







根据字符出现频率排序的思路探讨与源码
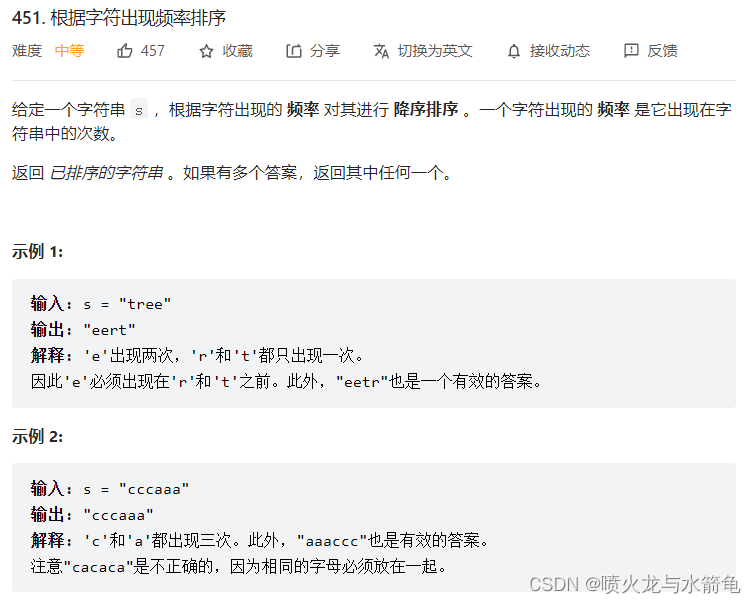
根据字符出现频率排序的题目如下图,该题属于哈希表类型和排序类型的题目,主要考察对于排序方法的使用和哈希表结构的理解。本文的题目作者想到2种方法,分别是桶排序方法和普通排序方法,其中桶排序方法使用Java进行编写,而普通排序方法使用Python进行编写,当然这可能不是最优的解法,还希望各位大佬给出更快的算法。
本人认为该题目可以使用桶排序方法的思路进行解决,首先初始化一个哈希表,并初始化参数和计算字符串的长度,开始遍历字符串并把字符出现的频率进行记录,再进行最大频率的比较后得到一个最大的频率值。初始化多个桶,并进行赋值。把字典进行遍历,获取其中的元素和频率,把元素放到对应的桶的位置里面,直到遍历结束。再对桶的数组进行遍历,获取对应元素的频率加入到结果,直到遍历结束并返回最终结果。那么按照这个思路我们的Java代码如下:
#喷火龙与水箭龟
class Solution {
public String frequencySort(String s) {
Map<Character, Integer> map = new HashMap<Character, Integer>();
int maxFreq = 0;
int lengthNum = s.length();
for (int ir = 0; ir < lengthNum; ir++) {
char c = s.charAt(ir);
int frequency = map.getOrDefault(c, 0) + 1;
map.put(c, frequency);
maxFreq = Math.max(maxFreq, frequency);
}
StringBuffer[] buckets = new StringBuffer[maxFreq + 1];
for (int ic = 0; ic <= maxFreq; ic++) {
buckets[ic] = new StringBuffer();
}
for (Map.Entry<Character, Integer> entry : map.entrySet()) {
char c = entry.getKey();
int frequency = entry.getValue();
buckets[frequency].append(c);
}
StringBuffer sbf = new StringBuffer();
for (int iv = maxFreq; iv > 0; iv--) {
StringBuffer bucket = buckets[iv];
int size = bucket.length();
for (int jv = 0; jv < size; jv++) {
for (int kv = 0; kv < iv; kv++) {
sbf.append(bucket.charAt(jv));
}
}
}
return sbf.toString();
}
}

显然,我们的桶排序方法的效果一般,还可以用普通排序方法进行解决。首先初始化一个字典,开始遍历循环字符串并把字符放入字典,并记录字符出现的频次。再将字典的值按降序进行排序,并把排序后的结果遍历后加和并获取结果,最后把最终结果进行返回。所以按照这个思路就可以解决,下面是Python代码:
#喷火龙与水箭龟
class Solution:
def frequencySort(self, s: str) -> str:
dc={}
for ir in s:
dc[ir]=dc.get(ir,0)+1
L=sorted(dc.keys(),key=lambda x:dc[x],reverse=True)
res=''
for ir in L:
res=res+ir*dc[ir]
return res

从结果来说Java版本的桶排序方法的效率一般,而Python版本的普通排序方法的速度比较不错,但应该是有更多的方法可以进一步提速的,希望朋友们能够多多指教,非常感谢。















 459
459











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









