







目录
2.1图相关知识
2.1.1图的定义
在计算机科学中,”图“(英语:graph)是一种抽象数据类型,用于实现数学中图论的无向图和有向图的概念。
图的数据结构包含一个有限(可能是可变的)的集合作为节点集合,以及一个无序对(对应无向图)或有序对(对应有向图)的集合作为边(有向图中也称作弧)的集合。节点可以是图结构的一部分,也可以是用整数下标或引用表示的外部实体。
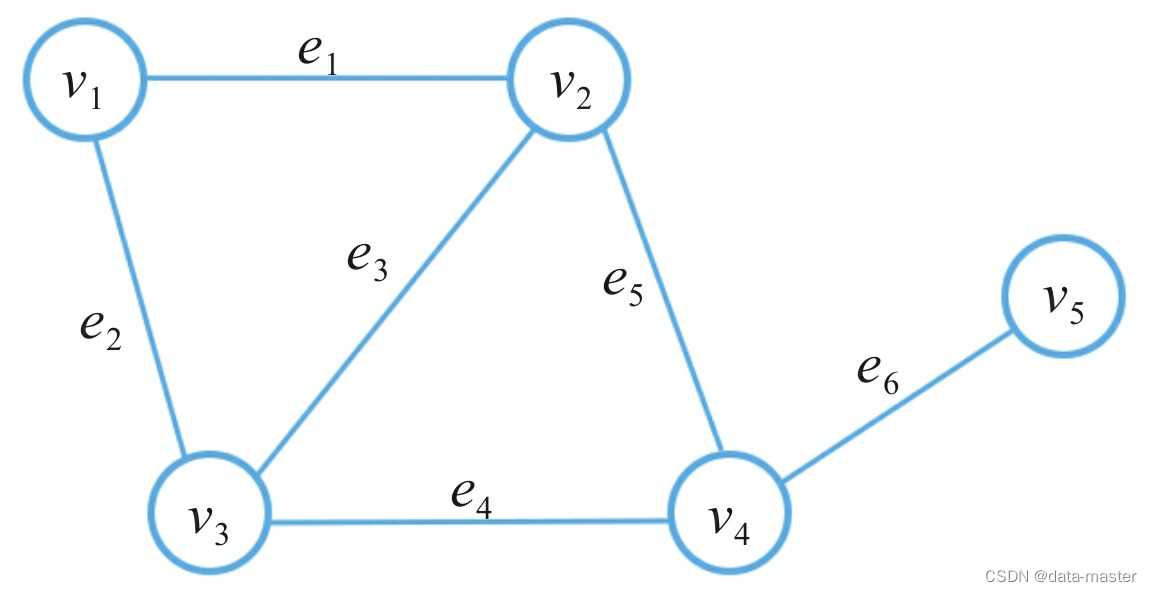
图的数据结构还可能包含和每条边相关联的数值(edge value),例如一个标号或一个数值(即权重,weight;表示花费、容量、长度等)。下面为一个三个节点和三个边的有向图:
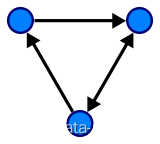
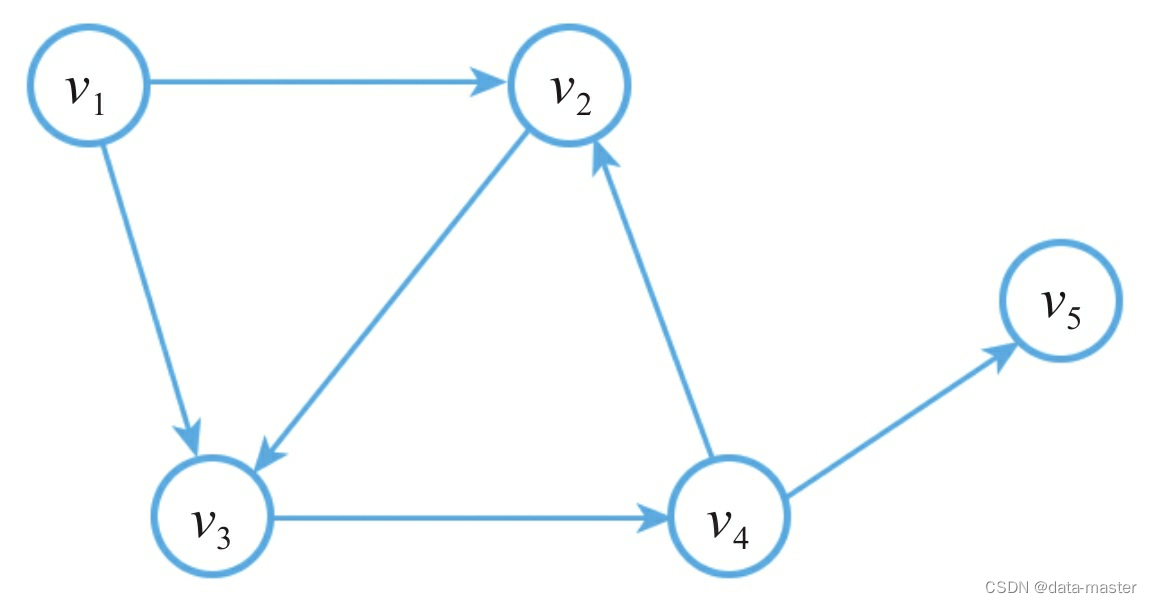
有向图和无向图:如果图中的边存在方向性,则称这样的边为有向边eij=<vi,vj>,其中vi是这条有向边的起点,vj是这条有向边的终点,包含有向边的图称为有向图,如图所示。与有向图相对应的是无向图,无向图中的边都是无向边,我们可以认为无向边是对称的,同时包含两个方向:eij= <vi,vj> = <vj,vi> =eji。
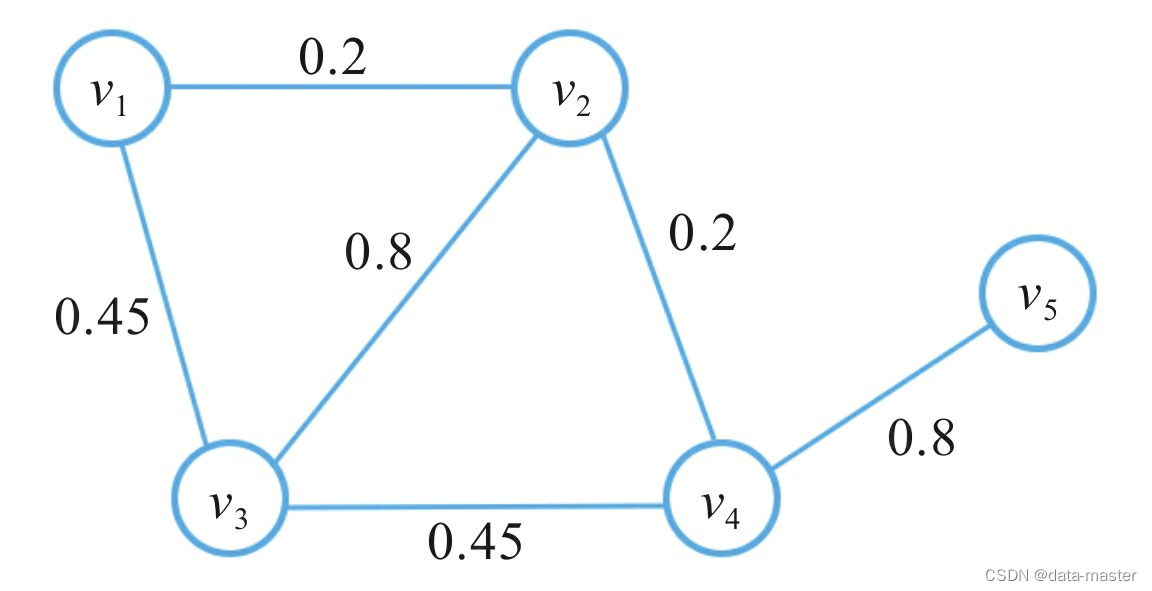
非加权图与加权图:如果图里的每条边都有一个实数与之对应,我们称这样的图为加权图,如图所示该实数称为对应边上的权重。在实际场景中,权重可以代表两地之间的路程或运输成 本。一般情况下,我们习惯把权重抽象成两个顶点之间的连接强度。与之相反的是非加权图,我们可以认为非加权图各边上的权重是一样的。
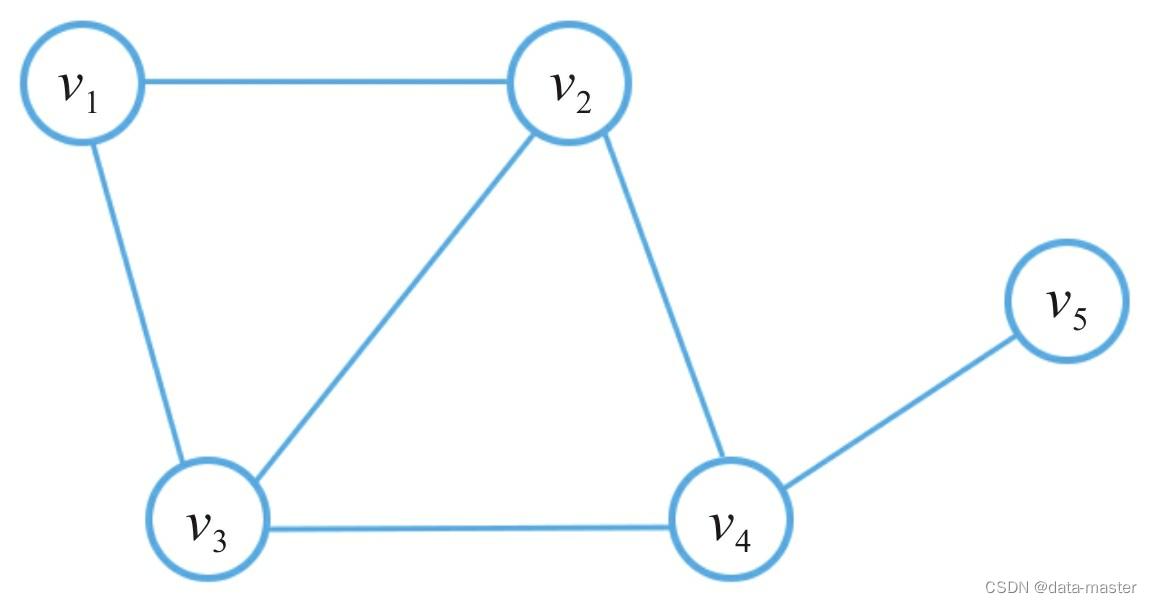
连通图与非连通图:如果图中存在孤立的顶点,没有任何边与之相连,这样的图被称为非连通图,如所示。相反,不存在孤立顶点的图称为连通图。
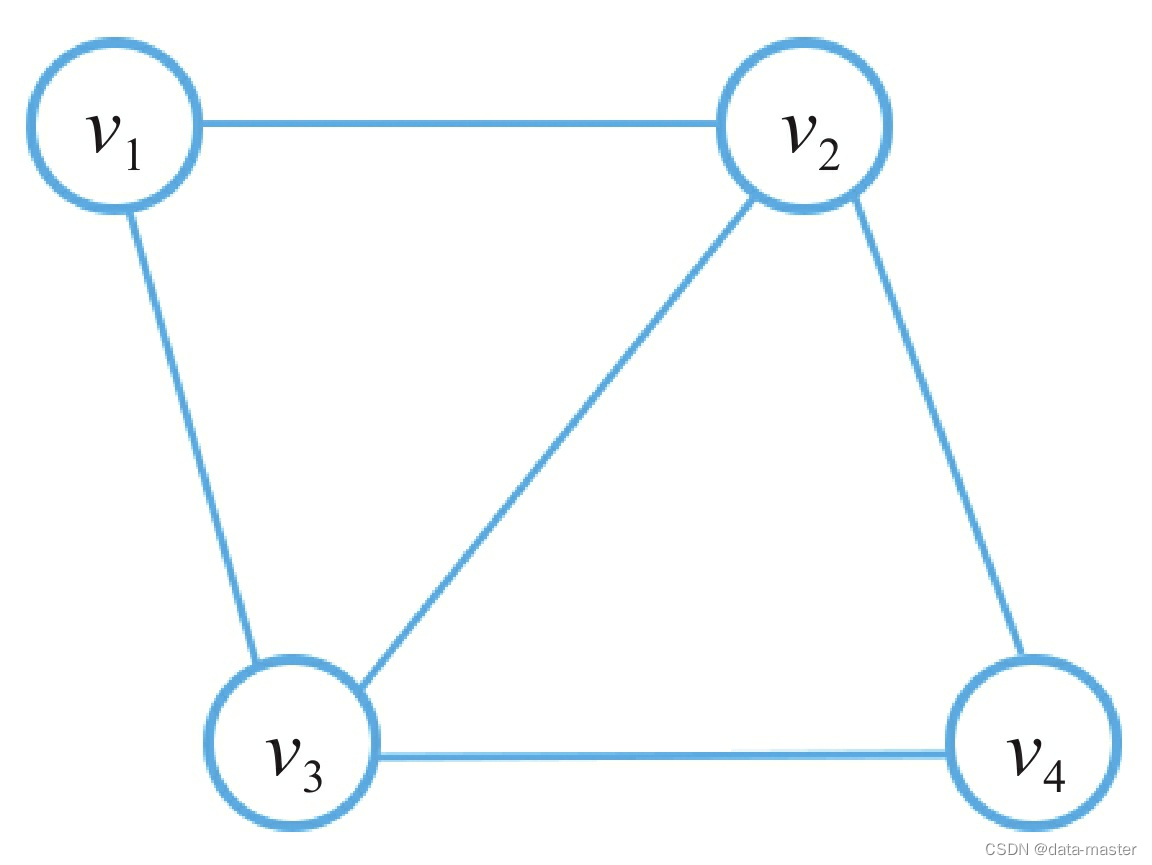
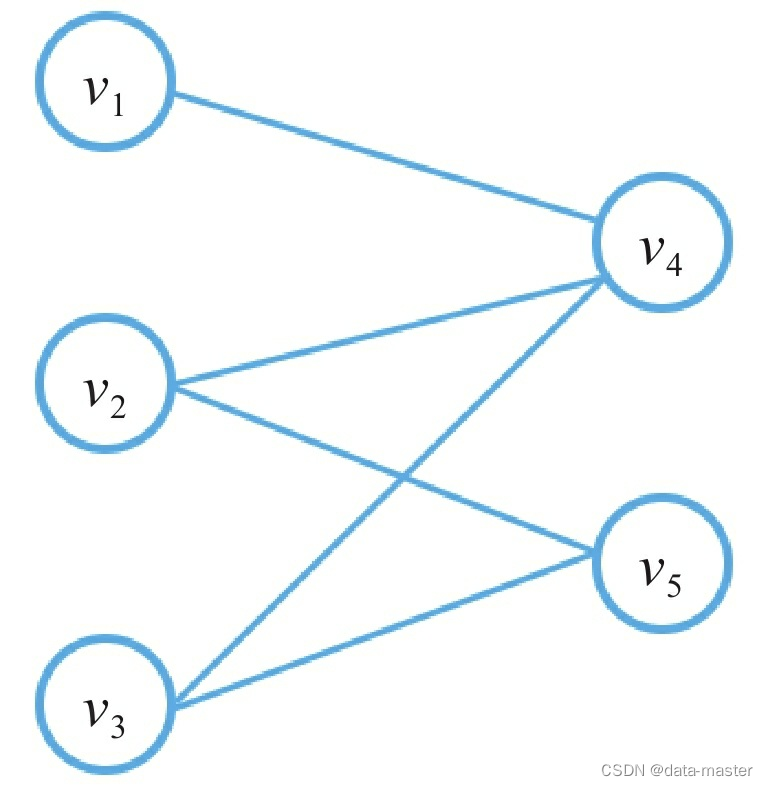
二部图:二部图是一类特殊的图。我们将G中的顶点集合V拆分成两个子集A和B,如果对于图中的任意一条边eij均有vi∈A,vj∈B或者vi∈B,vj∈A,则称图G为二部图,如图所示。二部图是一种十分常见的图数据对象,描述了两类对象之间的交互关系,比如:用户 与商品、作者与论文
如果存在一条边连接顶点vi和vj,则称vj是vi的邻居,反之亦然。我们记vi的所有邻居为(vi),即:
在有向图中,我们同时定义出度(Outdegree)和入度(Indegree),顶点的度数等于该顶点的出度与入度之和。其中,顶点vi的出度是以vi为起点的有向边的数目,顶点vi的入度是以vi为终点的有向边的数目。
子图和路径:
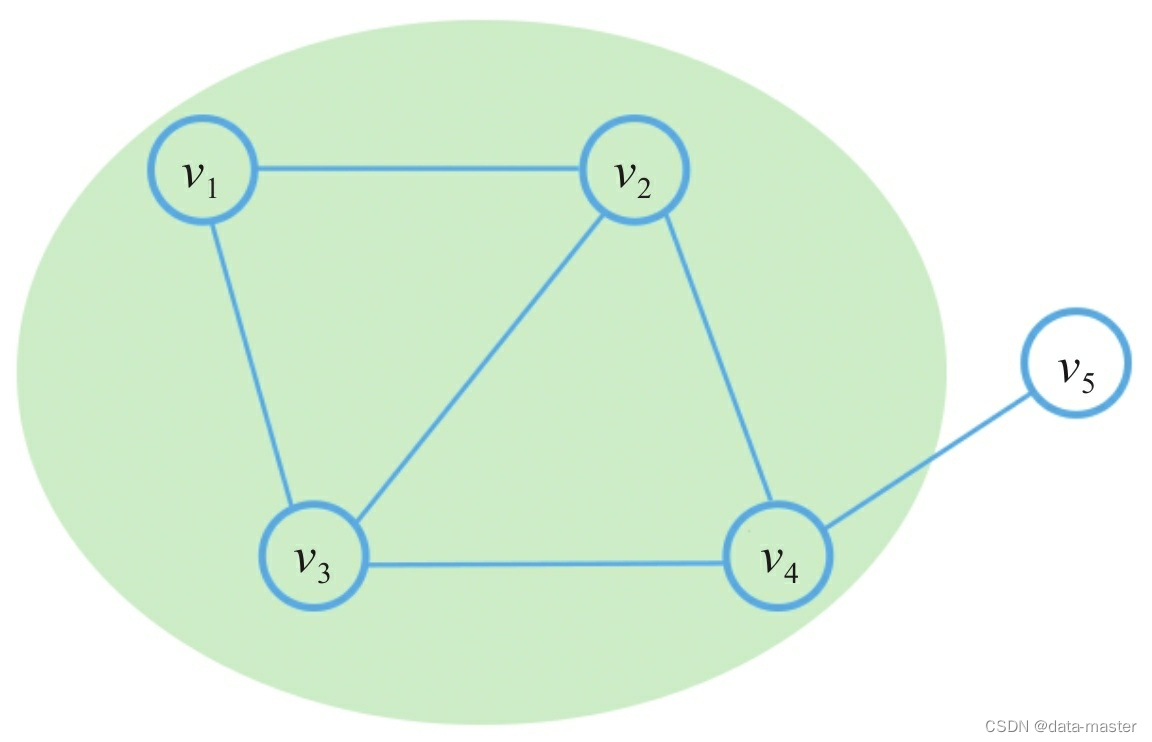
若图G'=(V',E')的顶点集和边集分别是另一个图G=(V,E)的顶点集的子集和边集的子集,即V'⊆V,且E'⊆E,则称图G'是图G的子图(Subgraph)。阴影部分就是顶点V1的2阶子图。
图直径:图中所有的两两节点,他们最短路径中得最大的那个值,就叫图直径
中心性算法 (Centrality Algorithms) - 知乎 (zhihu.com)
