderin=newBufferedReader(newFileReader(file));
- Stringstr;
- String[]tempArray;
- while((str=in.readLine())!=null){
- tempArray=str.split("");
- dataArray.add(tempArray);
- }
- in.close();
- }catch(IOExceptione){
- e.getStackTrace();
- }
- data=newString[dataArray.size()][];
- dataArray.toArray(data);
- attrNum=data[0].length;
- attrNames=data[0];
- /*
- *for(inti=0;i<data.length;i++){for(intj=0;j<data[0].length;j++){
- *System.out.print(""+data[i][j]);}
- *
- *System.out.print("\n");}
- */
- }
- /**
- *首先初始化每种属性的值的所有类型,用于后面的子类熵的计算时用
- */
- privatevoidinitAttrValue(){
- ArrayList<String>tempValues;
- //按照列的方式,从左往右找
- for(intj=1;j<attrNum;j++){
- //从一列中的上往下开始寻找值
- tempValues=newArrayList<>();
- for(inti=1;i<data.length;i++){
- if(!tempValues.contains(data[i][j])){
- //如果这个属性的值没有添加过,则添加
- tempValues.add(data[i][j]);
- }
- }
- //一列属性的值已经遍历完毕,复制到map属性表中
- attrValue.put(data[0][j],tempValues);
- }
- /*
- *for(Map.Entryentry:attrValue.entrySet()){
- *System.out.println("key:value"+entry.getKey()+":"+
- *entry.getValue());}
- */
- }
- /**
- *计算数据按照不同方式划分的熵
- *
- *@paramremainData
- *剩余的数据
- *@paramattrName
- *待划分的属性,在算信息增益的时候会使用到
- *@paramattrValue
- *划分的子属性值
- *@paramisParent
- *是否分子属性划分还是原来不变的划分
- */
- privatedoublecomputeEntropy(String[][]remainData,StringattrName,
- Stringvalue,booleanisParent){
- //实例总数
- inttotal=0;
- //正实例数
- intposNum=0;
- //负实例数
- intnegNum=0;
- //还是按列从左往右遍历属性
- for(intj=1;j<attrNames.length;j++){
- //找到了指定的属性
- if(attrName.equals(attrNames[j])){
- for(inti=1;i<remainData.length;i++){
- //如果是父结点直接计算熵或者是通过子属性划分计算熵,这时要进行属性值的过滤
- if(isParent
- ||(!isParent&&remainData[i][j].equals(value))){
- if(remainData[i][attrNames.length-1].equals(YES)){
- //判断此行数据是否为正实例
- posNum++;
- }else{
- negNum++;
- }
- }
- }
- }
- }
- total=posNum+negNum;
- doubleposProbobly=(double)posNum/total;
- doublenegProbobly=(double)negNum/total;
- if(posProbobly==1||posProbobly==0){
- //如果数据全为同种类型,则熵为0,否则带入下面的公式会报错
- return0;
- }
- doubleentropyValue=-posProbobly*Math.log(posProbobly)
- /Math.log(2.0)-negProbobly*Math.log(negProbobly)
- /Math.log(2.0);
- //返回计算所得熵
- returnentropyValue;
- }
- /**
- *为某个属性计算信息增益
- *
- *@paramremainData
- *剩余的数据
- *@paramvalue
- *待划分的属性名称
- *@return
- */
- privatedoublecomputeGain(String[][]remainData,Stringvalue){
- doublegainValue=0;
- //源熵的大小将会与属性划分后进行比较
- doubleentropyOri=0;
- //子划分熵和
- doublechildEntropySum=0;
- //属性子类型的个数
- intchildValueNum=0;
- //属性值的种数
- ArrayList<String>attrTypes=attrValue.get(value);
- //子属性对应的权重比
- HashMap<String,Integer>ratioValues=newHashMap<>();
- for(inti=0;i<attrTypes.size();i++){
- //首先都统一计数为0
- ratioValues.put(attrTypes.get(i),0);
- }
- //还是按照一列,从左往右遍历
