







语音合成流程
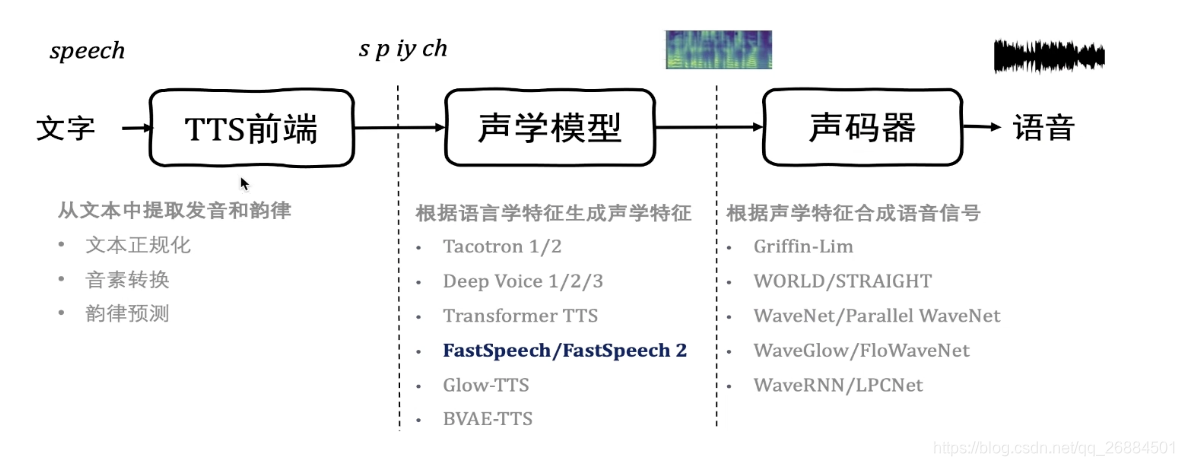
端到端语音合成模型(TTS 模型)
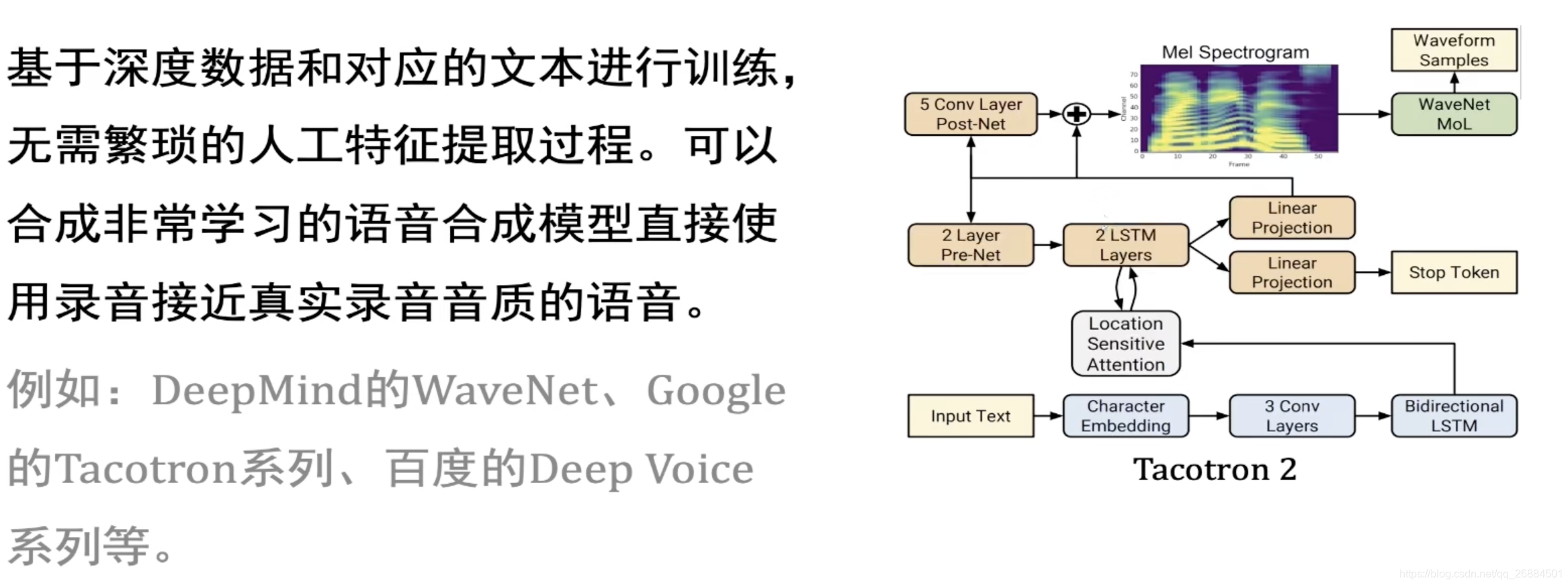
tacotron 2
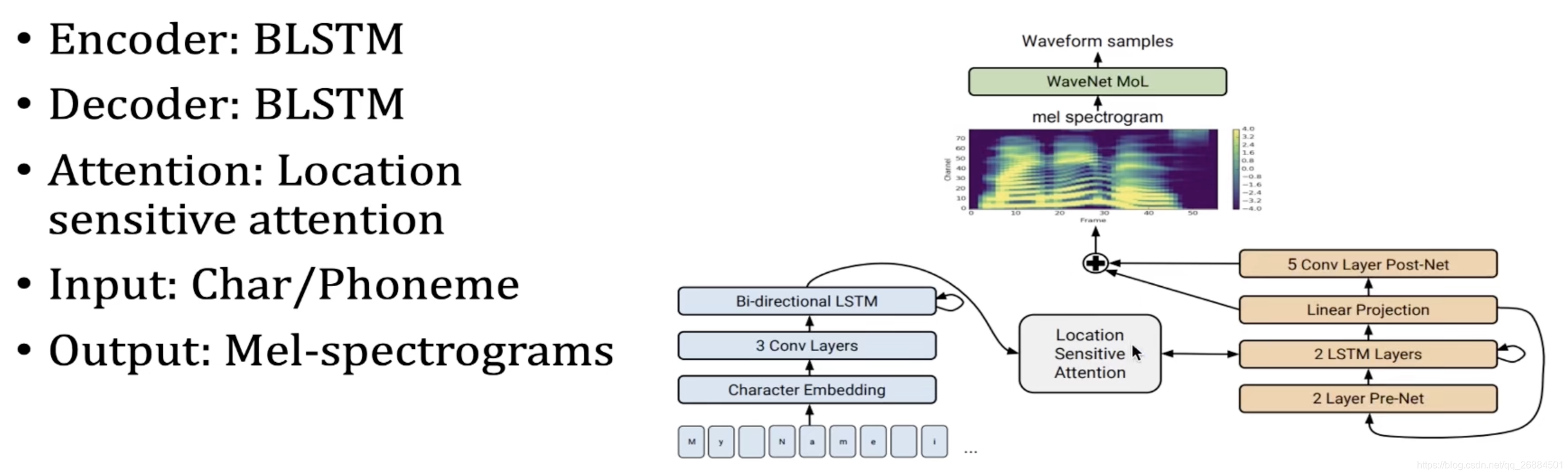
encoder部分:类似于wordenbedding放方式进