注:此处为转载,但有部分修改
度中心性(Degree Centrality):
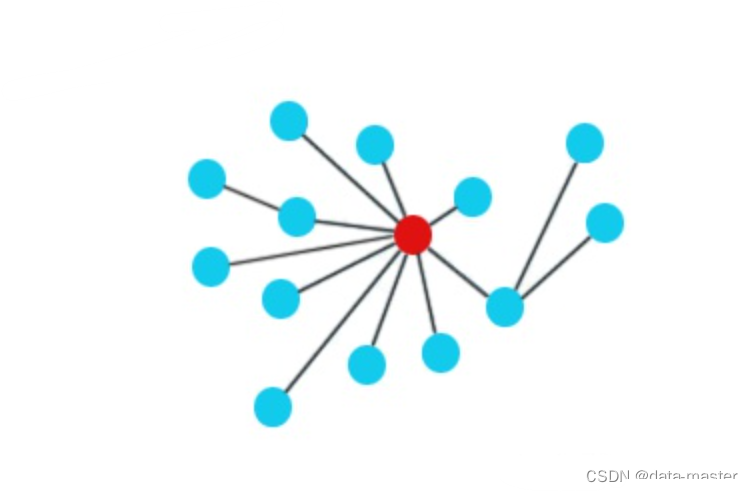
在无向图(Undirected Graph)中,度中心性测量网络中一个节点与所有其它节点直接相连的程度。对于一个拥有g个节点的无向图,节点i的度中心性是i与其它g-1个节点的直接联系总数(如果是有向图,则需要考虑的出度和入度的问题):
由上述公式可见,网络规模越大,度中心性的最大可能值就越高。为了消除网络规模变化对度中心性的影响,需要进行标准化:
【示例】在一场有50人的派对里,A与其中的30人相识,而B只与其中的10人相识。在派对人数规模一样的情况下,根据相识的人数。可以看得出来A的社交圈子要比B更加广,也就是说A的度中心性高于B,即:
接近中心性(Closeness Centrality):接近中心性反映在网络中某一节点与其他节点之间的接近程度。不同于度中心性考虑直接相连的情况,接近中心性需要考量每个结点到其它结点的最短路径的平均长度。也就是说,对于一个结点而言,它距离其它结点越近,那么它的中心度越高。计算方式如下:
其中dis(i,j)表示节点i到节点j的距离。之所以对距离和取倒数,是为了方便表示,因为这样就可以直观地表示为:值越大,其接近中心性越高。在刚刚我们说到要考量最短路径的平均长度,更常见的表示方法是将此分数标准化,使其表示最短路径的平均长度,而不是它们的和。标准化的接近中心性计算公式如下:
由上述公式可见,如果节点到图中其它节点的最短距离都很小,那么我们可以认为该节点的接近中心性较高。显然,这个定义比度中心性在几何上更符合中心性的概念,因为到其它节点的平均最短距离最小,意味着这个节点从几何角度看是位于图的中心位置。
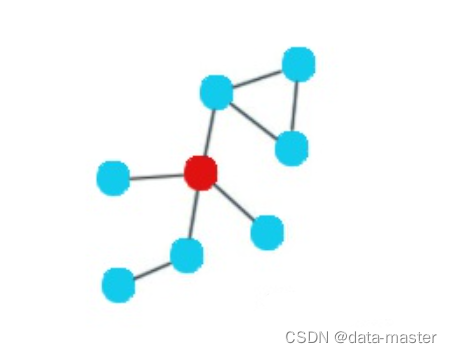
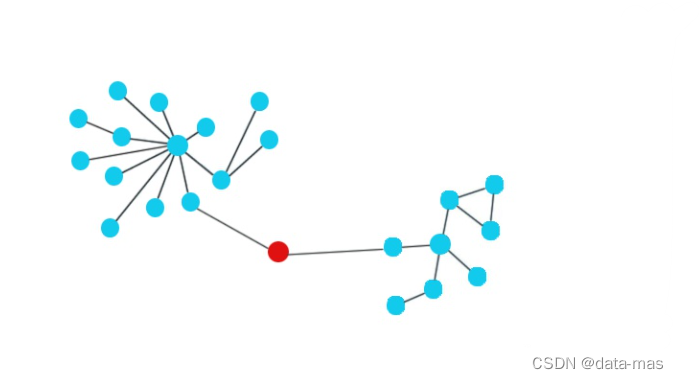
中介中心性(Between Centrality) :中介中心性用于衡量一个顶点出现在其他任意两个顶点对之间的最短路径的次数,从而来刻画节点重要性。中介中心性测量了某个节点在多大程度上能够成为“中介”,即在多大程度上控制他人。如果一个节点处于多个节点之间,则可以认为该节点起到重要的“中介”作用,处于该位置的人可以控制信息的传递而影响群体。
计算方式如下:
其中sd(j,i,k)表示j到k的最短路径经过了i,即i处于j到k的最短路径上。同样地,可以对进行标准化:
进行标准化:其中分母表示图中两点间路径的条数,即所有路径的数量。
【示例】主要用于衡量一个顶点在图或网络中承担“桥梁”角色的程度,该中心性经常用于反欺诈场景里中介实体的识别。例如,婚介所的媒人,同样可以视为“桥梁”。社交圈子里的社交达人,也是如此。
特征向量中心性(Eigenvector Centrality):一个节点的重要性既取决于其邻居节点的数量(即该节点的度),也取决于其邻居节点的重要性。
假设表示节点i的重要性,则特征向量中心性计算如下:
其中c为一个比例常数,当且仅当i与j相连,否则为0。
2.1.2图的相关操作
图数据结构G支持的基本操作通常包括:
