






本文转自: 石衫的架构笔记 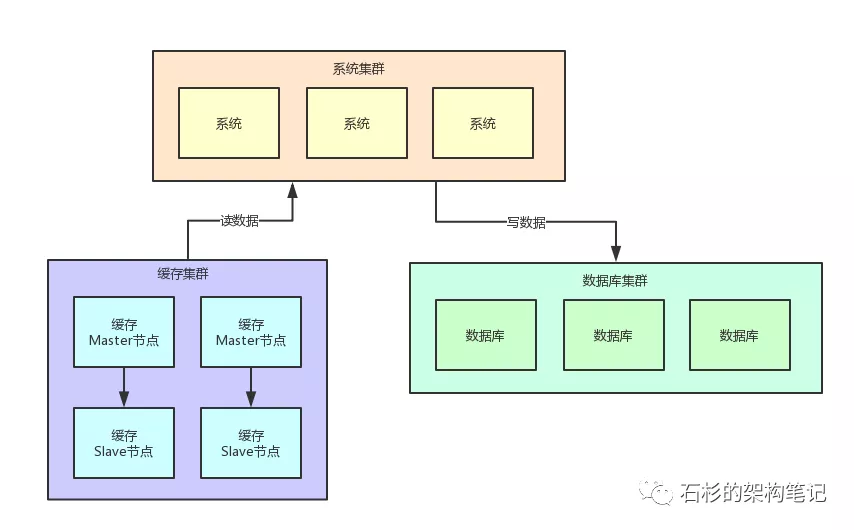
上图是我们常见的系统架构,在一般的应用系统中已经足够了 假如系统是新闻门户类网站,某天出现了一条新闻,突然出现大量的用户访问同一条缓存数据。
我们假设的是一个缓存Slave节点最多每秒就是2万的请求,当然实际缓存单机承载5万~10万读请求也是可能的,这里就是一个假设。 结果每秒突然奔过来20万请求到这台机器上,会怎么样?很简单,上面图里那台被20万请求指向的缓存机器会过度操劳而宕机的。 那么如果缓存集群开始出现机器的宕机,此时会如何? 此时读请求发现读不到数据,会从数据库里提取原始数据,然后放入剩余的其他缓存机器里去。但是接踵而来的每秒20万请求,会再次压垮其他的缓存机器。 以此类推,最终导致缓存集群全盘崩溃,引发系统整体宕机。 咱们看看下面的图,再感受一下这个恐怖的现场。
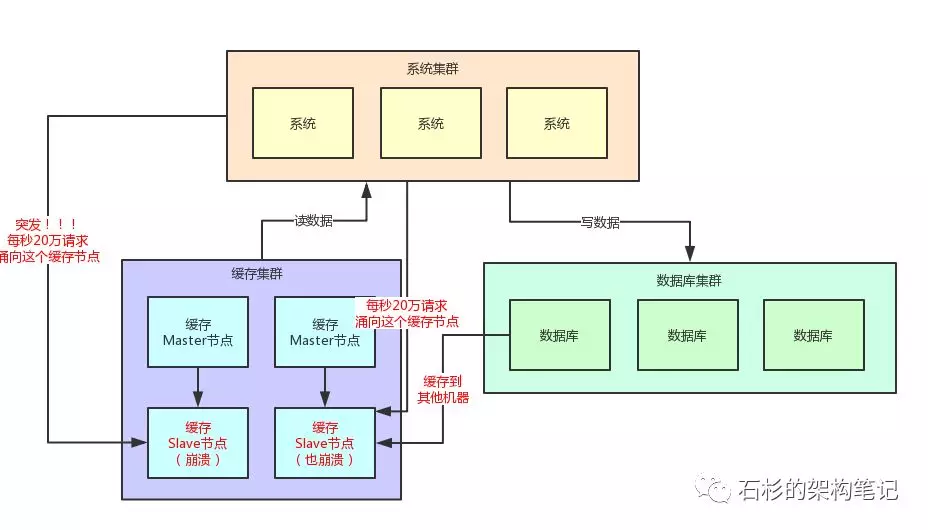
其实这里关键的一点,就是对于这种热点缓存,你的系统需要能够在热点缓存突然发生的时候,直接发现他,然后瞬间立马实现毫秒级的自动负载均衡。 那么我们就先来说说,你如何自动发现热点缓存问题? 首先你要知道,一般出现缓存热点的时候,你的每秒并发肯定是很高的,可能每秒都几十万甚至上百万的请求量过来,这都是有可能的。 所以,此时完全可以基于大数据领域的流式计算技术来进行实时数据访问次数的统计,比如storm、spark streaming、flink。 一旦在实时数据访问次数统计的过程中,比如发现一秒之内,某条数据突然访问次数超过了1000,就直接立马把这条数据判定为是热点数据,可以将这个发现出来的热点数据写入比如zookeeper中。 当然,你的系统如何判定热点数据,可以根据自己的业务还有经验值来就可以了。 大家看看下面这张图,看看整个流程是如何进行的。