行编码,每个字符对应一个向量,然后对每个vector向量进行类似于contest的交互,使用的交互方式是双向的lstm,能够更好的吸收左右两个方向的信息
decoder:将编码的信息转化为另一种形式的信息,中间使用到tactron2论文中localtion sensitive attention,将两个模态的数据连接起来,可以吸收读音等频谱所需要的信息,最后通过lstm和后处理网络将语音输出出来
TransFormer TTS
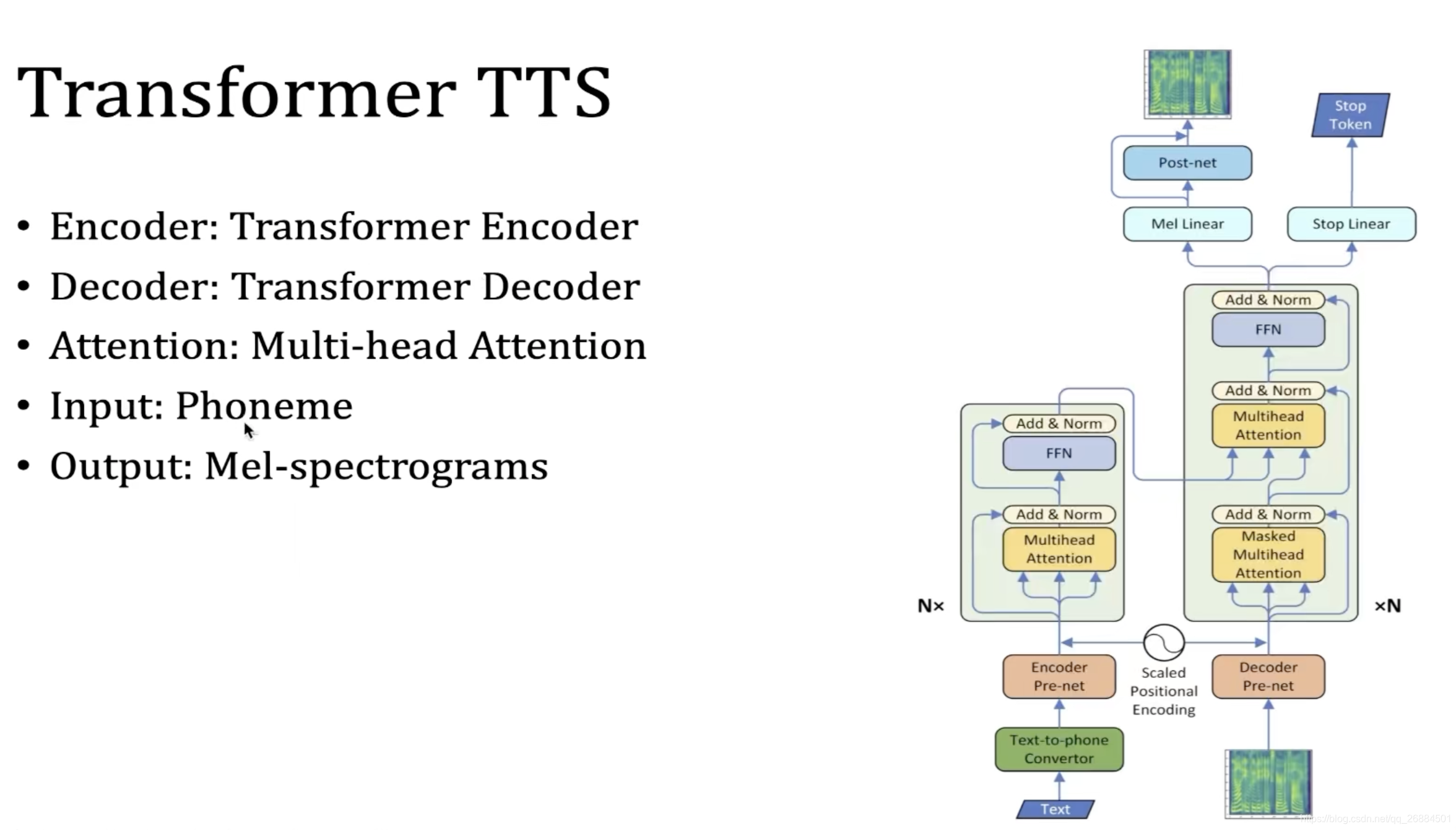
Neural Speech Synthesis with Transformer Network
Deep voice3
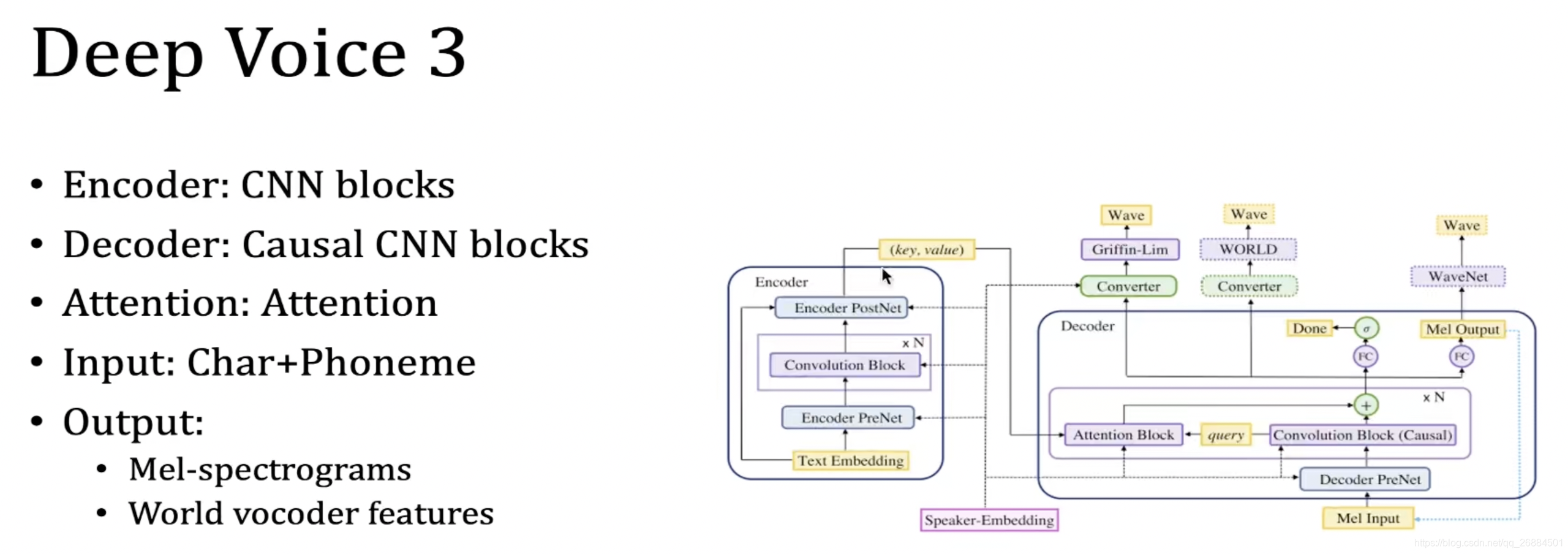
输入是字符和因素合成在一起