adjacent(G, x, y):查看是否存在从节点x到y的边;neighbors(G, x):列出所有从x出发的边的另一个顶点y;add_vertex(G, x):如果不存在,将节点x添加进图;remove_vertex(G, x):如果存在,从图中移除节点x;add_edge(G, x, y):如果不存在,添加一条从节点x到y的边;remove_edge(G, x, y):如果存在,从图中移除从节点x到y的边;get_vertex_value(G, x):返回节点x上的值;set_vertex_value(G, x, v):将节点x上的值赋为v。
如果该数据结构支持和边关联的数值,则通常也支持下列操作:
get_edge_value(G, x, y):返回边(x, y)上的值;set_edge_value(G, x, y, v):将边(x, y)上的值赋为v。
2.1.3图的常见数据结构
邻接表:
节点存储为记录或对象,且为每个节点创建一个列表。这些列表可以按节点存储其余的信息;例如,若每条边也是一个对象,则将边存储到边起点的列表上,并将边的终点存储在边这个的对象本身。
邻接矩阵与关联矩阵:
用邻接矩阵存储图的时候,我们需要一个一维数组表示顶点集合,需要一个二维数组表示邻接矩阵。需要特别说明的是,由于在实际的图数据中,邻接矩阵往往会出现大量的0值,因此可以用稀疏矩阵的格式来存储邻接矩阵,这样可以将邻接矩阵的空间复杂度控制在O(M)的范围内。图中a图给出了图G的邻接矩阵存储表示,通过该图可以看出,无向图的邻接矩阵是沿主对角线对称的,即Aij=Aji。
用关联矩阵存储图的时候,我们需要两个一维数组分别表示顶点集合和边集合,需要一个二维数组表示关联矩阵。同样,关联矩阵也可以用稀疏矩阵来存储,这是因为B的任意一列仅有两个非0值。图中b图展示了用关联矩阵来存储图的示例。

pagerank:来自受欢迎的网页的跳转应该重于不太受欢迎的网页的跳转
图或网络中的中心性:点度中心性、中介中心性、接近中心性、特征向量中心性、PageRank_不务正业的土豆的博客-CSDN博客

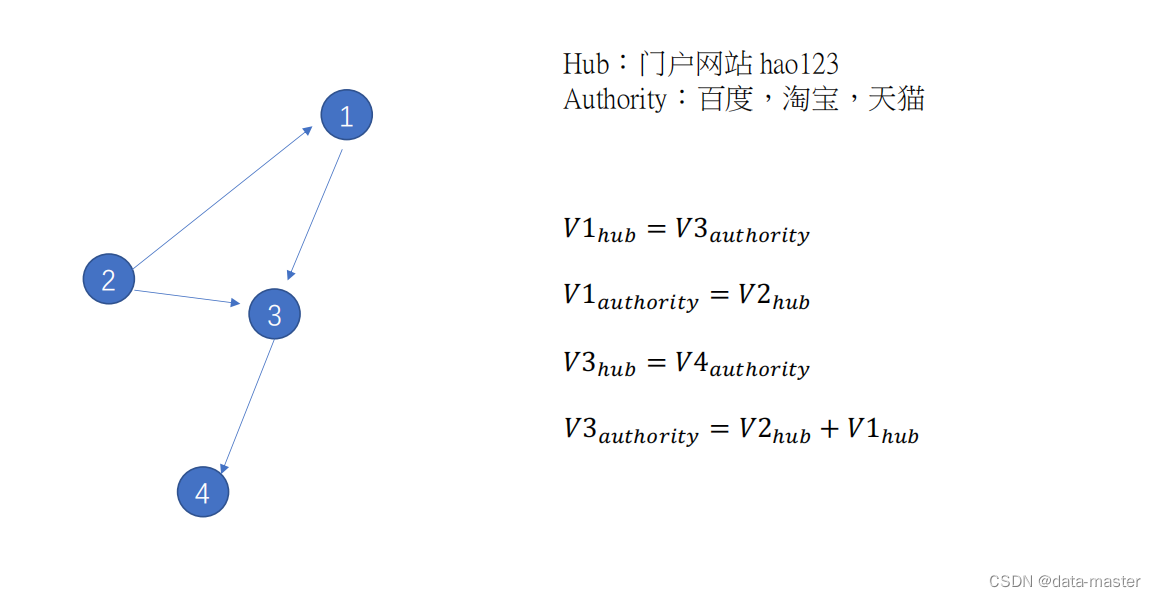
HITS:HITS算法的全称是Hyperlink-Induced Topic Search。在HITS算法中,每个页面被赋予两个属性:hub属性和authority属性。同时,网页被分为两种:hub页面和authority页面。hub,中心的意思,所以hub页面指那些包含了很多指向authority页面的链接的网页,比如国内的一些门户网站;authority页面则指那些包含有实质性内容的网页。HITS算法的目的是:当用户查询时,返回给用户高质量的authority页面。
Random Walk:随机游走(Random Walk)算法从图上获得一条随机的路径。随机游走算法从一个节点开始,随机沿着一条边正向或者反向寻找到它的邻居,以此类推,直到达到设置的路径长度。这个过程有点像是一个醉汉在城市闲逛,他可能知道自己大致要去哪儿,但是路径可能极其“迂回”,毕竟,他也无法控制自己。图算法:概览 (qq.com)
随机游走算法一般用于随机生成一组相关的节点数据,作为后续数据处理或者其他算法使用。例如:
-
作为 node2vec 和 graph2vec 算法的一部分,这些算法可以用于节点向量的生成,从而作为后续深度学习模型的输入;这一点对于了解 NLP (自然语言处理)的朋友来说并不难理解,词是句子的一部分,我们可以通过词的组合(语料)来训练词向量。那么,我们同样可以通过节点的组合(Random Walk)来训练节点向量。这些向量可以表征词或者节点的含义,并且能够做数值计算。这一块的应用很有意思,我们会找机会来详细介绍;
