










在当今的大数据时代,高效的数据检索和分析能力已成为许多应用程序的核心需求。Elasticsearch,作为一款强大的分布式搜索和分析引擎,正是为了满足这些需求而诞生的。它之所以能够在海量数据中实现毫秒级的搜索响应,以及灵活的数据分析,要归功于其内部精妙的数据结构和机制。本文将详细探讨Elasticsearch中的行存储(Stored Fields)、列存储(Doc Values)和倒排索引(Inverted Index)这三种关键组件,并解释它们是如何协同工作的。
目录
1、 什么是行存
在Lucene中索引文档时,原始字段信息经过分词、转换处理后形成倒排索引,而原始内容本身并不直接保留。因此,为了检索时能够获取到字段的原始值,我们需要依赖额外的数据结构。Lucene提供了两种解决方案:Stored Field和doc_values。
Stored Field的设计初衷就是为了存储那些未经分词的字段原始值。这样,在执行查询操作时,除了能够获取到文档ID之外,我们还能够方便地检索到这些原始字段信息。
es中每个文档都被视为一个JSON对象,包含多个字段。当文档被索引时,其原始数据或特定字段可以被存储在es中,以便后续能够检索到原始的字段值。这种存储方式类似于传统的行存储数据库,因为它存储了每个文档的所有字段。
然而,需要注意的是,es并不建议大量使用Stored Fields。这是因为存储原始字段值会增加磁盘使用量,并可能降低性能。相反,es更倾向于使用Doc Values和倒排索引来高效地检索和分析数据。因此,Stored Fields通常只用于存储那些需要在搜索结果中直接返回的字段。
2、 使用场景
那么,什么时候应该使用Stored Fields呢?
- 需要返回原始字段值:如果你的应用程序需要在搜索结果中返回文档的原始字段值,那么你应该将这些字段设置为Stored Fields。例如,你可能需要显示给用户文档的标题、描述或内容等字段。
- 不支持Doc Values的字段类型:并非所有字段类型都支持Doc Values。对于那些不支持Doc Values的字段类型,如果你需要在搜索结果中返回这些字段的值,那么你需要将它们设置为Stored Fields。
3、 如何使用
可以通过映射(Mapping)来定义哪些字段应该被存储为Stored Fields。映射是定义文档结构和字段属性的过程。
3.1 定义store字段
PUT order
{
"mappings": {
"_doc": {
"properties": {
"counter": {
"type": "integer",
"store": false //默认值就是false
},
"tags": {
"type": "keyword",
"store": true //修改值为true
}
}
}
}
}
我们创建了一个名为order的索引,并定义了两个字段:counter和tags。我们将tags字段的store属性设置为true,这意味着tags字段的值将被存储为Stored Fields。而counter字段的store属性设置为false,表示不存储该字段的值。
3.2 添加 document
PUT order/_doc/1
{
"counter" : 1,
"tags" : ["red"]
}
3.3 尝试带stored_fields参数去检索
GET twitter/_doc/1?stored_fields=tags,counter
以上get操作的结果是:
{
"_index": "twitter",
"_type": "tweet",
"_id": "1",
"_version": 1,
"found": true,
"fields": { //此时多了名称为fields的字段,并且没有了_source
"tags": [ //tags的stroe属性设置为true,因此显示在结果中
"red"
]
}
}
从 document 中获取的字段的值通常是array。
由于counter字段没有存储,当尝试获取stored_fields时get会将其忽略。
在Elasticsearch中,不论将字段的store属性设置为true还是false,这些字段都会被存储。但存储的方式有所不同:
- 当store设置为false时(这是默认配置),字段值仅存储在文档的_source字段中。这意味着,字段值作为整个文档JSON结构体的一部分被保存。
- 当store设置为true时,字段值不仅存储在_source字段中,还会被单独存储在一个与_source平级的独立字段中。这样,该字段就有了两份拷贝:一份在_source中,另一份在独立的字段中。
那么,在什么情况下需要将字段的store属性设置为true呢?通常有两种情况:
- _source字段在索引的映射中被禁用(disabled)
在这种情况下,如果某个字段没有被定义为store=true,那么该字段将不会出现在查询结果中。因此,为了确保能够在查询结果中访问这些字段,需要将其设置为store=true。 - _source字段的内容非常大
