







消费者组
- 消费能力不足时,可以在消费者组,扩展消费者
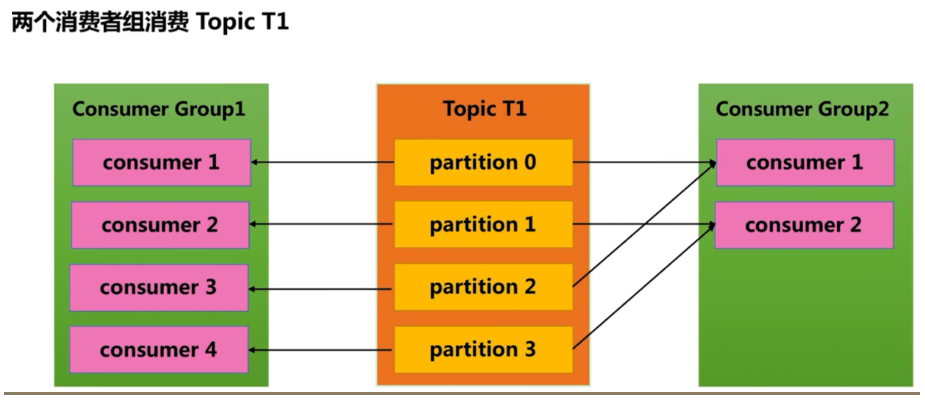
- 一个topic 可以被多个消费者组消费
- 消费者是消费组的一部分。消费组保证每个分区只能被一个消费者使用,避免重复消费
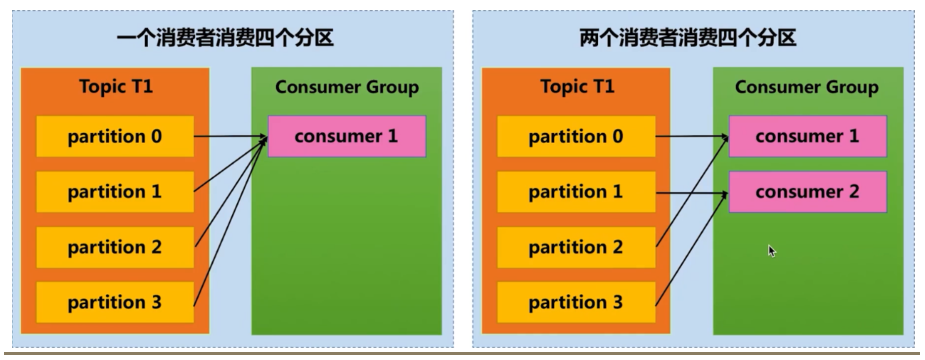
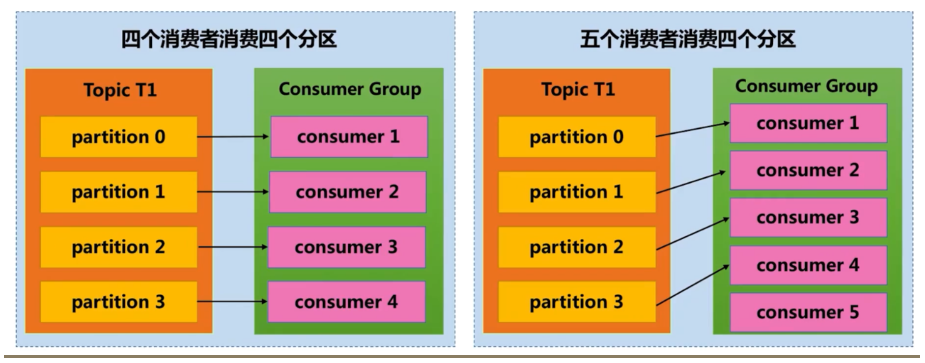
- 单个Partition只能由消费者组中某个消费者消费
- 消费者数量不应该大于主题的分区数量,因为没有意义
- 消费者都隶属于同一个消费组,相当于点对点模型
- 消费者都隶属于不同的消费组,相当于发布/订阅模式的应用
分区与消费者组关系
重平衡
- 特别耗性能,所以能不做就不做
- 重平衡操作会正消费者暂停消费。什么也干不了,影响吞吐
触发时机
- 新增或删除消费者
- 消费者订阅的主题信息发生变化
- 主题的分区发生了变化
避免
- session.timout.ms:控制心跳超时时间
- heartbeat.interval.ms:控制发送心跳的频率,频率越高越不容易被误判,但也会消耗更多资源
- max.poll.interval.ms:控制poll的间隔
消费者poll数据后,需要一些处理,再进行拉取
如果两次拉取时间间隔超过这个参数设置的值,那么消费者就会被踢出消费者组
默认值是5分钟,而如果消费者接收到数据后会执行耗时的操作,则应该将其设置得大一些
推荐设置
- session.timout.ms:设置为6s
- heartbeat.interval.ms:设置2s
- max.poll.interval.ms:推荐为消费者处理消息最长耗时再加1分钟
导致的重复消费
Consumer 每 5s 提交 offset
假设提交 offset 后的 3s 发生了 Rebalance
Rebalance 之后的所有 Consumer 从上一次提交的 offset 处继续消费
因此 Rebalance 发生前 3s 的消息会被重复消费
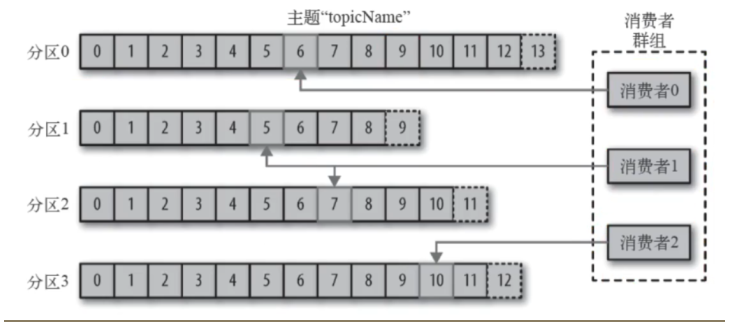
offset
- 由于consumer在消费过程中可能会出现断电宕机等故障,consumer恢复后,需要从故障前的位置的继续消费,所以consumer需要实时记录自己消费到了哪个offset,以便故障恢复后继续消费。
- __consumer_offsets主题中保存各个消费组的偏移量。
- 位移是提交到Kafka中的 __consumer_offsets 主题。 __consumer_offsets 中的消息保存了每个消费组某一时刻提交的offset信息。配置了compact策略,使得它总是能够保存最新的位移信息,既控制 了该topic总体的日志容量,也能实现保存最新offset的目的。
- 消费者通过偏移量来区分已经读过的消息,从而消费消息















 1070
1070

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