-
作为 Walktrap 和 Infomap 算法的一部分,用于社群发现。如果随机游走总是返回同一组节点,表明这些节点可能在同一个社群;
-
其他机器学习模型的一部分,用于随机产生相关联的节点数据。
2.Graph Embedding
图嵌入(Graph Embedding,也叫Network Embedding)是一种将图数据(通常为高维稠密的矩阵)映射为低微稠密向量的过程,能够很好地解决图数据难以高效输入机器学习算法的问题。
机器学习图形是有限的。图由边和节点组成。这些网络关系只能使用数学、统计和机器学习的特定子集,而向量空间有更丰富的方法工具集。
嵌入是压缩的表示。邻接矩阵描述图中节点之间的连接。它是一个|V| x |V|矩阵,其中|V|是图中节点的个数。矩阵中的每一列和每一行表示一个节点。矩阵中的非零值表示两个节点相连。使用邻接矩阵作为大型图的特征空间几乎是不可能的。假设一个图有1M个节点和一个1M x 1M的邻接矩阵。嵌入比邻接矩阵更实用,因为它们将节点属性打包到一个维度更小的向量中。
向量运算比图形上的可比运算更简单、更快。
图嵌入是将属性图转换为向量或向量集。嵌入应该捕获图的拓扑结构、顶点到顶点的关系以及关于图、子图和顶点的其他相关信息。更多的属性嵌入编码可以在以后的任务中获得更好的结果。我们可以将嵌入式大致分为两类:
- 顶点嵌入:每个顶点(节点)用其自身的向量表示进行编码。这种嵌入一般用于在顶点层次上执行可视化或预测。比如,在2D平面上显示顶点,或者基于顶点相似性预测新的连接。
- 图嵌入:用单个向量表示整个图。这种嵌入用于在图的层次上做出预测,可者想要比较或可视化整个图。例如,比较化学结构。
2.1Embedding
one-hot编码简介:
独热编码即 One-Hot 编码,又称一位有效编码,其方法是使用N位状态寄存器来对N个状态进行编码,每个状态都有它独立的寄存器位,并且在任意时候,其中只有一位有效。举个例子,假设我们有四个样本(行),每个样本有三个特征(列),如图:

我们的feature_1有两种可能的取值,比如是男/女,这里男用1表示,女用2表示。feature_2 和feature_3各有4种取值(状态)。one-hot编码就是保证每个样本中的单个特征只有1位处于状态1,其他的都是0。上述状态用one-hot编码如下图所示:
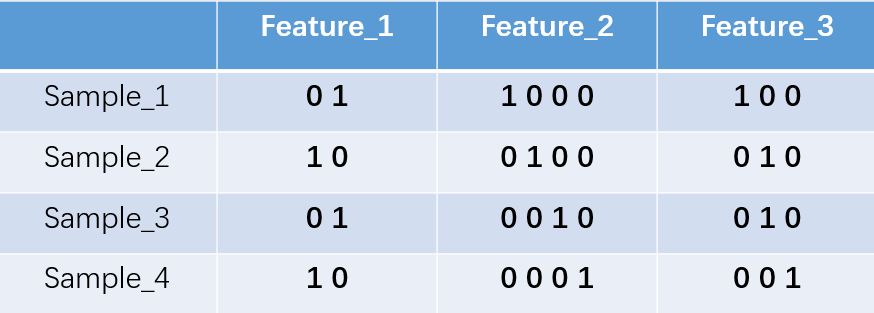
假设上表对应着以下的特征:
["male", "female"]
["from Europe", "from US", "from Asia"]
["uses Firefox", "uses Chrome", "uses Safari", "uses Internet Explorer"]
将它换成独热编码后,应该是:
feature1=[01,10]
feature2=[001,010,100]
feature3=[0001,0010,0100,1000]
优缺点分析
优点:一是解决了分类器不好处理离散数据的问题,二是在一定程度上也起到了扩充特征的作用。
缺点:在文本特征表示上有些缺点就非常突出了。首先,它是一个词袋模型,不考虑词与词之间的顺序(文本中词的顺序信息也是很重要的);其次,它假设词与词相互独立(在大多数情况下,词与词是相互影响的);最后,它得到的特征是离散稀疏的。
为什么得到的特征是离散稀疏的?