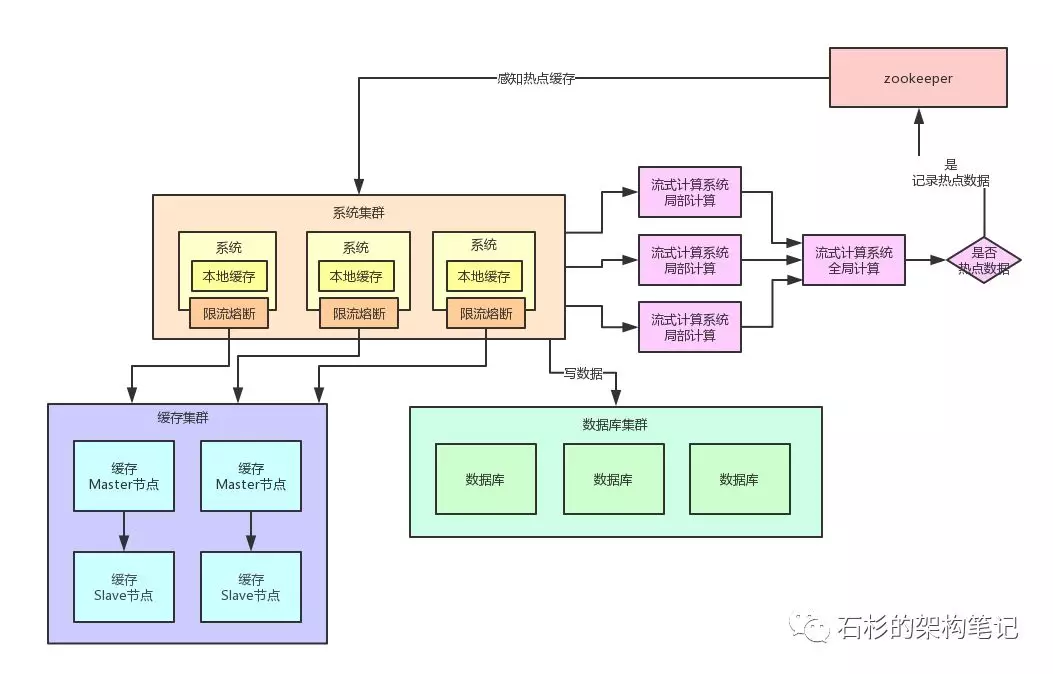
我们自己的系统可以对zookeeper指定的热点缓存对应的znode进行监听,如果有变化他立马就可以感知到了。 此时系统层就可以立马把相关的缓存数据从数据库加载出来,然后直接放在自己系统内部的本地缓存里即可。 这个本地缓存,你用ehcache、hashmap,其实都可以,一切看自己的业务需求。我们这里主要说的就是将缓存集群里的集中式缓存,直接变成每个系统自己本地实现缓存即可,每个系统本地是无法缓存过多数据的。 因为一般这种普通系统单实例部署机器可能就一个4核8G的机器,留给本地缓存的空间是很少的,所以用来放这种热点数据的本地缓存是最合适的,刚刚好。假设你的系统层集群部署了100台机器,那么好了,此时你100台机器瞬间在本地都会有一份热点缓存的副本。 然后接下来对热点缓存的读操作,直接系统本地缓存读出来就给返回了,不用再走缓存集群了。 这样的话,也不可能允许每秒20万的读请求到达缓存机器的一台机器上读一个热点缓存了,而是变成100台机器每台机器承载数千请求,那么那数千请求就直接从机器本地缓存返回数据了,这是没有问题的。 我们再来画一幅图,一起来看看这个过程:
















 2065
2065

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