- for(intj=1;j<attrNames.length;j++){
- //判断是否到了划分的属性列
- if(value.equals(attrNames[j])){
- for(inti=1;i<=remainData.length-1;i++){
- childValueNum=ratioValues.get(remainData[i][j]);
- //增加个数并且重新存入
- childValueNum++;
- ratioValues.put(remainData[i][j],childValueNum);
- }
- }
- }
- //计算原熵的大小
- entropyOri=computeEntropy(remainData,value,null,true);
- for(inti=0;i<attrTypes.size();i++){
- doubleratio=(double)ratioValues.get(attrTypes.get(i))
- /(remainData.length-1);
- childEntropySum+=ratio
- *computeEntropy(remainData,value,attrTypes.get(i),false);
- //System.out.println("ratio:value:"+ratio+""+
- //computeEntropy(remainData,value,
- //attrTypes.get(i),false));
- }
- //二者熵相减就是信息增益
- gainValue=entropyOri-childEntropySum;
- returngainValue;
- }
- /**
- *计算信息增益比
- *
- *@paramremainData
- *剩余数据
- *@paramvalue
- *待划分属性
- *@return
- */
- privatedoublecomputeGainRatio(String[][]remainData,Stringvalue){
- doublegain=0;
- doublespiltInfo=0;
- intchildValueNum=0;
- //属性值的种数
- ArrayList<String>attrTypes=attrValue.get(value);
- //子属性对应的权重比
- HashMap<String,Integer>ratioValues=newHashMap<>();
- for(inti=0;i<attrTypes.size();i++){
- //首先都统一计数为0
- ratioValues.put(attrTypes.get(i),0);
- }
- //还是按照一列,从左往右遍历
- for(intj=1;j<attrNames.length;j++){
- //判断是否到了划分的属性列
- if(value.equals(attrNames[j])){
- for(inti=1;i<=remainData.length-1;i++){
- childValueNum=ratioValues.get(remainData[i][j]);
- //增加个数并且重新存入
- childValueNum++;
- ratioValues.put(remainData[i][j],childValueNum);
- }
- }
- }
- //计算信息增益
- gain=computeGain(remainData,value);
- //计算分裂信息,分裂信息度量被定义为(分裂信息用来衡量属性分裂数据的广度和均匀):
- for(inti=0;i<attrTypes.size();i++){
- doubleratio=(double)ratioValues.get(attrTypes.get(i))
- /(remainData.length-1);
- spiltInfo+=-ratio*Math.log(ratio)/Math.log(2.0);
- }
- //计算机信息增益率
- returngain/spiltInfo;
- }
- /**
- *利用源数据构造决策树
- */
- privatevoidbuildDecisionTree(AttrNodenode,StringparentAttrValue,
- String[][]remainData,ArrayList<String>remainAttr,booleanisID3){
- node.setParentAttrValue(parentAttrValue);
- StringattrName="";
- doublegainValue=0;
- doubletempValue=0;
- //如果只有1个属性则直接返回
- if(remainAttr.size()==1){
- System.out.println("attrnull");
- return;
- }
- //选择剩余属性中信息增益最大的作为下一个分类的属性
- for(inti=0;i<remainAttr.size();i++){
- //判断是否用ID3算法还是C4.5算法
- if(isID3){
- //ID3算法采用的是按照信息增益的值来比
- tempValue=computeGain(remainData,remainAttr.get(i));
- }else{
- //C4.5算法进行了改进,用的是信息增益率来比,克服了用信息增益选择属性时偏向选择取值多的属性的不足
- tempValue=computeGainRatio(remainData,remainAttr.get(i));
- }
- if(tempValue>gainValue){
- gainValue=tempValue;
- attrName=remainAttr.get(i);
- }
- }
- node.setAttrName(attrName);
- ArrayList<String>valueTypes=attrValue.get(attrName);
- remainAttr.remove(attrName);