上面举例比较简单,但现实情况可能不太一样。比如如果将世界所有城市名称作为语料库的话,那这个向量会过于稀疏,并且会造成维度灾难。
杭州 [0,0,0,0,0,0,0,1,0,……,0,0,0,0,0,0,0]
上海 [0,0,0,0,1,0,0,0,0,……,0,0,0,0,0,0,0]
宁波 [0,0,0,1,0,0,0,0,0,……,0,0,0,0,0,0,0]
北京 [0,0,0,0,0,0,0,0,0,……,1,0,0,0,0,0,0]
在语料库中,杭州、上海、宁波、北京各对应一个向量,向量中只有一个值为1,其余都为0。
能不能把词向量的维度变小呢?
Dristributed representation可以解决One hot representation的问题,它的思路是通过训练,将每个词都映射到一个较短的词向量上来。所有的这些词向量就构成了向量空间,进而可以用普通的统计学的方法来研究词与词之间的关系。这个较短的词向量维度是多大呢?这个一般需要我们在训练时自己来指定。
比如下图我们将词汇表里的词用"Royalty","Masculinity", "Femininity"和"Age"4个维度来表示,King这个词对应的词向量可能是(0.99,0.99,0.05,0.7)(0.99,0.99,0.05,0.7)。当然在实际情况中,我们并不能对词向量的每个维度做一个很好的解释。

我们将king这个词从一个可能非常稀疏的向量坐在的空间,映射到现在这个四维向量所在的空间,必须满足以下性质:
(1)这个映射是单设(不懂的概念自行搜索);
(2)映射之后的向量不会丢失之前的那种向量所含的信息。
这个过程称为word embedding(词嵌入),即将高维词向量嵌入到一个低维空间。顺便找了个图
通俗理解word2vec - 简书 (jianshu.com)
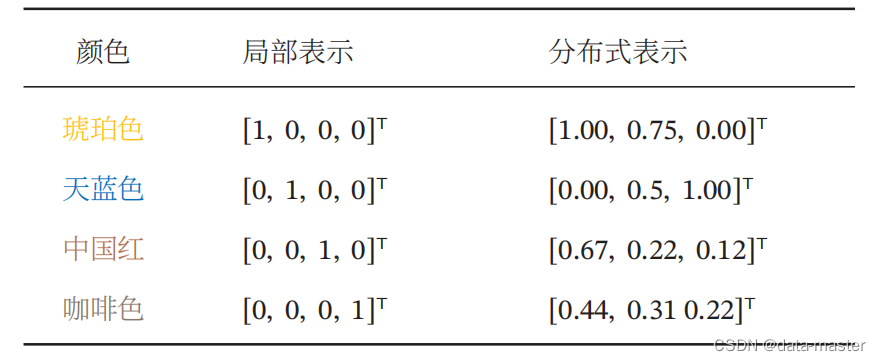
在机器学习中,我们经常使用两种方式来表示特征:局部表示(Local Representation)和分布式表示(Distributed Representation)
以颜色表示为例,我们可以用很多词来形容不同的颜色1,除了基本的“红”“蓝”“绿”“白”“黑”等之外,还有很多以地区或物品命名的,比如“中国红”“天蓝色”“咖啡色”“琥珀色”等.如果要在计算机中表示颜色,一般有两种表示方法.一种表示颜色的方法是以不同名字来命名不同的颜色,这种表示方式叫作局部表示,也称为离散表示或符号表示.局部表示通常可以表示为one-hot 向量的形式.one-hot 向量参见假设所有颜色的名字构成词表|V|.我们可以用一个|V| 维的one-hot 向量来表示每一种颜色.在第i 种颜色对应的one-hot 向量中,第i 维的值为1,其他都为0。
局部表示有两个优点:
1)这种离散的表示方式具有很好的解释性,有利于人工归纳和总结特征,并通过特征组合进行高效的特征工程;
2)通过多种特征组合得到的表示向量通常是稀疏的二值向量,当用于线性模型时计算效率非常高.
但局部表示有两个不足之处:
1)one-hot向量的维数很高,且不能扩展.如果有一种新的颜色,我们就需要增加一维来表示;
2)不同颜色之间的相似度都为0,即我们无法知道“红色”和“中国红”的相似度要高于“红色”和“黑色”的相似度
另一种表示颜色的方法是用RGB值来表示颜色,不同颜色对应到R、G、B三维空间中一个点,这种表示方式叫作分布式表示. 将分布式表示叫作分散式表示可能更容易理解,即一种颜色的语义分散到语义空间中的不同基向量上。分布式表示通常可以表示为低维的稠密向量。
和局部表示相比,分布式表示的表示能力要强很多,分布式表示的向量维度一般都比较低。我们只需要用一个三维的稠密向量就可以表示所有颜色。并且,分布式表示也很容易表示新的颜色名。此外,不同颜色之间的相似度也很容易计算。
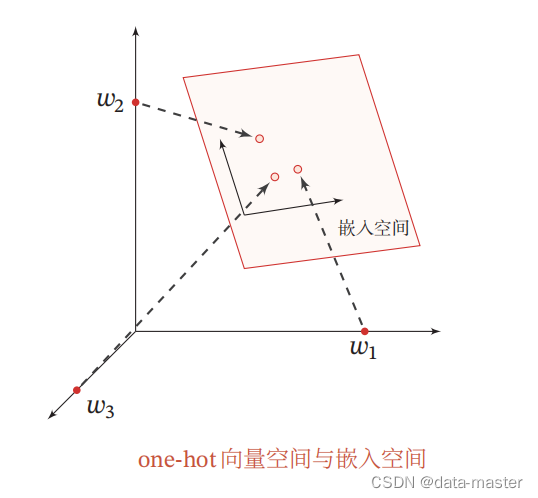
我们可以使用神经网络来将高维的局部表示空间映射到一个非常低维的分布式表示空间: D≪ |
|.在这个低维空间中,每个特征不再是坐标轴上的点,而是分散在整个低维空间中.在机器学习中,这个过程也称为嵌入(Embedding).嵌入通常指将一个度量空间中的一些对象映射到另一个低维的度量空间中,并尽可能保持不同对象之间的拓扑关系.比如自然语言中词的分布式表示,也经常叫作词嵌入。
下图展示了一个3维one-hot向量空间和一个2维嵌入空间的对比.图中有三个样本。在 one-hot 向量空间中,每个样本都位于坐标轴上,每个坐标轴上一个样本.而在低维的嵌入空间中,每个样本都不在坐标轴上,样本之间可以计算相似度。同理也是一样的,低维的数据可能包含的特征是非常笼统的,我们需要不停地拉近拉远来改变我们的感受,让我们对这幅图有不同的观察点,找出我们要的"茬"。Embedding的又一个作用体现了:对低维的数据进行升维时,可能把一些其他特征给放大了,或者把笼统的特征给分开了。