然后可以看到输出是有很多个声码器组成的,每个声码器(即文章第一幅图中将频谱转化成音频)侧重的特征点不一样,将不同的特征放在一起进行学习,
Deep Voice 3: Scaling Text-to-Speech with Convolutional Sequence Learning
上述三种自回归的语音合成缺陷

简单说就是attention机制不稳定,会导致漏词或多词;无法控制语速和语调
非自回归语音合成
fast speech
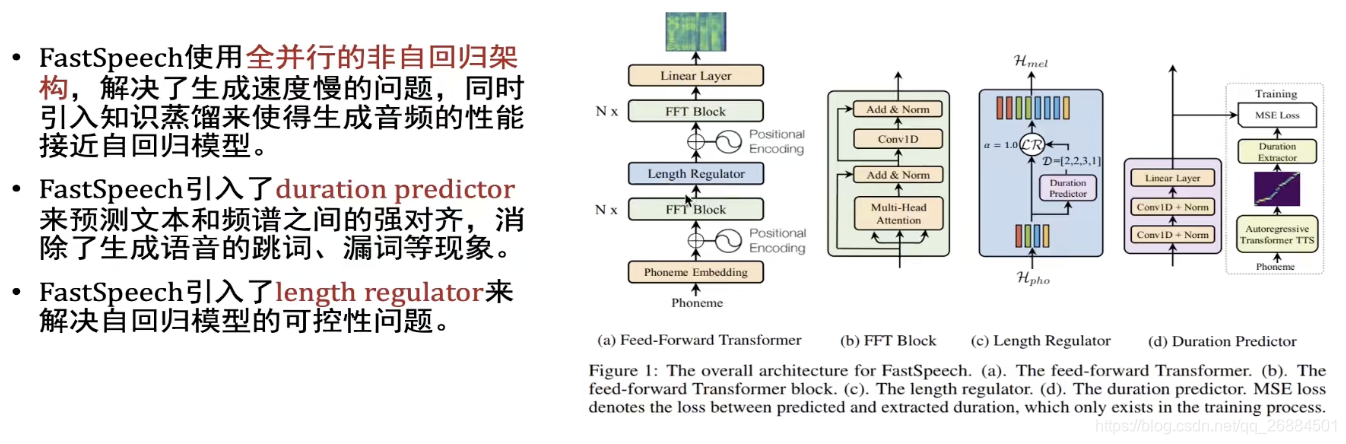
提出了fast speech的方法,解决了自回归模型的问题,但是有个问题就是生成的语音质量比较差,解决问题的方法是进行知识的蒸馏
此外引入了durationpreditioner的方式进行文本与语音的强对齐,通过强制对齐手段解决了跳词和漏词的现象
引入length regulator来建立文本和语音特征的联系,实现了从文本到语音的映射(端到端)