- AttrNode[]childNode=newAttrNode[valueTypes.size()];
- String[][]rData;
- for(inti=0;i<valueTypes.size();i++){
- //移除非此值类型的数据
- rData=removeData(remainData,attrName,valueTypes.get(i));
- childNode[i]=newAttrNode();
- booleansameClass=true;
- ArrayList<String>indexArray=newArrayList<>();
- for(intk=1;k<rData.length;k++){
- indexArray.add(rData[k][0]);
- //判断是否为同一类的
- if(!rData[k][attrNames.length-1]
- .equals(rData[1][attrNames.length-1])){
- //只要有1个不相等,就不是同类型的
- sameClass=false;
- break;
- }
- }
- if(!sameClass){
- //创建新的对象属性,对象的同个引用会出错
- ArrayList<String>rAttr=newArrayList<>();
- for(Stringstr:remainAttr){
- rAttr.add(str);
- }
- buildDecisionTree(childNode[i],valueTypes.get(i),rData,
- rAttr,isID3);
- }else{
- //如果是同种类型,则直接为数据节点
- childNode[i].setParentAttrValue(valueTypes.get(i));
- childNode[i].setChildDataIndex(indexArray);
- }
- }
- node.setChildAttrNode(childNode);
- }
- /**
- *属性划分完毕,进行数据的移除
- *
- *@paramsrcData
- *源数据
- *@paramattrName
- *划分的属性名称
- *@paramvalueType
- *属性的值类型
- */
- privateString[][]removeData(String[][]srcData,StringattrName,
- StringvalueType){
- String[][]desDataArray;
- ArrayList<String[]>desData=newArrayList<>();
- //待删除数据
- ArrayList<String[]>selectData=newArrayList<>();
- selectData.add(attrNames);
- //数组数据转化到列表中,方便移除
- for(inti=0;i<srcData.length;i++){
- desData.add(srcData[i]);
- }
- //还是从左往右一列列的查找
- for(intj=1;j<attrNames.length;j++){
- if(attrNames[j].equals(attrName)){
- for(inti=1;i<desData.size();i++){
- if(desData.get(i)[j].equals(valueType)){
- //如果匹配这个数据,则移除其他的数据
- selectData.add(desData.get(i));
- }
- }
- }
- }
- desDataArray=newString[selectData.size()][];
- selectData.toArray(desDataArray);
- returndesDataArray;
- }
- /**
- *开始构建决策树
- *
- *@paramisID3
- *是否采用ID3算法构架决策树
- */
- publicvoidstartBuildingTree(booleanisID3){
- readDataFile();
- initAttrValue();
- ArrayList<String>remainAttr=newArrayList<>();
- //添加属性,除了最后一个类标号属性
- for(inti=1;i<attrNames.length-1;i++){
- remainAttr.add(attrNames[i]);
- }
- AttrNoderootNode=newAttrNode();
- buildDecisionTree(rootNode,"",data,remainAttr,isID3);
- showDecisionTree(rootNode,1);
- }
- /**
- *显示决策树
- *
- *@paramnode
- *待显示的节点
- *@paramblankNum
- *行空格符,用于显示树型结构
- */
- privatevoidshowDecisionTree(AttrNodenode,intblankNum){
- System.out.println();
- for(inti=0;i<blankNum;i++){
- System.out.print("\t");
- }
- System.out.print("--");
- //显示分类的属性值
- if(node.getParentAttrValue()!=null
- &&node.getParentAttrValue().length()>0){
- System.out.print(node.getParentAttrValue());
- }else{
- System.out.print("--");
- }
- System.out.print("--");
- if(node.getChildDataIndex()!=null
- &&node.getChildDataIndex().size()>0){
- Stringi=node.getChildDataIndex().get(0);