Embedding层,在某种程度上,就是用来降维的,降维的原理就是矩阵乘法。下面看个例子: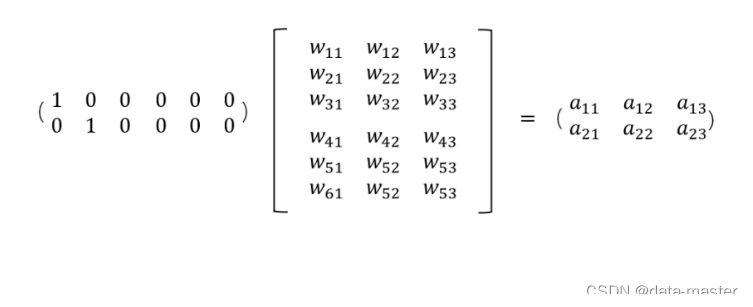
word2vec:word2vec也叫word embeddings,中文名“词向量”,作用就是将自然语言中的字词转为计算机可以理解的稠密向量(Dense Vector)。在word2vec出现之前,自然语言处理经常把字词转为离散的单独的符号,也就是One-Hot Encoder。Word2vec是一类神经网络模型——在给定无标签的语料库的情况下,为语料库中的单词产生一个能表达语义的向量。这些向量通常是有用的:
Word2Vec是轻量级的神经网络,其模型仅仅包括输入层、隐藏层和输出层,模型框架根据输入输出的不同,主要包括CBOW和Skip-gram模型。 CBOW的方式是在知道词的上下文
,
,
,
的情况下预测当前词
。而Skip-gram是在知道了词
的情况下,对词
的上下 文
,
,
,
进行预测,如下图所示:
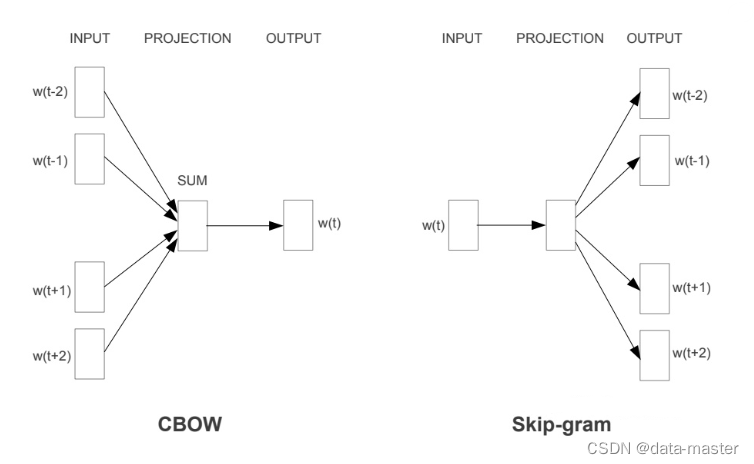
CBOW:CBOW和skip-gram两者模型互为镜像,CBOW的神经网络模型与skip-gram的神经网络模型也是互为镜像的。
这里输入层是由one-hot编码的输入上下文组成,其中窗口大小为C,词汇表大小为V。隐藏层是N维的向量。最后输出层是也被one-hot编码的输出单词y。被one-hot编码的输入向量通过一个V×N维的权重矩阵W连接到隐藏层;隐藏层通过一个N×V 的权重矩阵W ′连接到输出层。
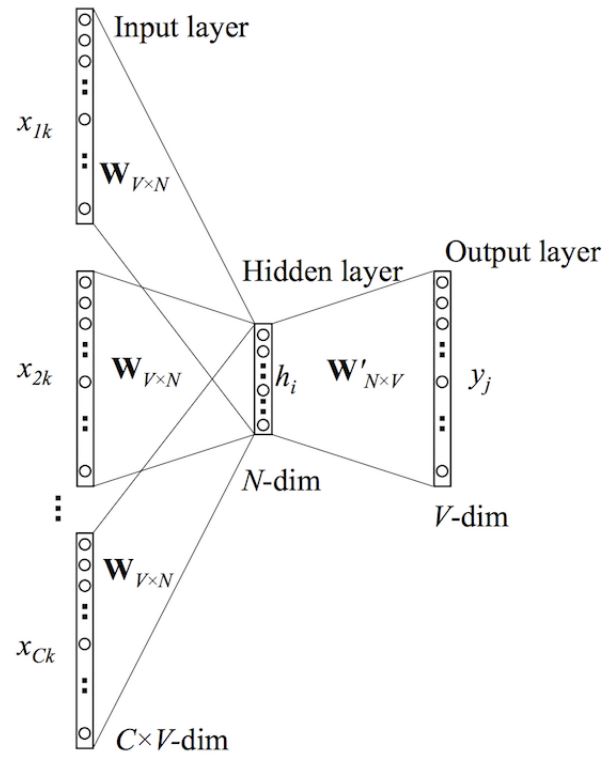
第一步就是去计算隐藏层h的输出。如下:该输出就是输入向量的加权平均。这里的隐藏层与skip-gram的隐藏层明显不同。
第二步就是计算在输出层每个结点的输入。如下:
其中是输出矩阵
的第j列。
最后我们计算输出层的输出,输出:
通过BP(反向传播)算法及随机梯度下降来学习权重:
在学习权重矩阵W与W ′ 过程中,我们可以给这些权重赋一个随机值来初始化。然后按序训练样本,逐个观察输出与真实值之间的误差,并计算这些误差的梯度。并在梯度方向纠正权重矩阵。这种方法被称为随机梯度下降。但这个衍生出来的方法叫做反向传播误差算法。
首先就是定义损失函数,这个损失函数就是给定输入上下文的输出单词的条件概率,一般都是取对数,如下所示:
接下来就是对上面的概率求导,具体推导过程可以去看BP算法,我们得到输出权重矩阵W ′的更新规则:
同理权重W的更新规则如下:
skip-gram模型:
转自:轻松理解skip-gram模型_小虎AI实验室的博客-CSDN博客

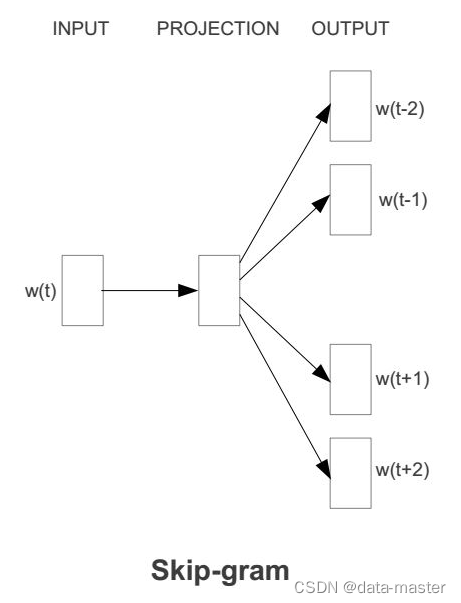
前向传播:接下来我们来看下skip-gram神经网络模型,skip-gram的神经网络模型是从前馈神经网络模型改进而来,说白了就是在前馈神经网络模型的基础上,通过一些技巧使得模型更有效。我们先上图,看一波skip-gram的神经网络模型:
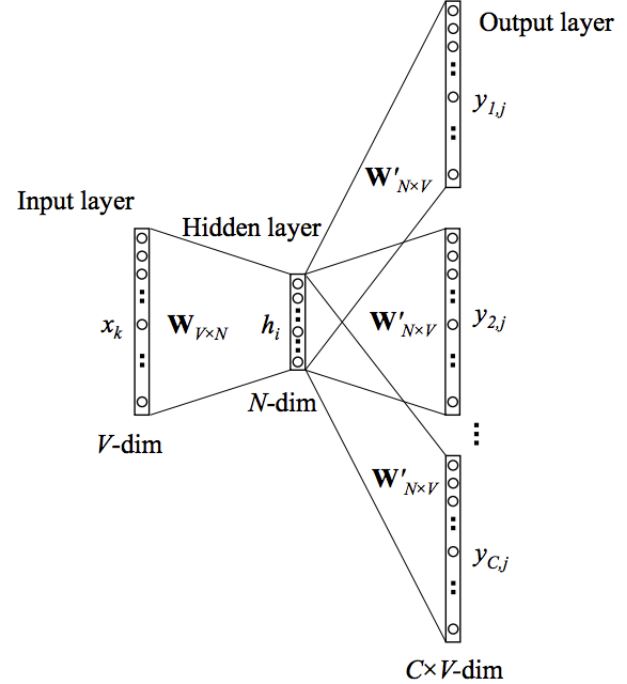
在上图中,输入向量x代表某个单词的one-hot编码,对应的输出向量{
,…,
}。输入层与隐藏层之间的权重矩阵W的第i行代表词汇表中第i个单词的权重。接下来重点来了:这个权重矩阵W就是我们需要学习的目标(同W ′),因为这个权重矩阵包含了词汇表中所有单词的权重信息。上述模型中,每个输出单词向量也有个N × V 维的输出向量W ′ 。最后模型还有N 个结点的隐藏层,我们可以发现隐藏层节点
的输入就是输入层输入的加权求和。因此由于输入向量x是one-hot编码,那么只有向量中的非零元素才能对隐藏层产生输入。因此对于输入向量x其中
,并且
所以隐藏层的输出只与权重矩阵第k行相关,从数学上证明如下:
注意因为输入时one-hot编码,所以这里是不需要使用激活函数的。同理,模型输出结点C×V的输入也是由对应输入结点的加权求和计算得到:
其实从上图我们也看到了输出层中的每个单词都是共享权重的,因此我们有。最终我们通过softmax函数产生第C CC个单词的多项式分布。
这个值就是第C个输出单词的第j个结点的概率大小。
通过BP(反向传播)算法及随机梯度下降来学习权重:
skip-gram模型的输入向量及输出的概率表达,以及我们学习的目标。接下来我们详细讲解下学习权重的过程。第一步就是定义损失函数,这个损失函数就是输出单词组的条件概率,一般都是取对数,如下所示:
接下来就是对上面的概率求导,具体推导过程可以去看BP算法,我们得到输出权重矩阵W ′ 的更新规则:
同理权重W的更新规则如下:
从上面的更新规则,我们可以发现,每次更新都需要对整个词汇表求和,因此对于很大的语料库来说,这个计算复杂度是很高的。于是在实际应用中,Google的Mikolov等人提出了分层softmax及负采样可以使得计算复杂度降低很多。
其实说白了就是通过训练学习W 和W ′两个矩阵
