








CREATE TABLE `security_user_login_trace` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT COMMENT '主键',
`user_id` varchar(50) NOT NULL DEFAULT '' COMMENT '用户ID',
`user_account` varchar(100) DEFAULT '' COMMENT '用户账号',
`user_name` varchar(100) DEFAULT NULL COMMENT '用户姓名',
`user_phone` varchar(100) DEFAULT NULL COMMENT '用户手机号码',
`shop_code` varchar(100) DEFAULT NULL COMMENT '用户店铺Code',
PRIMARY KEY (`id`),
KEY `IDX_SHOP_CODE` (`shop_code`)
) ENGINE = InnoDB AUTO_INCREMENT = 1298491 DEFAULT CHARSET = utf8
explain select count(*) from ( select * from security_user_login_trace where 1 = 1 and shop_code in ('IN000000') ) tmp_count
这个SQL是一个分页的接口,分页查询前会先对结果数量进行count计数,但是这条SQL却成了慢SQL
在这里插入图片描述
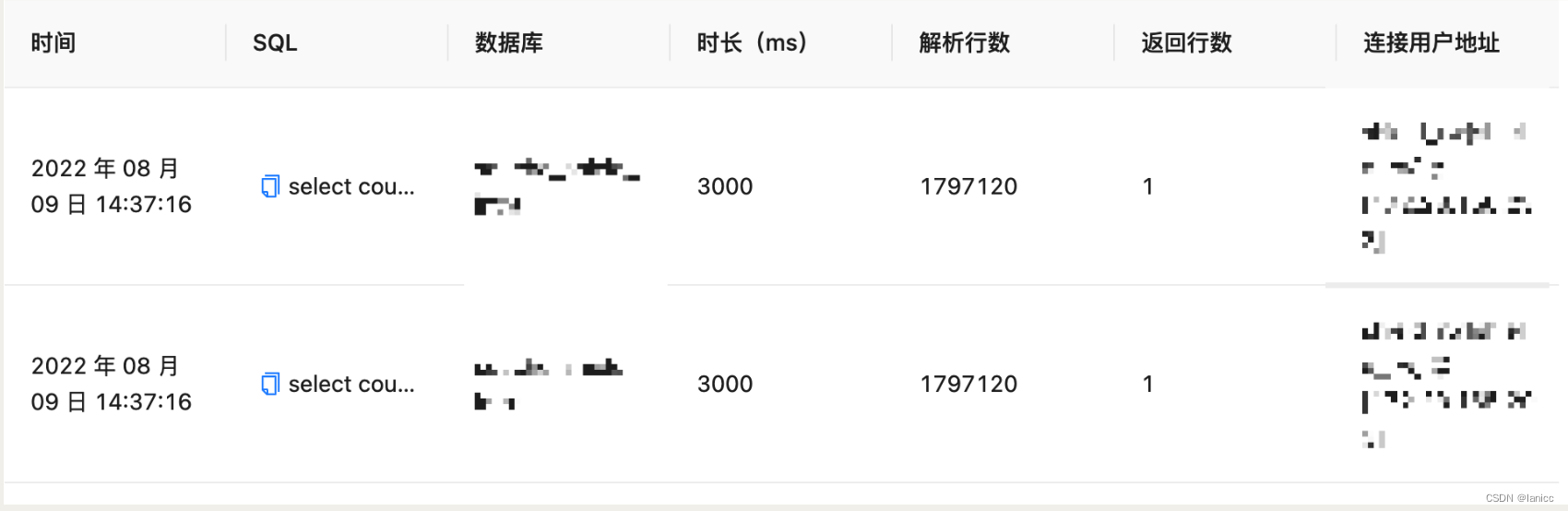
如上图,解析的行数就是全表数据。
但是这条SQL的执行计划却是

即select * from security_user_login_trace where 1 = 1 and shop_code in ('IN000000')在执行计划中,这个sql是会使用IDX_SHOP_CODE查询的。
但是实际情况却是没有走这个索引,后来经过分析可能是因为这个shop_code对应的数据量太大,加上SQL是 SELECT * 导致MySQL放弃了二级索引,直接全表扫描。
那么这个SQL如何优化呢,其实这个SQL的主要是用来计数的,外部的count是类库生成的,不能修改,只能对子查询进行优化,优化思路:
- 使用覆盖索引机制优化,从 SELECT *,修改为 SELECT id,即
select id from security_user_login_trace - 指定索引,
select id from security_user_login_trace force index(IDX_SHOP_CODE)
最终的SQL为
select count(*) from (
select id from security_user_login_trace force index(IDX_SHOP_CODE) where 1=1 and shop_code in ('IN000000')
) tmp_count;
explain的结果释义可以参考















 412
412











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











