







UnsuperPoint阅读笔记
介绍
论文《UnsuperPoint:End-to-end Unsupervised Interest Point Detector and Descriptor》提出了一种无监督的、基于深度学习的兴趣点检测方法,可以检测出一定数量的兴趣点,并提供点的描述符。
问题:兴趣点没有明确的定义,注释者很难获得一致的标签,因此,缺乏gorundtruth使兴趣点检测器难以训练。
主要思路
用自监督的方法构建端到端的网络。图像在单应性变化后,其兴趣点位置、描述符都能与原图像匹配,利用这种关系设计自监督信号,使网络能够自主学习。
方法
兴趣点检测网络

UnsuperPoint具有多任务网络体系结构,如上图所示。Backbone为共享的主干网络,后面是多个特定任务的子模块。骨干网络将三通道彩色图像作为输入,并输出降采样的特征图。三个子模块使用各自的网络处理主干输出,分别用于得到分数(Score)、位置(Position)和描述符(Descriptor),由H/8和W/8的尺度可知,输出中的每个1*1*1、1*1*2或1*1*256的值对应一个8*8区域,即网络在每个8*8区域取0个或1个兴趣点,同时确定区域内点的位置并生成描述符。
Score子模块输出为单通道的score map,分数的数值以区间[0,1]约束,取最大的N个分数值对应的兴趣点作为结果。
Position子模块输出为双通道的position map,每个位置的两个值分别指示兴趣点在该区域中的坐标(x,y),其数值本身在[0,1]区间,首先乘以数值为8的二次采样因子得到区域内的相对坐标,然后根据区域位置映射到图像像素坐标中。
Descriptor子模块输出为256通道的descriptor map,也就是为每个区域提供一个256维的向量。可以直接把256维的向量作为兴趣点的粗略描述符,也可以对descriptor map进行插值,然后按Position模块中得到的兴趣点具体坐标获取描述符。
自监督训练框架

UnsuperPoint使用自我监督的训练框架来同时学习三个子任务,构造一个孪生网络结构,如上图所示。分支A为原图像作为输入的兴趣点网络通路。分支B中的图像通过随机单应性T在空间上进行了变换(旋转,缩放,倾斜和透视变换),然后通过随机非空间图像增强(例如亮度和噪声)来转换图像。UnsuperPoint会预测每个分支上图像上的兴趣点。分支A的图像的兴趣点位置经过T变换可以与分支B中图像的兴趣点在空间上对应,这样就能在损失函数中利用点的对应关系来训练模型。
损失函数
计算损失函数首先要从孪生网络的两个分支建立点的对应关系即点对,点对由两点间的距离确定。通过计算分支A到分支B中点的欧氏距离得到距离矩阵gij,i为分支A中点的索引,j为分支B中点的索引。定义,如果分支A中的点i为点j在分支B中的最近邻居,则这些点相对应。注意,不是每个分支A的点在分支B中都有对应点。
损失函数由4个部分组成,每项损失都有一个加权系数:
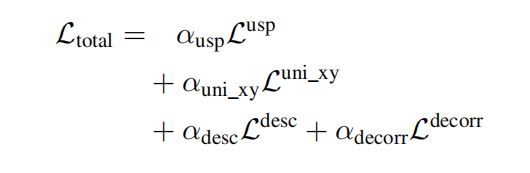
Lusp(UnSupervised Point (USP) loss)是用来学习位置和兴趣点分数的损失,具体计算如下:
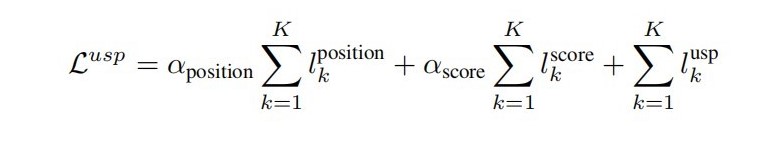
第一项lposition用来确保每个点对代表输入图像中的同一个点,直接最小化每个点对的距离来实现,即损失值等于两个点的欧氏距离。第二项lscore是为了确保每个点对的预测分数相似,通过最小化两个分数的平方距离来实现,即损失值等于两个分数的差的平方。第三项lusp是为了确保预测分数能够代表实际兴趣点的置信度,计算方式如下:
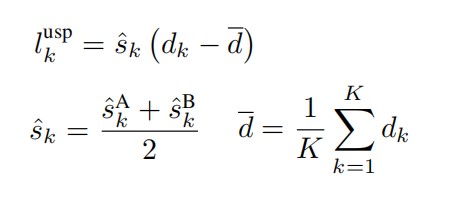
s为每个点的预测分数,d为点对距离。实质上该损失值为(点对距离-所有点对平均距离)*点对平均分数,即检测到的较好的点对应该对应较小的距离。
Luni_xy是正则化项,用于保证每个8*8区域内点对的均匀分布。下图中左边的直方图显示了检测的点大量存在于边界附近(值为0和8),这显然违背了每个区域自身找到最佳特征点的想法。因此定义D(U,V)计算均匀分布U和和某个分布V在区间[0,1]中的距离,把分布映射为一个排序向量v,D计算如下:
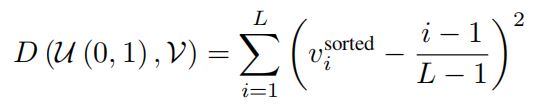
Luni_xy的值则是M个点的x和y坐标分布与均匀分布的距离和:

Ldesc用来计算描述符的损失,损失函数为铰链损失(hinge-loss),利用前面计算的分支A的点MA和分支B的点MB的距离矩阵gij得到cij,然后计算:

Ldecorr为去相关特征描述符损失,以减少过度拟合并提高紧凑性。通过最小化每个分支b的描述符相关矩阵Rb的非对角线条目来减小维度之间的相关性,v为描述符向量:

实验结果
在 MS COCO数据集上训练,在HPatch数据集上测试。使用了两种实验方案,一种是在240*320尺度的图像上找前300个兴趣点,一种是在480*640尺度的图像上找到前1000个点。
UnsuperPoint的总体性能优于SIFT等传统方法和同为深度学习方法的SuperPoint。在运行速度上,UnsuperPoint明显比其他方法快,在GPU(GeForce Titan X)环境下,240* 320图像运行速度323FPS,480*640图像运行速度90FPS。
思考
在深度学习上研究的兴趣点检测方法SuperPoint和UnsuperPoint都主要针对SLAM应用,在其他更加复杂的变化场景中不管是训练还是识别还需要探究。深度学习方法能够识别到的准确的兴趣点有限,在实验中如果不限制兴趣点的数量,可能仍然是SIFT更占优势。UnsuperPoint的描述符模块也能够单独拿出来用于传统兴趣点的匹配,从文献和个人实验得出,深度网络得到的描述符的匹配性能基本优于传统的兴趣点匹配。















 863
863











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