如果还是觉得太抽象建议看一下:图解Word2vec,读这一篇就够了 (qq.com)
一文读懂Embedding的概念,以及它和深度学习的关系 - 知乎 (zhihu.com)
2.2DeepWalk
它的输入是一张图或者网络,输出为网络中顶点的向量表示。DeepWalk通过截断随机游走(truncated random walk)学习出一个网络的社会表示(social representation),在网络标注顶点很少的情况也能得到比较好的效果。并且该方法还具有可扩展的优点,能够适应网络的变化。
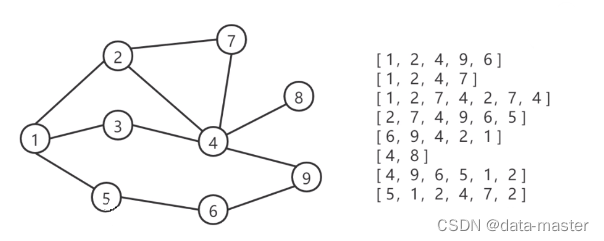
DeepWalk 涉及到的随机游走是一种可重复访问已访问节点的深度优先遍历(DFS)算法。给定起始节点,从该节点的邻居中随机选取访问节点,并将新的节点作为起始点继续探索,当该节点没有邻居或者达到序列长度时,退出循环。这里有几个点:
A.可重复访问
如果1只关注了2,恰巧2只关注了1,固定序列长度为10,起始点为1,则会生成 1-2-1-2-1-2-1-2-1-2 的关注关系序列。(就是把一定要把固定序列长度走完)
B.深度优先遍历
可以把生成用户序列的过程理解为不断的二叉树划分,这里不断寻找新节点的邻居就可以看作是 DFS 遍历一颗树。在 Node2vec 算法中,涉及到了转移概率p,q,其中p,q的值代表了 walk 更偏向于 BFS 还是 DFS,后续介绍 Node2vec 可以详细盘一下。
C.关于有向图还是无向图
生成序列时需要获取图中节点的邻居,这里图可以是有向图和无向图,对于有向图而言 1-2 ,1的邻居有2,2的邻居没1,对于无向图而言 1-2,1、2互为邻居,可以双向奔赴。
该算法主要分为随机游走和生成表示向量两个部分。首先利用随机游走算法(Random walk)从图中提取一些顶点序列;然后借助自然语言处理的思路,将生成的定点序列看作由单词组成的句子,所有的序列可以看作一个大的语料库(corpus),最后利用自然语言处理工具word2vec将每一个顶点表示为一个维度为d的向量。
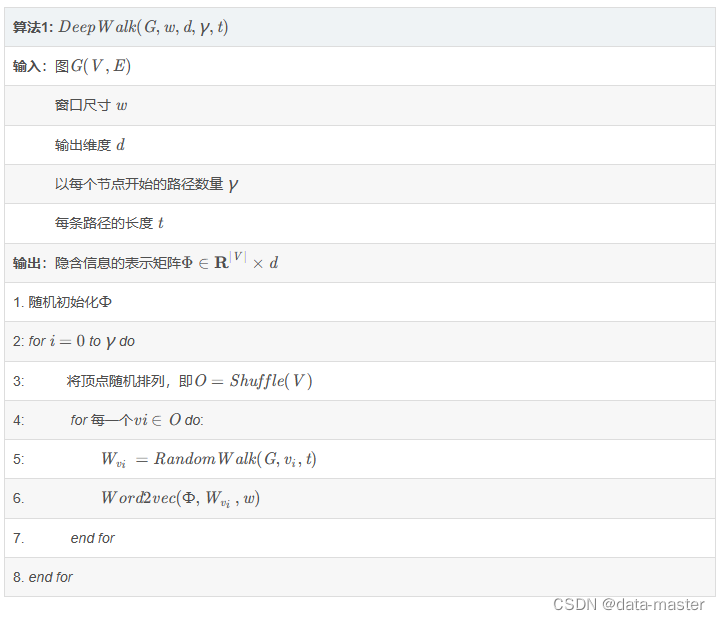
这么说有点抽象,看个例子:
参考: Deep walk模型 详细解释_weixin_46071260的博客-CSDN博客
数据集:wiki数据集(2405个网页,17981条网页间的关系)
输入样本:node1,node2,<edge_weight>
输出:每个node的embedding
本质上是用随机游走去捕获图中点的局部上下文信息,学到的表示向量反映的是该点在图中的局部结构,两个点在图中共有的邻近点(或者高阶邻近点)越多,则对应的两个向量之间的距离就越短。如上图。
2.3LINE
LINE也是一种基于邻域相似假设的方法,只不过与DeepWalk使用DFS构造邻域不同的是,LINE可以看作是一种使用BFS构造邻域的算法。此外,LINE还可以应用在带权图中(DeepWalk仅能用于无权图)。
LINE算法利用图中已存在的边构造目标函数,该目标函数显式描绘了一阶和二阶的邻近关系。然后通过优化方法去学习点的表达向量,其本质上是一种关于边的平滑,即很多很可能存在的边实际上不存在,需要模型去学习和预测出来。这点类似于推荐,任何推荐的算法本质上是对于user-item关系矩阵的平滑。
1阶相似度用于描述图中成对顶点之间的局部相似度,形式化描述为若,
之间存在直连边,则边权
即为两个顶点的相似度,若不存在直连边,则1阶相似度为0。 如下图,6和7之间存在直连边,且边权较大,则认为两者相似且1阶相似度较高,而5和6之间不存在直连边,则两者间1阶相似度为0。1st order 相似度只能用于无向图当中。
虽然5和6之间不存在直连边,但是他们有很多相同的邻居顶点(1,2,3,4),这其实也可以表明5和6是相似的,而2阶相似度就是用来描述这种关系的。 形式化定义为,令 =(
,...,
) 表示顶点
与所有其他顶点间的1阶相似度,则
与
的2阶相似度可以通过
和
的相似度表示。若
与
之间不存在相同的邻居顶点,则2阶相似度为0。
LINE能用于有向,无向图,带权重的和不带权重的。

如上图,6,7两个点是相似的,是因为直接相连,而5,6两个点也是相似的,是因为共享了很多邻近点。故本文显式考虑了一阶和二阶邻近关系。
【Graph Embedding】LINE:算法原理,实现和应用 - 知乎 (zhihu.com)
【Graph Embedding】LINE的原理、核心代码及其应用_graph embedding line_zhong_ddbb的博客-CSDN博客
2.4 node2vec
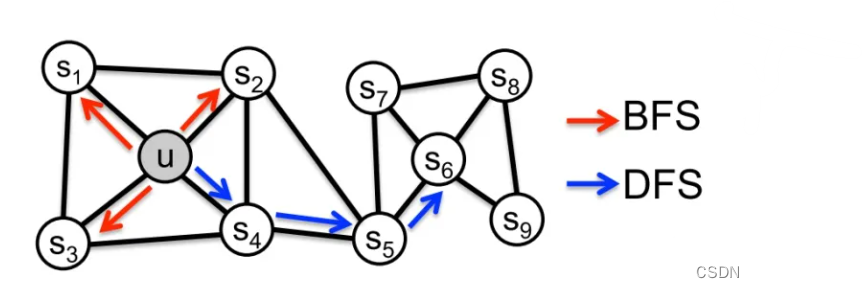
前面介绍过基于DFS邻域的DeepWalk和基于BFS邻域的LINE。node2vec是一种综合考虑DFS邻域和BFS邻域的graph embedding方法。简单来说,可以看作是deepwalk的一种扩展,是结合了DFS和BFS随机游走的deepwalk。
