










今日CS.CV 计算机视觉论文速览
Wed, 10 Jul 2019
Totally 36 papers
?上期速览✈更多精彩请移步主页

Interesting:
?***通过抽象学习的神经状态机, 研究人员提出了一种融合神经与符号表示优点的视觉识别与推理人员,与神经网络直接操作图像不同,这种方法在冲突想抽取出的隐空间上进行操作和处理,通过同时将视觉和语言模态转移到语义概念的表示上去。针对一副图像,首先预测概率图来表示隐含的语义并作为结构世界模型,随后利用序列推理不断地遍历节点来回答问题或者引出新的推理。(from 斯坦福)
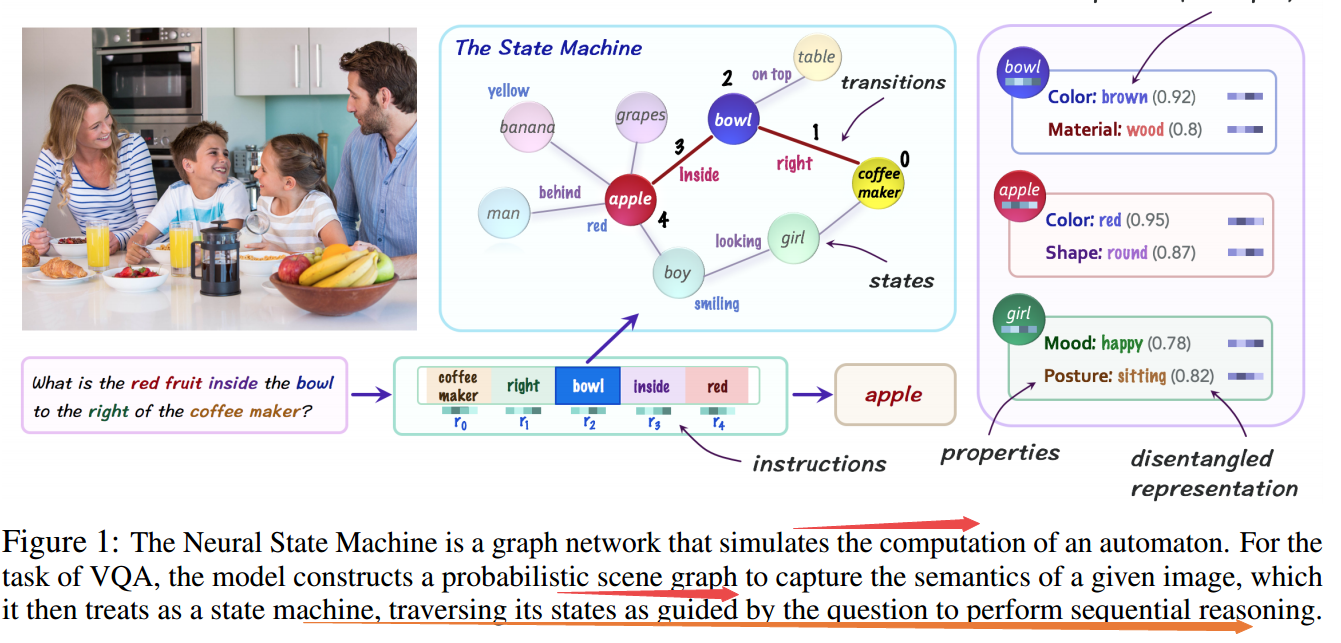
模型视觉目标掩膜:

一些问题的例子:

推理过程的实例:

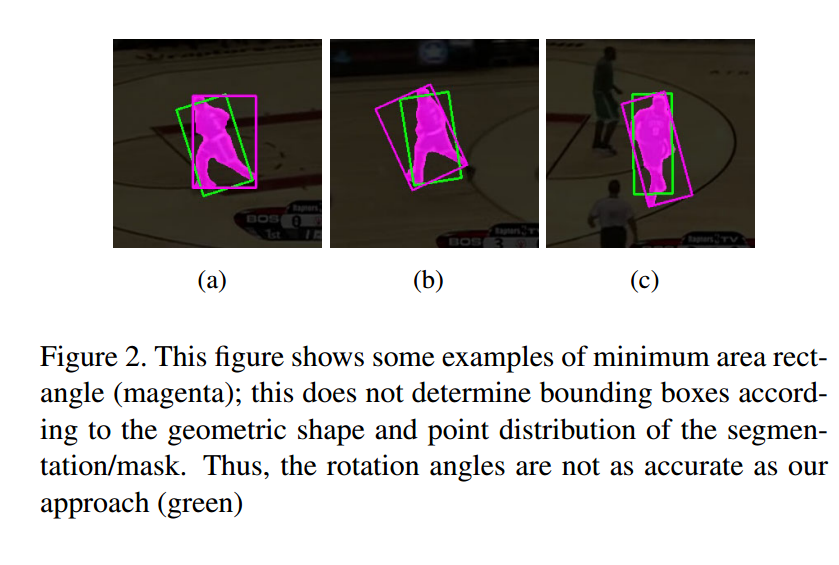
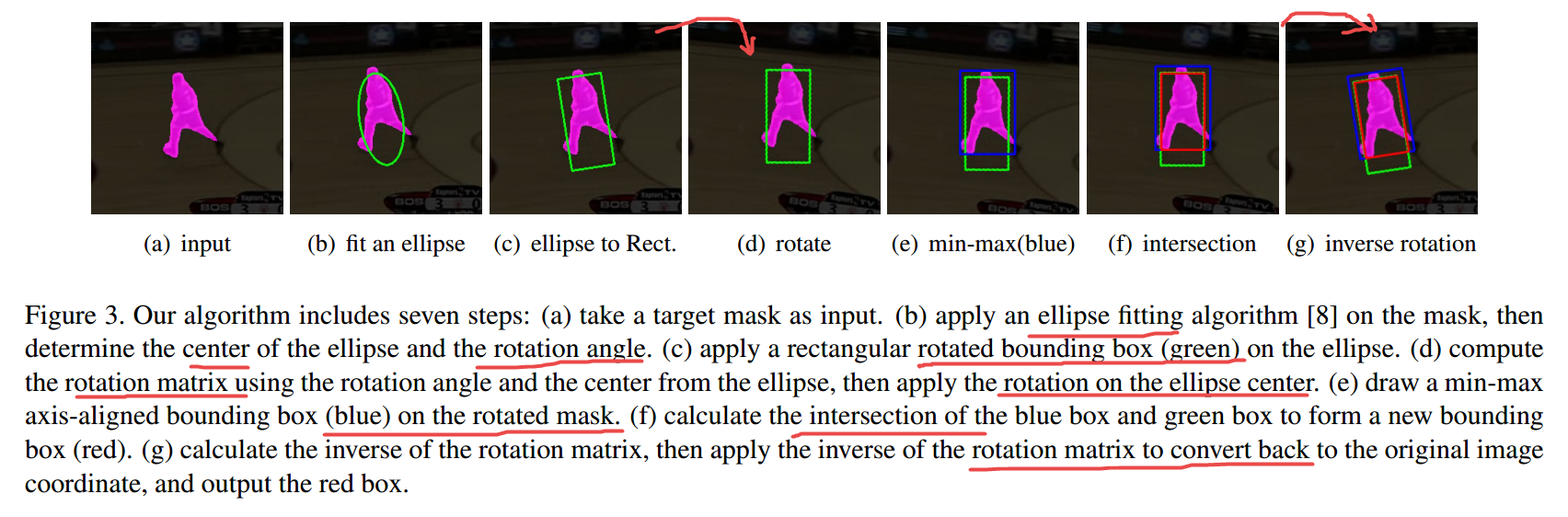
?SiamMask_E旋转矩形的目标检测方法, 提出了一种利用椭圆拟合的旋转bbox来提高目标跟踪算法的模型。(from 约克大学 CA)
算法流程:
ref:
视觉目标追踪http://www.votchallenge.net/challenges.html
code:https://github.com/STVIR/pysot
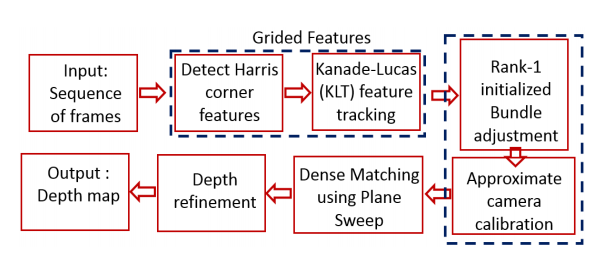
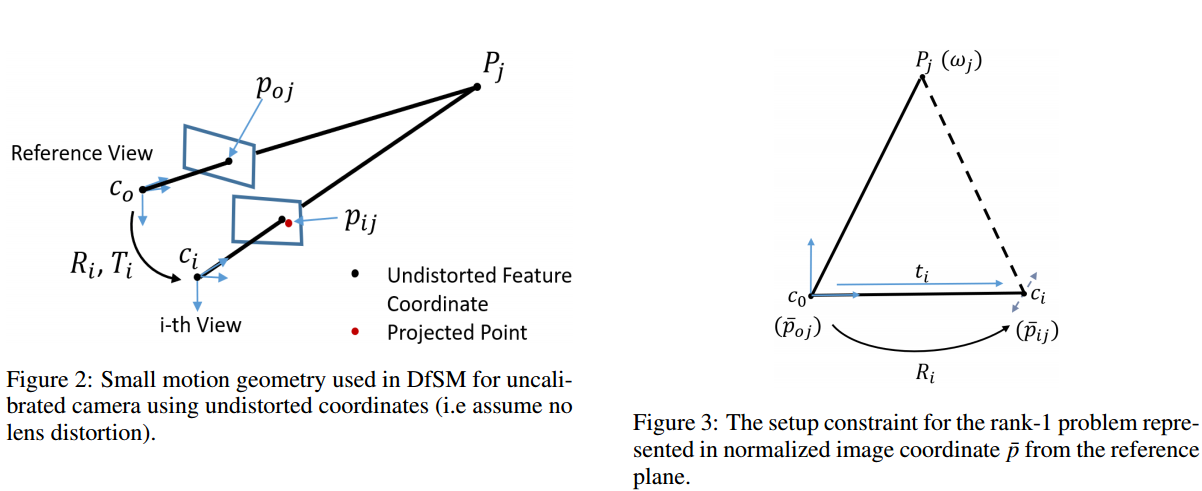
?DfSM手持设备上基于微小移动的深度估计, 研究人员基于一种Rank-1分解方法来实现boundle适应,随后利用SVD分解来从相机的移动计算深度值,只需要1/4计算迭代即可,保证了移动设备上的速度和效果。(from 诺基亚)
模型架构:
小运动的几何表示和rank1问题的图像归一化表示:
一些结果:

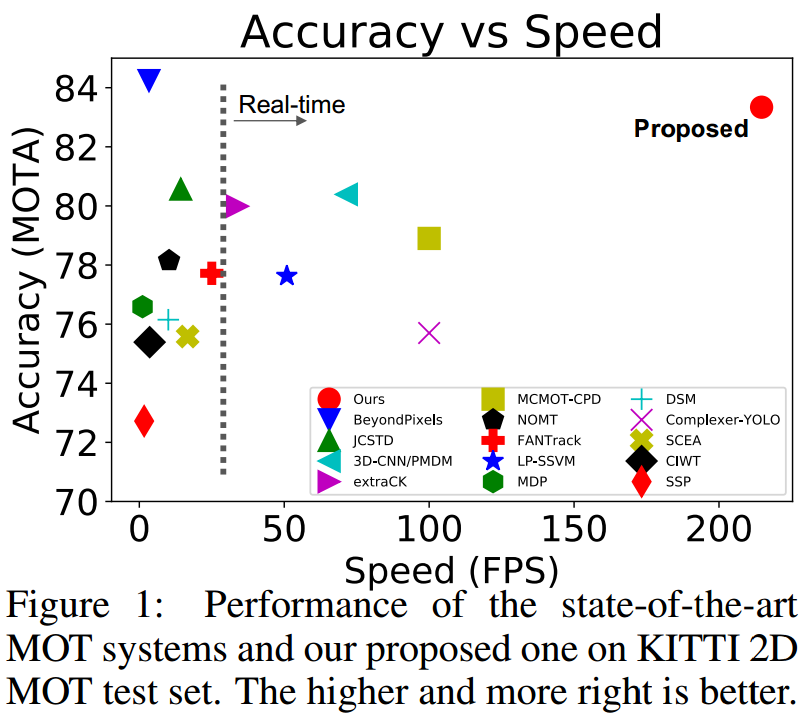
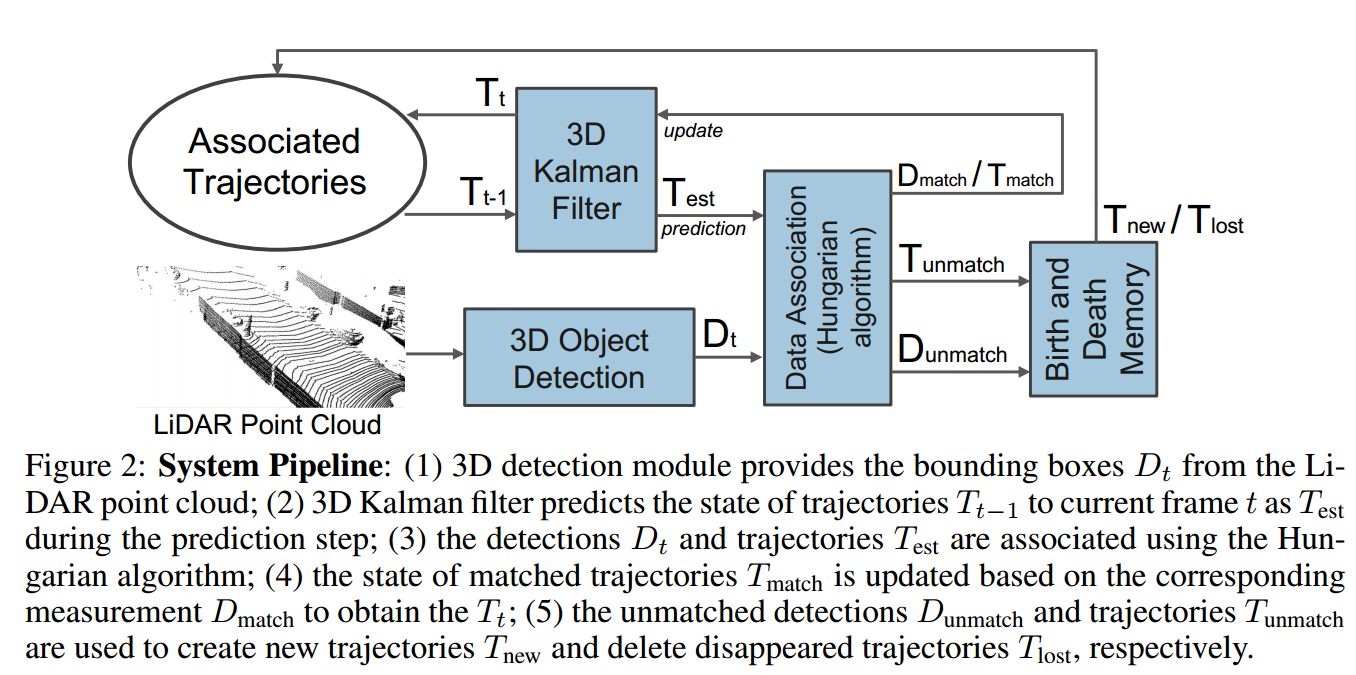
?三维目标追踪算法, (from RI,CMU)
三维目标追踪算法,与现有算法的对比:
系统架构图:
Daily Computer Vision Papers
| Positional Normalization Authors Boyi Li, Felix Wu, Kilian Q. Weinberger, Serge Belongie 用于减少深度神经网络的训练时间的广泛部署的方法是标准化每层的激活。虽然已经提出了各种规范化方案,但它们都遵循共同主题在空间维度上规范化并丢弃提取的统计数据。在本文中,我们提出了一种新颖的归一化方法,明显偏离了这个惯例。我们的方法,我们称之为位置标准化PONO,仅在通道上标准化自然吸引人的维度,其捕获在特定图像位置处提取的特征的第一和第二矩。我们认为这些时刻传达了关于输入图像和提取的特征的结构信息,这为网络可以从特征规范化中受益开辟了新的途径而不是忽视PONO规范化常数,我们建议将它们重新注入后续层以保留或在生成网络中传递结构信息。 |
| DSNet: Automatic Dermoscopic Skin Lesion Segmentation Authors Md. Kamrul Hasan, Lavsen Dahal, Prasad N. Samarakoon, Fakrul Islam Tushar, Robert Marti Marly 皮肤病变的自动分割被认为是计算机辅助诊断CAD中黑素瘤诊断的关键步骤。尽管其重要性,皮肤病变分割仍然是一项具有挑战性的任务,因为它们具有多样的颜色,纹理和无法区分的边界,并形成一个开放的问题。通过这项研究,我们提出了一种新的自动语义分割网络,用于健壮的皮肤病变分割,称为Dermoscopic Skin Network DSNet。为了减少使网络轻量化的参数数量,我们使用深度可分离卷积代替标准卷积,以将学习的区分特征投影到编码器的不同阶段的像素空间上。此外,我们实施了U Net和完全卷积网络FCN8,以与提议的DSNet进行比较。我们在两个公开可用的数据集上评估我们提出的模型,即ISIC 2017和PH2。对于ISI 2017和PH2数据集,获得的平均交叉联盟mIoU分别为77.5和87.0,其表现优于ISI 2017挑战赛冠军,相对于mIoU为1.0。我们建议的网络在ISIC 2017数据集上的表现也优于U Net和FCN8,相对于mIoU为3.6和6.8。我们的皮肤病变分割网络优于其他方法,可以在两个不同的测试数据集上提供更好的分段掩模,从而提高黑素瘤检测的性能。我们训练有素的模型以及源代码和预测的面具都是公开的。 |