语音质量评估
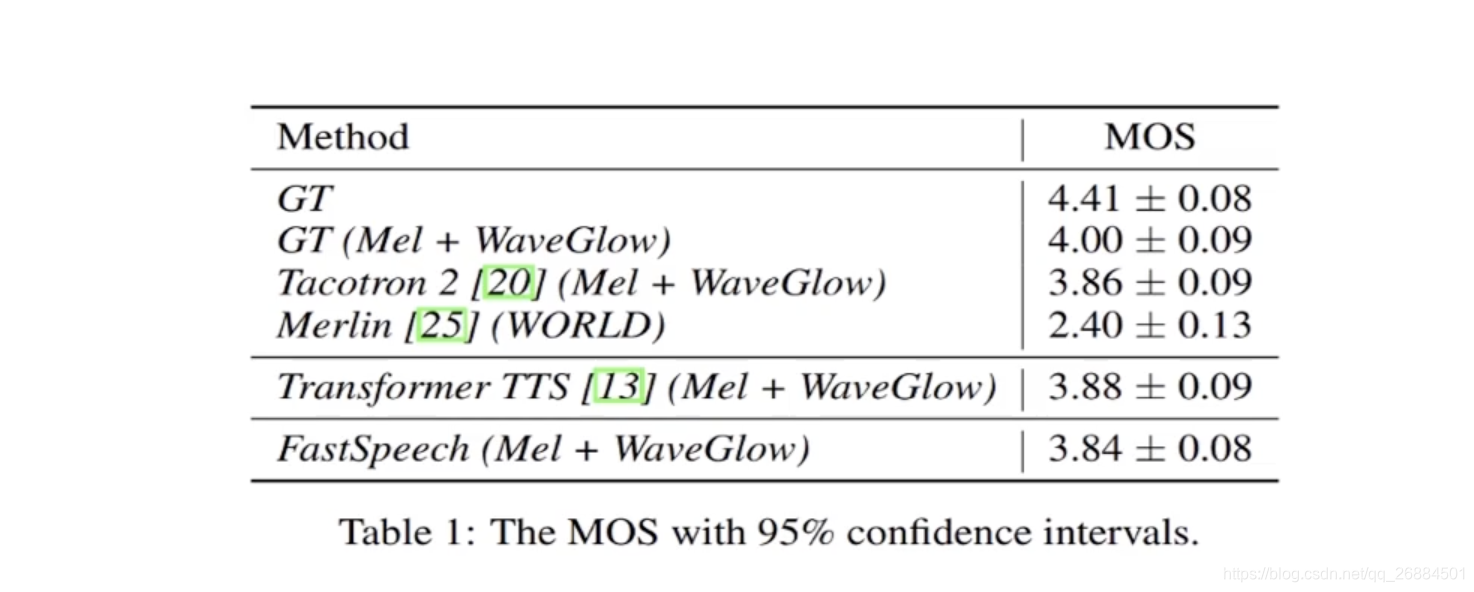
鲁棒性测试

长度和韵律可控性分析
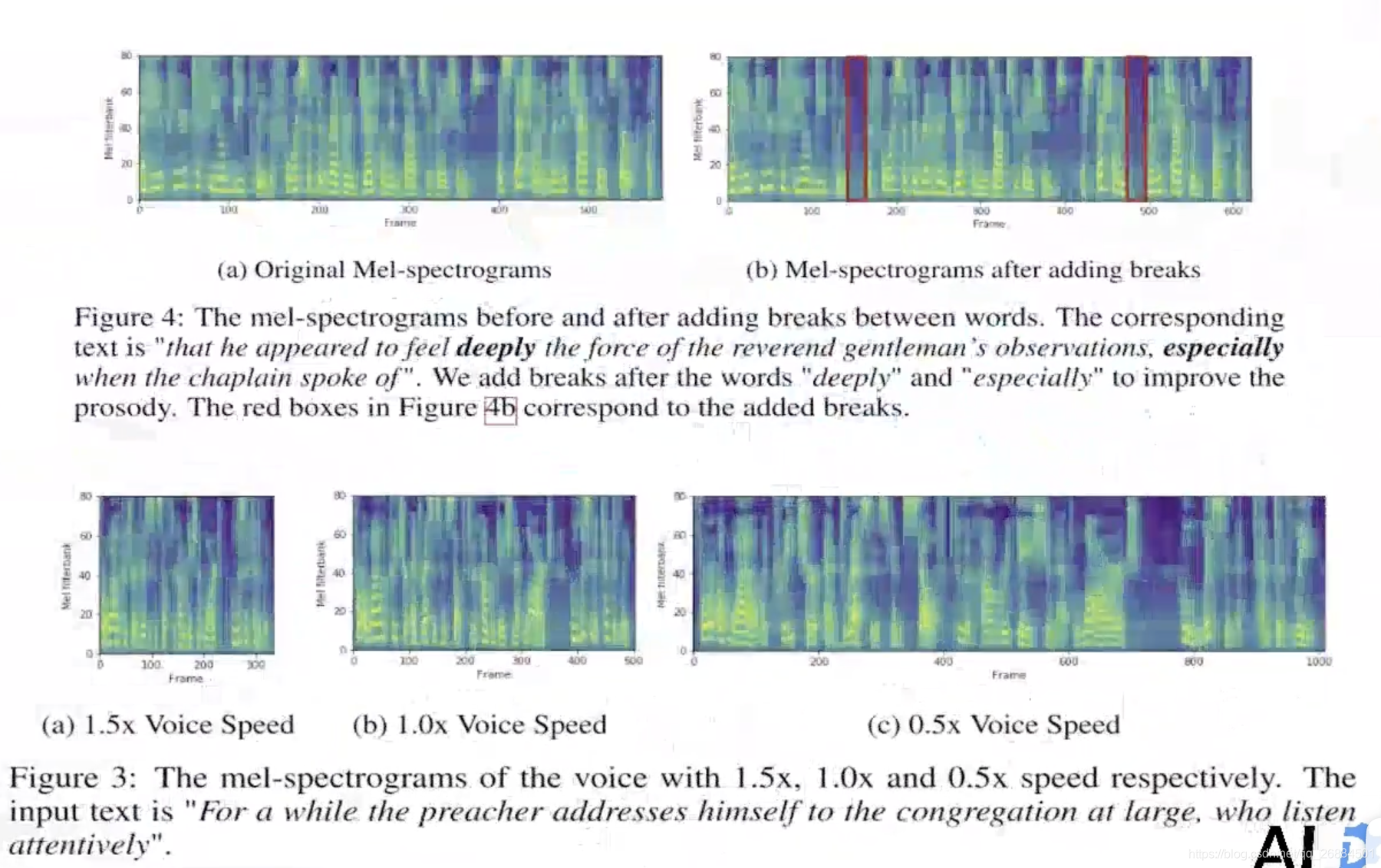
音高,能量,音速,音色
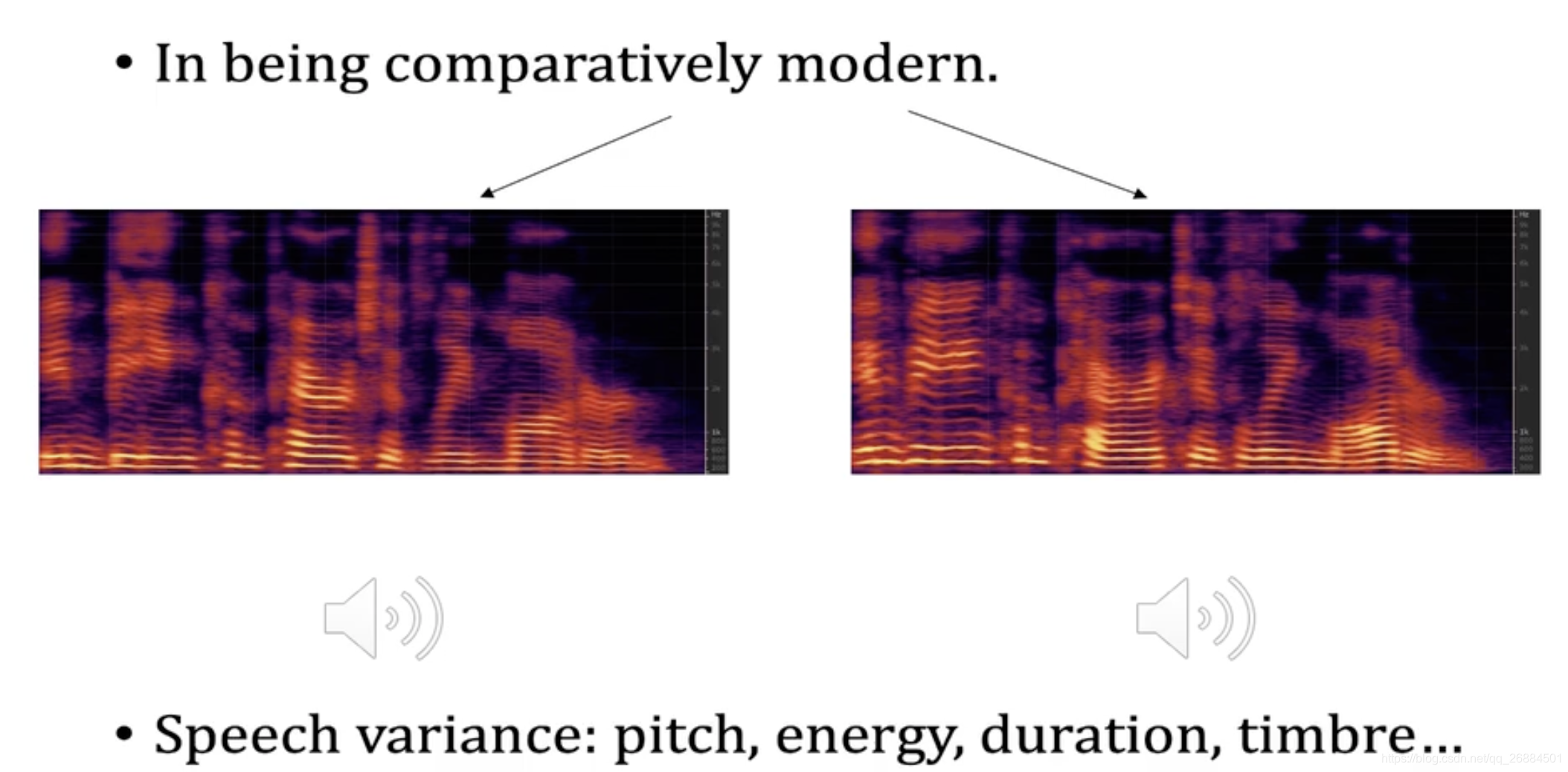
fastspeech的缺点