当文档包含大量数据时,例如一本书的内容,而查询时只需要访问其中的部分字段(如标题和日期),而不是整个_source字段,那么将这些字段设置为store=true可以提高查询效率。这样做可以避免在查询时解释整个_source字段,从而减少开销。当然,另一种选择是使用source filtering来减少网络开销,但将特定字段设置为store=true也是一种有效的优化方法。
4、 行存储与_source字段
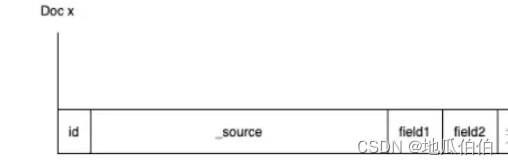
行存储中,占比最大的通常是_source字段,它负责保存文档的原始数据。在数据写入阶段,Elasticsearch会将整个文档的JSON结构体作为字符串存储在_source字段中。在查询时,我们可以通过_source字段检索到原始写入的完整JSON结构体。
{
"_index": "order",
"_type": "_doc",
"_id": "1",
"_version": 1,
"_seq_no": 0,
"_primary_term": 1,
"found": true,
"_source": { //默认查询数据,返回的属性字段都在_source中
"user": "kimchy",
"post_date": "2009-11-15T14:12:12",
"message": "trying out Elasticsearch"
}
}
4.1 _source字段
- _source字段的角色:在Elasticsearch中,每个索引的文档都有一个特殊的字段叫做_source。这个字段包含了文档的原始JSON表示。当你索引一个文档时,Elasticsearch会将这个文档的JSON形式存储为_source字段的内容。这意味着,无论你的文档包含什么字段(例如,标题、描述、日期等),它们都会被打包进这个_source字段中。
- 存储与检索:由于_source字段存储了文档的完整原始数据,因此它通常是索引中最大的字段之一。当你执行一个检索操作时,Elasticsearch默认会返回匹配文档的_source字段,从而允许你访问到文档的原始数据。
- 用途:拥有文档的原始数据非常有用,特别是在你需要重新构建文档的上下文时(例如,在搜索结果中显示文档的内容)。此外,许多Elasticsearch的功能,如高亮显示或字段提取,都依赖于_source字段的内容。
4.2 优化_source字段的使用
- 关闭_source:如果你确定不需要文档的原始数据,可以在索引的映射中关闭_source字段的存储。这样做可以节省存储空间并提高索引速度。然而,这样做有一个重要的限制:关闭_source字段后,你将无法使用update、update_by_query和reindex等API,因为这些操作需要访问文档的原始数据。
- 包含/排除字段:另一种优化方法是选择性地包含或排除_source字段中的某些数据。例如,你可能只想存储文档的某些关键字段,而不是整个JSON结构体。这可以通过在索引文档时使用特定的参数或在映射中定义_source字段的包含/排除规则来实现。
4.3 注意事项
- 在决定关闭_source字段或修改其包含的内容之前,务必仔细考虑你的应用程序的需求。如果你在未来需要使用文档的原始数据,或者需要使用依赖于_source字段的Elasticsearch功能,那么关闭或修改_source字段可能会导致问题。
- 尽管关闭_source字段可以节省存储空间,但这通常不是优化Elasticsearch性能的首选方法。在大多数情况下,通过优化查询、选择合适的分析器、合理设置映射和使用硬件资源等方式,可以获得更好的性能提升。
5、 总结
行存储有几个重要的优点:
- 完整性:由于_source字段存储了文档的完整原始数据,因此可以重新构建文档的上下文,这对于搜索结果展示、高亮显示等功能至关重要。
- 灵活性:拥有文档的原始数据使得ES能够提供多种功能,如字段提取、动态映射更改等,这些功能都依赖于_source字段的内容。
- 便于调试:对于开发者而言,能够直接访问文档的原始数据有助于调试和验证索引的正确性。
然而,行存储也有一些潜在的开销和限制:
- 存储成本:由于每个文档的完整原始数据都被存储在索引中,这可能会增加存储空间的需求,尤其是对于大量文档或大型文档而言。
- 写入性能:在写入大量文档时,将每个文档的完整JSON结构体存储到_source字段可能会对写入性能产生一定的影响。
在使用ES时,开发者需要根据具体的应用场景和需求来权衡行存储的利弊,并合理地配置和优化索引结构。例如,在某些场景下,可能只需要存储文档的部分字段而不是完整的JSON结构体,这可以通过在映射中关闭_source字段或只包含必要的字段来实现。然而,需要注意的是,关闭_source字段后将无法使用依赖于_source字段的ES功能,如更新、重新索引等。因此,在做出决策时需要仔细考虑。

















 1048
1048











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