| Deep Learning for Spacecraft Pose Estimation from Photorealistic Rendering Authors Pedro F. Proenca, Yang Gao 在空间交会,对接和碎片移除的轨道上接近操作需要在宽范围的光照条件下和高度纹理化的背景(即地球)下进行精确且稳健的6D姿态估计。本文研究利用深度学习和真实感渲染对已知不合作航天器的单眼姿态进行估计。我们首先提出了一个基于虚幻引擎4的模拟器,名为URSO,用于生成绕地球轨道运行的航天器的标记图像,可用于训练和评估神经网络。其次,我们提出了一种基于方向软分类的姿态估计的深度学习框架,它允许将方向模糊度建模为高斯混合。该框架在URSO数据集和ESA姿势估计挑战中进行了评估。在本次比赛中,我们的最佳模型在综合测试装置上获得第三名,在真实测试装置上获得第二名。此外,我们的结果显示了几个建筑和培训方面的影响,并且我们定性地展示了在URSO数据集上学习的模型如何在空间的真实图像上执行。 |
| Gated Multiple Feedback Network for Image Super-Resolution Authors Qilei Li, Zhen Li, Lu Lu, Gwanggil Jeon, Kai Liu, Xiaomin Yang 深度学习DL的快速发展将单图像超分辨率SR推向了一个新时代。然而,在大多数现有的基于DL的图像SR网络中,信息流仅是前馈的,并且不能完全探索高级特征。在本文中,我们提出了门控多反馈网络GMFN用于精确图像SR,其中通过重新路由多个高级特征有效地丰富了低级特征的表示。我们级联多个残余密集块RDB,并在时间上反复展开它们。所提出的GMFN中的两个相邻时间步骤之间的多个反馈连接利用在大的感受域下捕获的多个高级特征来细化缺乏足够的上下文信息的低级特征。精心设计的门控反馈模块GFM有效地从多个重新路由的高级特征中选择并进一步增强有用信息,然后利用增强的高级信息细化低级特征。大量实验证明了我们提出的GMFN在数量指标和视觉质量方面对现有技术SR方法的优越性。代码可在 |
| Adaptive Exploration for Unsupervised Person Re-Identification Authors Yuhang Ding, Hehe Fan, Mingliang Xu, Yi Yang 由于域偏差,直接部署在一个数据集上训练的深度人识别重新ID模型通常在另一个数据集上实现相当差的准确性。在本文中,我们提出了一种自适应探索AE方法,以无人监督的方式解决re ID的域移位问题。具体地,通过对源数据集的监督训练,在目标域中,引入re ID模型以最大化所有人图像之间的距离,并且最小化相似人图像之间的距离。在第一种情况下,通过将每个人图像视为单独的类,利用具有特征存储器的非参数分类器来鼓励人图像彼此远离。在第二种情况下,根据相似性阈值,我们的方法针对每个人图像自适应地选择特征空间中的邻域。通过将这些相似的人物图像视为同一类,非参数分类器迫使它们保持更近。然而,自适应选择的问题在于,当图像具有太多的邻域时,更可能吸引其他图像作为其邻域。结果,少数图像可以选择大量邻域,而大多数图像仅具有少量邻域。为了解决这个问题,我们还将平衡策略集成到自适应选择中。大规模重新识别数据集的大量实验证明了我们的方法的有效性。我们的代码已发布于 |
| 3D pavement surface reconstruction using an RGB-D sensor Authors Ahmadreza Mahmoudzadeh, Sayna Firoozi Yeganeh, Amir Golroo 路面管理系统的核心程序是数据收集。用于此目的的现代技术,例如基于点的激光器和激光扫描仪,太昂贵而无法购买,操作和维护。因此,发展中国家的城市官员很难使用这些设备进行数据收集。本文旨在介绍一种具有成本效益的技术,可用于路面遇险数据采集和三维路面重建。本研究中应用的技术是Kinect传感器,它不仅具有成本效益,而且足够精确。 Kinect传感器可同时记录深度和彩色图像。推车设计用于安装一系列Kinect传感器。校准摄像机并通过奇异值分解SVD算法校正收集表面的斜率。然后,提出了使用SURF加速鲁棒特征和MSAC M估计器SAmple Consensus算法缝合RGB D红绿蓝深度图像的过程,以便创建路面的3D结构。最后,提取横向剖面并进行一些现场试验以评估所提出的用于检测路面缺陷的方法的可靠性。 |
| calibDB: enabling web based computer vision through on-the-fly camera calibration Authors Pavel Rojtberg, Felix Gorschl ter 对于许多计算机视觉应用,相机校准数据的可用性至关重要,因为整体质量在很大程度上取决于它。虽然某些设备上的校准数据可通过增强现实AR框架(如ARCore和ARKit)获得,但对于大多数相机而言,此信息不可用。因此,我们提出了一种基于网络的校准服务,不仅可以聚合校准数据,还可以实时校准新的摄像机。我们以新颖的相机校准框架为基础,即使是初学者也可以在大约2分钟内完成精确的相机校准。这允许在网上一般部署计算机视觉算法,由于缺乏校准数据,这在以前是不可能的。 |
