






# 在本地部署python环境
cd /app/
python -m venv myenv
# 激活虚拟环境
source /app/myenv/activate
# 要撤销激活一个虚拟环境,请输入:
deactivate
# 进入虚拟环境安装modelscope
pip install modelscope
# 下载大模型(7B为例)
modelscope download --model deepseek-ai/DeepSeek-R1-Distill-Qwen-7B --local_dir /app/deepseek/models/deepseek-7b
# 运行vllm容器,这里直接进入容器bash终端,不直接启动服务
docker run -it --gpus '"device=7"' --shm-size 10.24g\
-v /app/deepseek/models:/models \
-p 8000:8000 \
--ipc=host \
--name vllm_deepseek \
--entrypoint /bin/bash \
vllm/vllm-openai:v0.7.3
# 启动服务
python3 -m vllm.entrypoints.openai.api_server --model /models/deepseek-7b --port 8000 --tensor-parallel-size 1 --served-model-name DeepSeek-R1-7B --gpu-memory-utilization 0.9 --max-model-len 8192 --trust-remote-code --enforce_eager
## 参数说明:
--model 指定模型参数目录
--tensor-parallel-size 指定gpu数
--served-model-name 模型命名
--port 指定端口
--max-model-len 指定大模型的最大输出长度
# 另外起open-webui容器服务
docker run -it --rm -p 8080:8080 \
-v /app/open-webui/data:/app/backend/data \
--add-host=host.docker.internal:host-gateway \
-e ENABLE_OLLAMA_API=False \
--name open-webui\
ghcr.io/open-webui/open-webui:main
测试api:
# 测试api
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "DeepSeek-R1-7B",
"messages": [
{
"role": "user",
"content": "你是谁?"
}
]
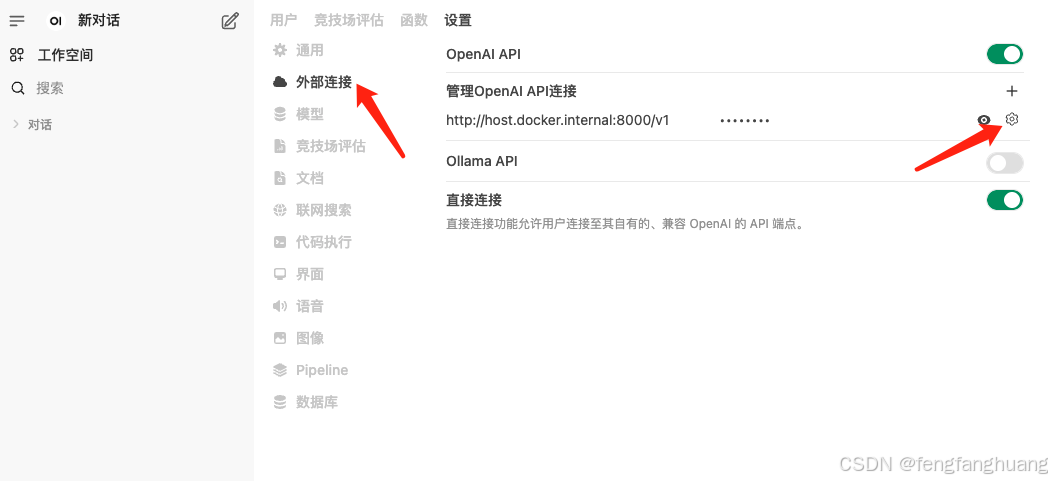
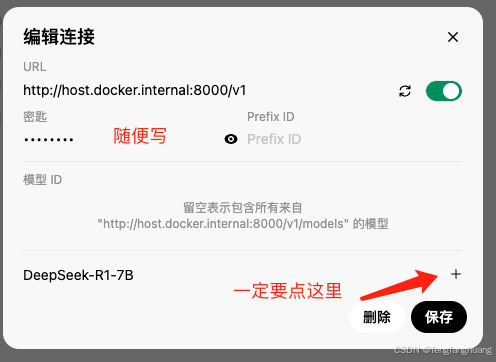
}'open-webui接入openai api
访问http://主机IP:8080


















 6081
6081

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









