







线性回归
按机器学习,线性回归模型方程式:
y’=w1*x1+b
其中:
y′ 指的是预测标签(理想输出值)。
b 指的是偏差(y 轴截距)。而在一些机器学习文档中,它称为 w0。
w1 指的是特征 1 的权重。权重与线性函数中的“斜率”的概念相同。
x1 指的是特征(已知输入项)。
该式表示有一个特征的方程式,具有三个特征的模型可以采用以下方程式:
y’=b+w1x1+w2x2+w3*x3
训练与损失
训练模型表示通过有标签样本来学习(确定)所有权重和偏差的理想值
训练模型的目标是从所有样本中找到一组平均损失“较小”的权重和偏差
损失函数:平方损失
一般线性回归模型使用的是一种称为平方损失(又称为 L2 损失)的损失函数:
loss=(y-y’)2
均方误差 (MSE) 指的是每个样本的平均平方损失。要计算 MSE,请求出各个样本的所有平方损失之和,然后除以样本数量:
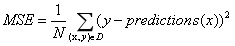
其中:
(x,y) 指的是样本,其中
- x 指的是模型进行预测时使用的特征集(例如,温度、年龄和交配成功率)。
- y 指的是样本的标签(例如,每分钟的鸣叫次数)。
prediction(x) 指的是权重和偏差与特征集 x 结合的函数。
D 指的是包含多个有标签样本(即 (x,y))的数据集。
N 指的是 D 中的样本数量。















 229
229











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