| Efficient Pose Selection for Interactive Camera Calibration Authors Pavel Rojtberg, Arjan Kuijper 使用平面图案进行相机校准的姿势选择很少被考虑,但校准精度很大程度上取决于它。这项工作提出了一种姿势选择方法,可以找到一组紧凑而强大的校准姿势,适用于交互式校准。因此,明确地避免了导致不可靠解决方案的单一姿势,而有利于减少校准的不确定性的姿势。为此,我们使用不确定性传播。 |
| Template-Based Posit Multiplication for Training and Inferring in Neural Networks Authors Ra l Murillo Montero, Alberto A. Del Barrio, Guillermo Botella 正数数字系统可以说是现在算术中最有前途和讨论的主题。最近由John L. Gustafson提出的格式所声称的突破已经成为人们关注的焦点。在这项工作中,我们首先描述一种算法,用于乘以两个正数,即使指数位的数量为零。这种配置在文献中几乎没有解决,因为它允许部署快速的S形函数,因此特别有趣。然后将所提出的乘法算法作为模板集成到众所周知的FloPoCo框架中。显示合成结果与FloPoCo提供的浮点乘法进行比较。其次,在训练和推理阶段的神经网络场景中研究了假设的表现。据我们所知,这是第一次使用正位格式进行训练,即使使用减少的位置配置,也可以实现二进制分类问题的有希望的结果。在推理阶段,8位假设在处理MNIST数据集时与浮点一样好,但在CIFAR 10中失去了一些准确性。 |
| A Light weight and Hybrid Deep Learning Model based Online Signature Verification Authors Chandra Sekhar V., Anoushka Doctor, Prerana Mukherjee, Viswanath Pulabaigiri 基于深度学习的模型针对各种AI相关问题的增强使用是由于具有更深度的现代架构和大量解释数据集的可用性。基于这些体系结构的模型需要巨大的培训和存储成本,这使得它们在诸如在线签名验证OSV之类的关键应用中使用效率低并且在资源约束设备中部署。作为一种解决方案,在这项工作中,我们的贡献是双重的。 1一种有效的降维技术,用于减少要考虑的特征数量; 2是用于在线签名验证的基于CNN LSTM的混合架构的最先进模型。对公开可用的数据集MCYT,SUSIG,SVC进行的全面实验证实,即使只有一个训练样本,所提出的模型也能获得更好的准确性。所提出的模型在所有三个数据集的各种类别中产生最先进的性能。 |
| Depth from Small Motion using Rank-1 Initialization Authors Peter O. Fasogbon 小动作的深度DfSM Ha等人,2016年对于商用手持设备特别有意义,因为它允许以最少的用户努力和合作获得深度信息。由于这些设备的速度和内存问题,使用Bundle Adjustment BA的方法的自校准优化只需要10 15个图像。因此,优化往往需要多次迭代才能收敛,或者在某些情况下根本不会收敛。这项工作提出了使用秩1因子分解法Tomasi和Kanade,1992,Aguiar和Moura,1999a进行束调整的稳健初始化。我们创建一个在无噪声情况下排名为1的约束矩阵,然后使用SVD计算逆深度值和摄像机运动。我们只需要大约四分之一的束调整迭代来收敛。我们还提出了网格特征提取技术,以便在整个图像帧中仅跟踪重要和小的特征。这还确保了移动设备上的完整执行时间的加速。对于实验,我们使用CPU GPU协处理的优化加速度记录了在两个移动设备平台上建议的Rank 1初始化的执行时间。 Rank 1 BA的组合生成更强大的深度图,并且明显快于单独使用BA。 |
| Improving Deep Lesion Detection Using 3D Contextual and Spatial Attention Authors Qingyi Tao, Zongyuan Ge, Jianfei Cai, Jianxiong Yin, Simon See 与自然物体检测相比,计算机断层扫描CT扫描的病变检测具有挑战性,因为小病变大小和类间变异小的两个主要原因。首先,病变通常仅占据CT图像中的小区域。由于其有限的空间特征分辨率,这种小区域的特征可能无法提供足够的信息。其次,在CT扫描中,病变通常与背景无法区分,因为病变和非病变区域可能具有非常相似的外观。为了解决这两个问题,我们需要丰富特征表示并改进特征判别性。因此,我们向3D上下文病变检测框架引入双重注意机制,包括交叉切片上下文关注,以通过软重采样过程选择性地聚合来自不同切片的信息。此外,我们提出片内空间注意力,将特征学习集中在最突出的区域。我们的方法可以轻松地端到端地进行训练,而不会在基本检测网络上增加大量开销。我们使用DeepLesion数据集并训练通用病变检测器来检测各种病变,如肝肿瘤,肺结节等。结果表明,我们的模型可以使用3D上下文信息显着提高基线病变检测器的结果,但使用更少的切片。 |