- System.out.print("类别:"
- +data[Integer.parseInt(i)][attrNames.length-1]);
- System.out.print("[");
- for(Stringindex:node.getChildDataIndex()){
- System.out.print(index+",");
- }
- System.out.print("]");
- }else{
- //递归显示子节点
- System.out.print("【"+node.getAttrName()+"】");
- for(AttrNodechildNode:node.getChildAttrNode()){
- showDecisionTree(childNode,2*blankNum);
- }
- }
- }
- }
- /**
- *ID3决策树分类算法测试场景类
- *@authorlyq
- *
- */
- publicclassClient{
- publicstaticvoidmain(String[]args){
- StringfilePath="C:\\Users\\lyq\\Desktop\\icon\\input.txt";
- ID3Tooltool=newID3Tool(filePath);
- tool.startBuildingTree(true);
- }
- }
- ------【OutLook】
- --Sunny--【Humidity】
- --High--类别:No[1,2,8,]
- --Normal--类别:Yes[9,11,]
- --Overcast--类别:Yes[3,7,12,13,]
- --Rainy--【Wind】
- --Weak--类别:Yes[4,5,10,]
- --Strong--类别:No[6,14,]
请从左往右观察这棵决策树,【】里面的是分类属性,---XXX----,XXX为属性的值,在叶子节点处为类标记。
对应的分类结果图:

这里的构造决策树和显示决策树采用的DFS的方法,所以可能会比较难懂,希望读者能细细体会,可以调试一下代码,一步步的跟踪会更加容易理解的。
三、C4.5算法
如果你已经理解了上面ID3算法的实现,那么理解C4.5也很容易了,C4.5与ID3在核心的算法是一样的,但是有一点所采用的办法是不同的,C4.5采用了信息增益率作为划分的根据,克服了ID3算法中采用信息增益划分导致属性选择偏向取值多的属性。信息增益率的公式为:
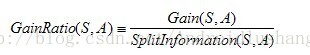
分母的位置是分裂因子,他的计算公式为:
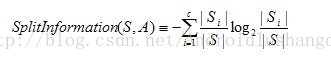
和熵的计算公式比较像,具体的信息增益率的算法也在上面的代码中了,请关注着2个方法:
- //选择剩余属性中信息增益最大的作为下一个分类的属性
- for(inti=0;i<remainAttr.size();i++){
- //判断是否用ID3算法还是C4.5算法
- if(isID3){
- //ID3算法采用的是按照信息增益的值来比
- tempValue=computeGain(remainData,remainAttr.get(i));
- }else{
- //C4.5算法进行了改进,用的是信息增益率来比,克服了用信息增益选择属性时偏向选择取值多的属性的不足
- tempValue=computeGainRatio(remainData,remainAttr.get(i));
- }
- if(tempValue>gainValue){
- gainValue=tempValue;
- attrName=remainAttr.get(i);
- }
- }
1、在构造决策树的过程中能对树进行剪枝。
2、能对连续性的值进行离散化的操作。
四、编码时遇到的一些问题
为了实现ID3算法,从理解阅读他的原理就已经用掉了比较多的时间,然后再尝试阅读别人写的C++版本的代码,又是看了几天,好不容易实现了2个算法,最后在构造树的过程中遇到了最大了麻烦,因为用到了递归构造树,对于其中节点的设计就显得至关重要了,也许我自己目前的设计也不是最优秀的。下面盘点一下我的程序的遇到的一些问题和存在的潜在的问题:
1、在构建决策树的时候,出现了remainAttr值缺少的情况,就是递归的时候remainAttr的属性划分移除掉之后,对于上次的递归操作的属性时受到影响了,后来发现是因为我remainAttr采用的是ArrayList,他是一个引用对象,通过引用传入的方式,对象用的还是同一个,所以果断重新建了一个ArrayList对象,问题就OK了。
- //创建新的对象属性,对象的同个引用会出错
- ArrayList<String>rAttr=newArrayList<>();
- for(Stringstr:remainAttr){
- rAttr.add(str);
- }
- buildDecisionTree(childNode[i],valueTypes.get(i),rData,
- rAttr,isID3);
- privatevoidbuildDecisionTree(AttrNodenode,StringparentAttrValue,
- String[][]remainData,ArrayList<String>remainAttr,booleanisID3){
- node.setParentAttrValue(parentAttrValue);
- StringattrName="";
- doublegainValue=0;
- doubletempValue=0;
- //如果只有1个属性则直接返回
- if(remainAttr.size()==1){
- System.out.println("attrnull");
- return;
- }
- .....















 5040
5040

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