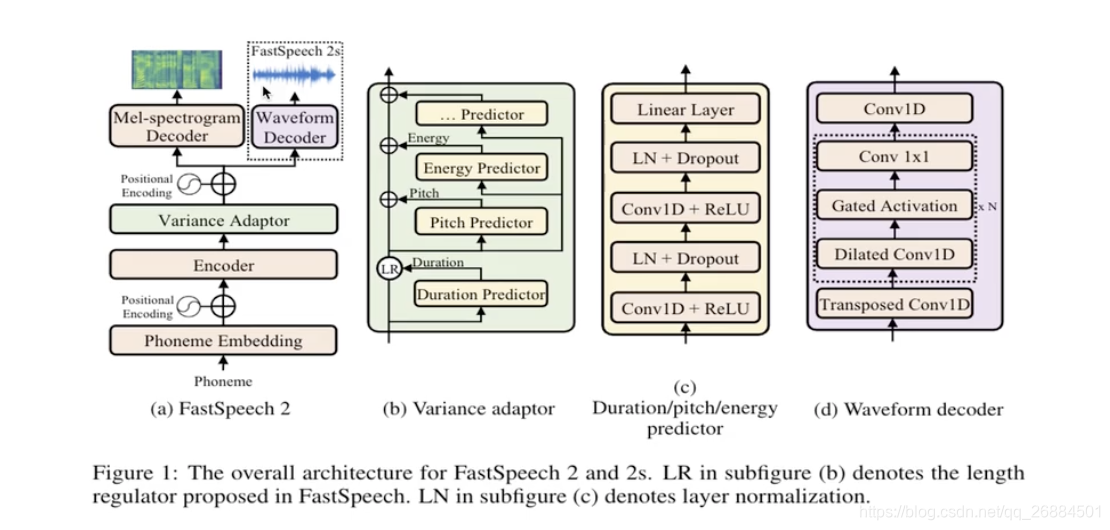
fastspeech2

解决了词长预测不准确和知识蒸馏引入的信息损失
fastspeech2s实现了将文本直接变为波形
模型架构

















 1040
1040

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