| Domain Adaptation in Multi-Channel Autoencoder based Features for Robust Face Anti-Spoofing Authors Olegs Nikisins, Anjith George, Sebastien Marcel 虽然人脸识别系统的性能在过去十年中有了显着改善,但它们被证明非常容易受到演示攻击欺骗的影响。面部演示攻击检测PAD领域的大多数研究都集中在提高单个数据库中系统的性能。面部PAD数据集通常使用RGB相机捕获,并且具有非常有限数量的真实样本和呈现攻击工具。即使在封闭的情景中,训练面对这些数据的PAD系统也会导致性能不佳,尤其是在涉及复杂攻击时。 |
| Deep Pixel-wise Binary Supervision for Face Presentation Attack Detection Authors Anjith George, Sebastien Marcel 人脸识别已经发展成为一种突出的生物识别身份验证模式。但是,表示攻击的漏洞限制了其可靠的部署。在无人值守的情况下,自动检测表示攻击对于安全使用人脸识别技术至关重要。在这项工作中,我们引入了基于卷积神经网络CNN的框架,用于演示攻击检测,具有深度像素监督。该框架仅使用帧级信息,使其适合在智能设备中部署,并且计算和时间开销最小。我们证明了所提方法在公共数据集中对于内部和跨数据集实验的有效性。所提出的方法在重放移动数据集中实现HTER为0,并且在OULU数据集的协议1中的ACER为0.42,优于现有技术方法。 |
| BADAM: A Public Dataset for Baseline Detection in Arabic-script Manuscripts Authors Benjamin Kiessling, Daniel St kl Ben Ezra, Matthew Thomas Miller 手写文本识别在历史作品中的应用高度依赖于准确的文本行检索。最近出现了许多利用稳健的基线检测范例的系统,但是缺乏完善的数据集(包括非拉丁文脚本中的工作)阻碍了用于挑战脚本的布局分析方法的进步。我们提供了来自不同域和时间段的400个带注释的文档图像的数据集。简要阐述了阿拉伯语脚本中用于布局分析和后续处理步骤的手写所带来的特殊挑战。最后,我们提出了一种基于完全卷积编码器解码器网络的方法,以从手稿中提取任意形状的文本行图像。 |
| UnsuperPoint: End-to-end Unsupervised Interest Point Detector and Descriptor Authors Peter Hviid Christiansen, Mikkel Fly Kragh, Yury Brodskiy, Henrik Karstoft 很难为自然图像中的兴趣点创建一致的地面实况数据,因为对于人类注释者来说难以清楚且一致地定义兴趣点。这使得兴趣点探测器非常容易构建。在这项工作中,我们引入了一个无监督的基于深度学习的兴趣点检测器和描述符。使用自我监督的方法,我们利用暹罗网络和新的损失函数,使得兴趣点得分和位置能够自动学习。生成的兴趣点检测器和描述符是UnsuperPoint。我们使用点位置回归到1使得UnsuperPoint端对端可训练,2使用非最大抑制在模型中。与大多数可训练的探测器不同,它不需要产生伪地面真实点,没有来自运动产生的表示的结构,并且仅从一轮训练中学习该模型。此外,我们引入了一种新的损失函数来规范网络预测的均匀分布。 UnsuperPoint以每秒323帧的速度实时运行,分辨率为224倍320和90fps,480倍640。当在HPatch数据集上测量速度,可重复性,定位,匹配分数和单应性估计时,它与现有技术性能相当或更好。 |
| On the Exact Recovery Conditions of 3D Human Motion from 2D Landmark Motion with Sparse Articulated Motion Authors Abed Malti 在本文中,我们解决了从2D地标运动中检索3D人体运动的精确恢复条件的问题。我们使用骨骼运动模型将3D人体运动表示为角度清晰度运动的矢量。我们基于这样的观察来解决这个问题:在高跟踪速率下,无论全局刚性运动如何,只有很少的角度关节具有非零运动。我们提出了一个具有ell 0范数的第一个理想公式,以在给出重投影误差的时间微分的等式约束的情况下最小化非零角度关节运动的基数。第二个松弛的公式依赖于1的范数来最小化角度关节运动的绝对值之和。该配方具有即使在确定的情况下也能够提供3D运动的优点,其中2D地标的数量的两倍小于角度关节的数量。我们定义了一个特定属性,即投影运动空间属性PKSP,它考虑了重投影约束和运动模型。我们证明,对于宽松的配方,当且仅当PKSP属性被验证时,我们能够从2D地标恢复精确的3D人体运动。我们进一步证明,当且仅当PKSP条件被填充时,解决宽松的公式提供与理想公式相同的基本事实解决方案。模拟稀疏骨骼角运动的结果表明该方法能够恢复角运动的精确位置。我们提供公开可用的真实数据HUMAN3.6M,PANOPTIC和MPI I3DHP的结果。 |
| Sparse-to-Dense Hypercolumn Matching for Long-Term Visual Localization Authors Hugo Germain, Guillaume Bourmaud, Vincent Lepetit 我们提出了一种新颖的特征点匹配方法,适用于长期情景下的稳健和准确的户外视觉定位。给定查询图像,我们首先使用最近的检索技术将其与注册的参考图像的数据库进行匹配。这给了我们对相机姿势的初步估计。为了改进此估计,与先前的方法一样,我们匹配查询图像和检索到的参考图像上的2D点。然而,该步骤易于失败,因为在可能非常不同的条件下捕获的图像之间仍然非常难以检测和匹配稀疏特征点。我们的关键贡献是表明我们只需要在检索到的参考图像中提取稀疏特征点然后我们在查询图像中详尽地搜索相应的2D位置。可以使用卷积运算有效地执行该搜索,并且通过使用超列描述符(即,为检索而计算的图像特征)来鲁棒地执行该搜索。我们将此方法称为稀疏到密集的超列匹配。由于离线重建阶段我们知道参考图像中稀疏特征点的3D位置,因此可以从这些匹配中准确地估计相机姿态。我们的实验表明,这种方法使我们能够在几个具有挑战性的室外数据集上超越现有技术水平。 |
| A Baseline for 3D Multi-Object Tracking Authors Xinshuo Weng, Kris Kitani 3D多目标跟踪MOT是许多实时应用(如自动驾驶或辅助机器人)的基本组件技术。然而,最近3D MOT的工作倾向于更多地关注开发精确系统,而不是考虑计算成本和系统复杂性。相比之下,这项工作提出了一个简单而准确的实时基线3D MOT系统。我们使用现成的3D物体探测器从LiDAR点云获得定向的3D边界框。然后,3D卡尔曼滤波器和匈牙利算法的组合用于状态估计和数据关联。虽然我们的基线系统是标准方法的直接组合,但我们获得了最先进的结果。为了评估我们的基线系统,我们为官方KITTI 2D MOT评估提出了新的3D MOT扩展以及两个新指标。我们提出的3D MOT基线方法为KITTI的3D MOT建立了新的最先进性能,将3D MOTA从现有技术的72.23提高到76.47。令人惊讶的是,通过将我们的3D跟踪结果投影到2D图像平面并与已发布的2D MOT方法进行比较,我们的系统在官方KITTI排行榜上排名第二。此外,我们提出的3D MOT方法以214.7 FPS的速度运行,比现有的2D MOT系统快65倍。我们的代码是公开的 |
| Learning from Thresholds: Fully Automated Classification of Tumor Infiltrating Lymphocytes for Multiple Cancer Types Authors Shahira Abousamra, Le Hou, Rajarsi Gupta, Chao Chen, Dimitris Samaras, Tahsin Kurc, Rebecca Batiste, Tianhao Zhao, Shroyer Kenneth, Joel Saltz 用于表征整个载玻片组织形态的深度学习分类器需要大量的注释数据来学习不同组织和癌症类型的变化。众所周知,手动生成数字病理训练数据是耗时且昂贵的。在本文中,我们提出了一种半自动方法,用于一次注释一组类似实例,而不是仅收集每个实例手动注释。这允许更大的训练集,其反映多种癌症类型的视觉可变性,并因此训练单个网络,其可以自动应用于每种癌症类型而无需人为调整。我们将我们的方法应用于在H E图像中对肿瘤浸润淋巴细胞TIL进行分类的重要任务。针对个体癌症类型训练先前的方法,在循环阈值调整中使用较小的训练集和人。我们将这些阈值化结果用作大规模半自动注释。结合现有的手动注释,我们训练的深度网络能够自动生成12种癌症类型的更好的TIL预测结果,与循环方法中的人类相比。 |
| Attentive CT Lesion Detection Using Deep Pyramid Inference with Multi-Scale Booster Authors Qingbin Shao, Lijun Gong, Kai Ma, Hualuo Liu, Yefeng Zheng 计算机断层扫描中准确的病变检测CT切片有利于医学诊断过程中的病理器官分析。最近,它已被解决为使用卷积神经网络CNN的对象检测问题。尽管现成的CNN模型取得了成就,但目前的检测精度受到CNN在不同规模上的病变的无法限制。在本文中,我们提出了一个多尺度助推器MSB,其频道和空间注意力集成到主干功能金字塔网络FPN中。在每个金字塔等级中,所提出的MSB通过使用分层扩张的卷积HDC来捕获细粒度的尺度变化。同时,所提出的信道和空间注意模块增加了网络选择用于病变检测的相关特征响应的能力。 DeepLesion基准数据集上的大量实验表明,所提出的方法在最先进的方法中表现出色。 |
| Signet Ring Cell Detection With a Semi-supervised Learning Framework Authors Jiahui Li, Shuang Yang, Xiaodi Huang, Qian Da, Xiaoqun Yang, Zhiqiang Hu, Qi Duan, Chaofu Wang, Hongsheng Li Signet环细胞癌是一种预后不良的罕见腺癌。早期发现导致患者生存率大幅提高。然而,病理学家只能在显微镜下目视检测印戒细胞。这个程序不仅费力,而且容易遗漏。因此,自动且准确的印章环细胞检测解决方案是重要的,但之前尚未进行过研究。在本文中,我们迈出了第一步,为印章环细胞检测问题提出了一个半监督学习框架。提出自我训练来应对不完整注释的挑战,并且合作训练适合于探索未标记的区域。结合这两种技术,我们的半监督学习框架可以更好地利用标记和未标记的数据。大型真实临床数据的实验证明了我们设计的有效性。我们的框架实现了准确的印戒细胞检测,可以很容易地应用于临床试验。该数据集将很快发布,以促进该地区的发展。 |
| Accurate Nuclear Segmentation with \\Center Vector Encoding Authors Jiahui Li, Zhiqiang Hu, Shuang Yang 核分割对于病理图像分析而言是重要且经常需要的,但由于核拥挤和可能的闭塞而具有挑战性。在本文中,我们提出了一种新的自下而上的核分割方法。引入中心掩模和中心矢量的概念以更好地描绘像素和核实例之间的关系。因此,实例区分过程在很大程度上简化并且更容易理解。实验证明了中心矢量编码的有效性,其中我们的方法明显优于现有技术。 |
| Fast Visual Object Tracking with Rotated Bounding Boxes Authors Bao Xin Chen, John K. Tsotsos 在本文中,我们展示了一种新的算法,使用椭圆拟合来估计边界框旋转角度和大小与目标上的分割掩码进行在线和实时视觉对象跟踪。我们的方法SiamMask E改进了现有技术对象跟踪算法SiamMask的边界框拟合程序,并且在配备GPU GeForce GTX 1080 Ti或更高版本的系统上仍保持80 fps的快速跟踪帧速率。我们在用旋转边界框标记的视觉对象跟踪数据集VOT2016,VOT2018和VOT2019上测试了我们的方法。通过与原始SiamMask的比较,我们在VOT2019上实现了0.645和0.303 EAO的精度提高,比原始SiamMask高0.049和0.02。 |
| Personalised aesthetics with residual adapters Authors Carlos Rodr guez Pardo, Hakan Bilen 近年来,由于卷积神经网络的普及和新注释数据集的可用性,使用计算方法来评估摄影中的美学已经引起了人们的兴趣。该领域的大多数研究都集中在设计不考虑个人偏好预测图片审美价值的模型。我们提出了一种基于残差学习的模型,该模型能够学习主观的,用户对摄影美学的特定偏好,同时超越现有技术方法并在模型中保持有限数量的用户特定参数。我们的模型也可用于图片增强,并且适用于计算资源量有限的基于内容或混合推荐系统。 |
| Fully Convolutional Network for Removing DCT Artefacts From Images Authors Patryk Najgebauer, Rafal Scherer 深度学习方法在图像变换以及图像降噪或超分辨率方法中实现了优异的结果。基于这些解决方案,我们提出了一种用JPEG格式压缩的图像块重建的深度学习方法。用离散余弦变换DCT压缩的图像包含块形式的可见伪像,这在某些情况下主要在对比元素的边缘上破坏图像的美感。这是不可避免的,并且可以通过图像压缩的程度来调整块伪像的可辨别性,这严重影响输出图像尺寸。我们使用完全卷积网络,它以与JPEG编码器相同的方式直接在8x8像素块上运行。多亏了这一点,我们不修改输入图像,我们只将其划分为单独处理的块。我们的神经模型的目的是修改块中的像素以减少相对于相邻图像的背景的伪影可见性,并重建由DCT变换失真的图像的原始图案。我们在从转换为JPEG和PNG格式的矢量图像创建的数据集上训练我们的模型,分别作为输入和输出数据。 |
| Learning in Competitive Network with Haeusslers Equation adapted using FIREFLY algorithm Authors N. Joshi 许多竞争神经网络由空间排列的神经元组成。连接细胞的称重矩阵代表局部激发和长程抑制。他们被称为软胜利者,占据所有网络,并显示出展示理想的信息处理。根据使用先前数据知识选择的空间布置,局部兴奋连接是预定义的手动连线多次。在这里,我们通过Haeusslers方程和基于生物学的Firefly算法的修改布线方案提出了在循环网络中的学习。以下结果显示在没有带有固定拓扑的手动布线的输入模式下在这种网络中学习 |
| Nonnegative Matrix Factorization with Local Similarity Learning Authors Chong Peng, Zhao Kang, Chenglizhao Chen, Qiang Cheng 现有的非负矩阵分解方法着重于学习数据的全局结构以构造基础和系数矩阵,忽略了数据中通常存在的局部结构。在本文中,我们提出了一种新的非负矩阵分解方法,它以相互增强的方式学习局部相似性和聚类。学习的新表示更具代表性,因为它更好地揭示了数据的固有几何属性。给出了非线性扩展,并且利用理论收敛保证开发了有效的乘法更新。广泛的实验结果证实了该模型的有效性。 |
| Quantifying Confounding Bias in Neuroimaging Datasets with Causal Inference Authors Christian Wachinger, Benjamin Gutierrez Becker, Anna Rieckmann, Sebastian P lsterl 神经影像数据集的规模不断扩大,以解决日益复杂的医学问题。然而,即使是今天最大的数据集也太小,无法用于训练复杂的机器学习模型。一种潜在的解决方案是通过汇集来自多个数据集的扫描来增加样本量。在这项工作中,我们将来自15项研究的12,207次MRI扫描结合起来,并表明由于在训练数据中引入了各种类型的偏差,简单的汇集通常是不明智的。首先,我们系统地定义这些偏见。其次,我们通过实验显示扫描可以正确地分配到各自的数据集,检测偏差,准确度为73.3。最后,我们建议通过使用因果推断量化单个数据集中的混杂程度和因果关系来解释混淆因素的因果关系。我们通过在Kolmogorov复杂性方面找到最简单的图形模型来实现这一目标。由于Kolmogorov复杂性不能直接计算,我们使用最小描述长度来近似它。我们凭经验证明我们的方法能够从真实的神经影像数据中估计出合理的因果关系。 |
| Deep Probabilistic Modeling of Glioma Growth Authors Jens Petersen, Paul F. J ger, Fabian Isensee, Simon A. A. Kohl, Ulf Neuberger, Wolfgang Wick, J rgen Debus, Sabine Heiland, Martin Bendszus, Philipp Kickingereder, Klaus H. Maier Hein 用于模拟脑肿瘤生长动力学(特别是神经胶质瘤)的现有方法使用生物学启发的细胞扩散模型,使用图像数据来估计相关参数。在这项工作中,我们提出了一种基于概率分割和表示学习的最新进展的替代方法,它可以直接从数据中隐含地学习生长动态,而无需基础显式模型。我们提出的证据表明,我们的方法能够根据过去对同一肿瘤的观察条件,了解可能的未来肿瘤表现的分布情况。 |
| Lidar-based Object Classification with Explicit Occlusion Modeling Authors Xiaoxiang Zhang, Hao Fu, Bin Dai LIDAR是无人地面车辆UGV最重要的传感器之一。基于激光雷达点云的目标检测和分类是UGV的关键技术。在物体检测和分类中,相邻物体之间的相互遮挡是影响精度的重要因素。在本文中,我们将遮挡视为点云数据的固有属性。我们提出了一种明确模拟遮挡的新方法。然后在随后的分类步骤中考虑遮挡特性。我们在KITTI数据集上进行实验。实验结果表明,利用我们建模的遮挡特性,分类器获得了更好的性能。 |
| Learning by Abstraction: The Neural State Machine Authors Drew A. Hudson, Christopher D. Manning 我们介绍神经状态机,寻求弥合AI的神经和符号视图之间的差距,并将它们的互补优势整合到视觉推理的任务中。给定一个图像,我们首先预测一个表示其基本语义的概率图,并用作结构化世界模型。然后,我们对图形执行顺序推理,迭代遍历其节点以回答给定问题或绘制新推理。与大多数旨在与原始感官数据紧密交互的神经架构相反,我们的模型通过将视觉和语言模态转换为基于语义概念的表示,而在抽象潜在空间中运行,从而实现增强的透明度和模块性。我们在VQA CP和GQA上评估我们的模型,这两个最近的VQA数据集涉及组合性,多步推理和多种推理技巧,在两种情况下都达到了最先进的结果。我们提供了进一步的实验,说明了模型在多个维度上的强大泛化能力,包括概念的新颖组成,答案分布的变化和看不见的语言结构,展示了我们方法的质量和功效。 |
| Brain Tissues Segmentation on MR Perfusion Images Using CUSUM Filter for Boundary Pixels Authors S.M. Alkhimova, A. P. Krenevych 提出了一种全自动,相对准确的T2加权磁共振灌注成像脑组织分割方法。使用该方法的分割提供了获得对具有异常脑解剖结构的图像感兴趣的灌注区域的可能性,这对于灌注分析非常重要。在所提出的方法中,结果呈现为二元掩模,其标记具有单位值的脑组织像素的两个区域和颅骨,颅外软组织和具有零值的背景像素。基于两个研究区域之间的边界的位置产生二元掩模。利用CUSUM滤波器检测每个边界点,作为沿着从一个区域到另一个区域的边界的正弦状路径上移动时的迭代累积点的变化点。对20个临床病例的评估结果表明,所提出的分割方法可以显着减少在具有异常脑解剖结构的T2加权磁共振灌注图像上获得用于感兴趣灌注区域的期望结果所需的时间和努力。 |
| Barriers towards no-reference metrics application to compressed video quality analysis: on the example of no-reference metric NIQE Authors Anastasia Antsiferova, Dmitriy Kulikov, Denis Kondranin, Dmitriy Vatolin 本文分析了无参考度量NIQE在视频编解码器比对任务中的应用。检测并描述了视频度量行为中的许多问题。该指标在黑色和纯色框架上具有异常分数。在某些情况下,建议的度量标准质量得分平均技术有助于改善结果。此外,NIQE对于具有详细纹理的视频具有低质量分数,而对于较低比特率的视频由于压缩后这些纹理的模糊而具有较高分数。虽然NIQE显示了许多测试视频的自然结果,但它并不是通用的,目前不能用于视频编解码器比较。 |
| Fine-Grained Continual Learning Authors Vincenzo Lomonaco, Davide Maltoni, Lorenzo Pellegrini 机器人视觉是一个持续学习可以发挥重要作用的领域。在复杂环境中操作的具体代理需要经常和不可预测的变化,以便不断学习和适应。例如,在对象识别的上下文中,机器人应该能够在不忘记未见过的类的对象的情况下学习,并且在发现已知类的新实例时提高其识别能力。理想情况下,持续学习应该由单个对象的短视频的可用性触发,并在板载硬件上在线执行。在本文中,我们介绍了一种基于CORe50基准的新颖的细粒度连续学习协议,并提出了两种连续学习技术,即使在近400个小非i.i.d的具有挑战性的情况下也能有效学习。增量批次。 |
| AutoSlim: An Automatic DNN Structured Pruning Framework for Ultra-High Compression Rates Authors Ning Liu, Xiaolong Ma, Zhiyuan Xu, Yanzhi Wang, Jian Tang, Jieping Ye 结构化重量修剪是DNN的代表性模型压缩技术,以减少存储和计算要求并加速推断。由于大量灵活的超参数,自动超参数确定过程是必要的。这项工作提出了AutoSlim,一个自动结构化修剪框架,具有以下关键性能改进,我在自动过程中有效地结合了结构化修剪方案,采用基于ADMM的结构化权重修剪作为核心算法,并提出了一个创新的附加净化步骤用于进一步减轻重量而没有精确度损失; iii开发通过基于经验的引导搜索增强的有效启发式搜索方法,取代现有的深度强化学习技术,其具有与目标修剪问题的潜在不兼容性。对CIFAR 10和ImageNet数据集的大量实验表明,AutoSlim是实现以前无法实现的权重和FLOP数量的超高修剪率的关键。例如,在相同精度下,AutoSlim在修剪率方面优于自动模型压缩的先前工作最多33次。我们以匿名链接发布此项工作的所有模型 |
| Chinese Abs From Machine Translation |

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}