Node2vec是用来产生网络中节点向量的模型,输入是网络结构(可以无权重),输出是每个节点的向量
主要思想:直接导word2vec的包,通过特定的游走方式进行采样,对于每个点都会生成对应的序列。再将这些序列视为文本导入word2vec中的cbow或者skip-gram模型,即可得到每个节点的向量(对应word2vec中每个词的向量)
使用node2vec在wiki数据集上进行节点分类任务和可视化任务。 wiki数据集包含 2,405 个网页和17,981条网页之间的链接关系,以及每个网页的所属类别。 通过简单的超参搜索,这里使用p=0.25,q=4的设置。
本例中的训练,评测和可视化的完整代码在下面的git仓库中,shenweichen/GraphEmbedding: Implementation and experiments of graph embedding algorithms. (github.com)
Node2Vec可以看作DeepWalk的扩展,它学习嵌入的过程也可以分两步:
- 二阶随机游走(2ndorderrandomwalk)
- 使用skip-gram学习顶点嵌入
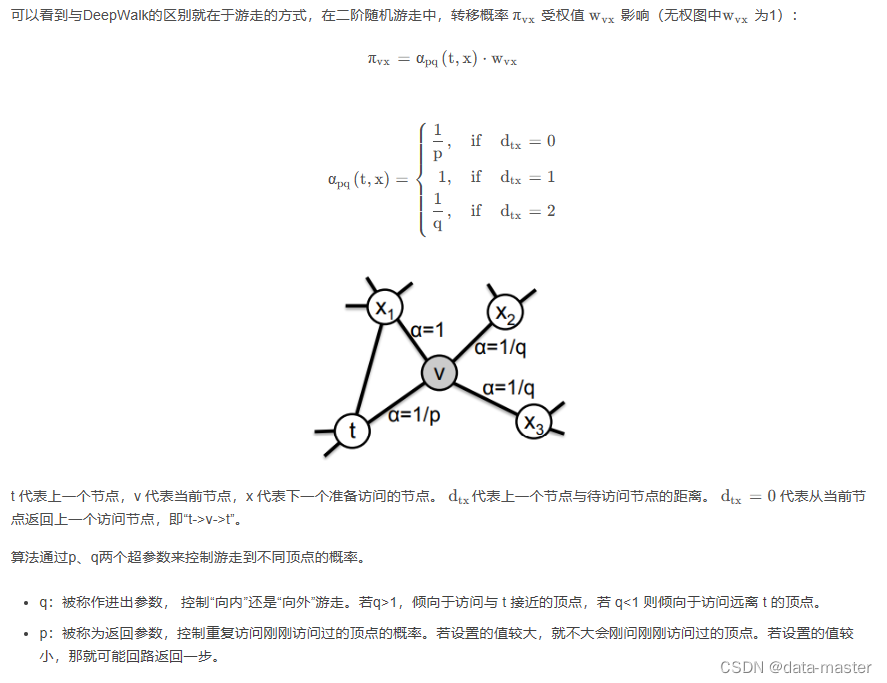
采样完顶点序列后,剩下的步骤就和deepwalk一样了,用word2vec去学习顶点的embedding向量。 值得注意的是node2vecWalk中不再是随机抽取邻接点,而是按概率抽取,node2vec采用了Alias算法进行顶点采样。
Node2vec原理剖析,代码实现_Jiede1的博客-CSDN博客
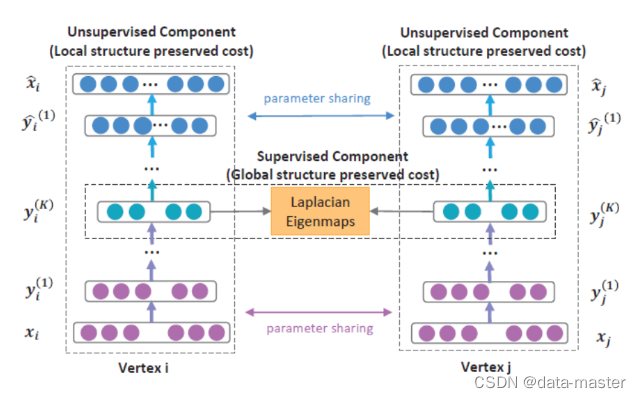
2.5 结构深度网络嵌入(SDNE)
结构深度网络嵌入(SDNE)与前两种方法没有任何共同之处,因为它不执行随机游走。SDNE在不同任务上的表现非常稳定。
它的设计使嵌入保持一阶和二阶接近。一阶近似是由边连接的节点之间的局部成对相似。它描述了本地网络结构的特征。如果网络中的两个节点与边缘相连,则它们是相似的。当一篇论文引用了另一篇论文,这意味着它们涉及了类似的主题。二阶邻近性表示节点邻近结构的相似性。它捕获了全局网络结构。如果两个节点共享许多邻居,它们往往是相似的。
-
一阶相似度指:具有边相连的节点的Embedding向量具有相似性。主要反映了 Graph 的局部特征
-
二阶相似性指:拥有共同邻居但不是直接相连的两个顶点之间应该具有相似性。反映了 Graph 的全局特征。
SDNE提出的自动编码器神经网络有两个部分-见下图。自动编码器(左、右网络)接受节点邻接向量,并经过训练来重建节点邻接。这些自动编码器被命名为原始自动编码器,它们学习二级邻近性。邻接向量(邻接矩阵中的一行)在表示连接到所选节点的位置上具有正值。
还有一个网络的监督部分——左翼和右翼之间的联系。它计算从左到右的嵌入距离,并将其包含在网络的共同损耗中。网络经过这样的训练,左、右自动编码器得到所有由输入边连接的节点对。距离部分的损失有助于保持一阶接近性。
网络的总损耗是由左、右自编码器的损耗和中间部分的损耗之和来计算的。
SDNE(Structural Deep Network Embedding )的原理,实现与应用_zhong_ddbb的博客-CSDN博客
[Graph Embedding] SDNE原理介绍及举例说明 - 知乎 (zhihu.com)
3.GAE
3.1自编码器(AE)
自编码器的思路来源于传统的PCA,其目的可以理解为非线性降维。我们知道在传统的PCA中,学习器学得一个子空间矩阵,将原始数据投影到一个低维子空间,从而达到数据降维的目的。自编码器则是利用神经网络将数据逐层降维,每层神经网络之间的激活函数就起到了将"线性"转化为"非线性"的作用。自编码器的网络结构可以是对称的也可以是非对称的。
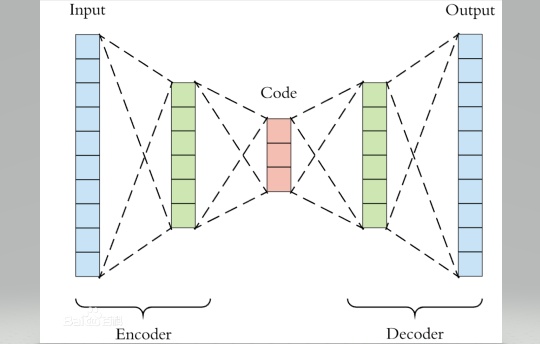
原理很简单:训练时,参数更新一直到左边的编码器编码降维成新的Code能够通过右边解码器完美的恢复到原来的输入即可。
3.2 图自编码器(GAE)
图自编码器和自编码器最大的区别有两点:一是图自编码器在encoder过程中使用了一个 n∗n的卷积核;另一个是图自编码器没有数据解码部分,转而代之的是图解码(graph decoder),具体实现是前后邻接矩阵的变化做loss。
图自编码器可以像自编码器那样用来生成隐向量,也可以用来做链路预测(应用于推荐的任务)。
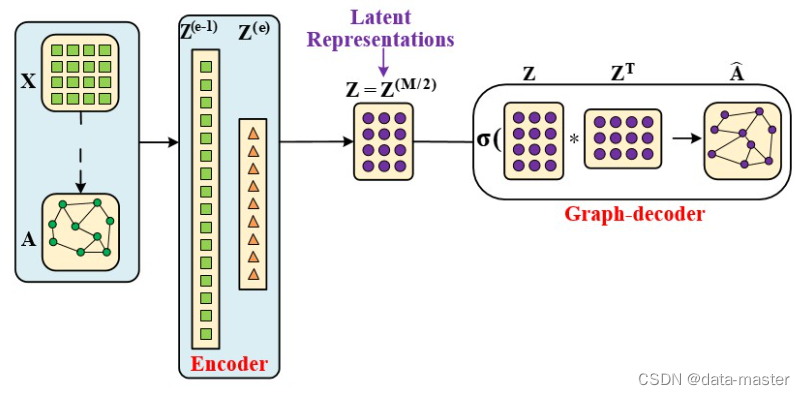
从上面的式子可以看出,编码器包含图卷积层 GCN, 没有了解过图卷积的读者可以移步至 教程(四). 我们的输入为 (A,X), 其中 A是图的邻接矩阵, X是输入的节点特征. 注意, 我们需要归一化邻接矩阵. 最后我们得到的输出 X¯ 是图的表征向量, 也就是图的嵌入。以将每个节点表示为一个d维特征向量,其中i表示节点的索引。这些特征向量通常被视为节点的属性或特征,可以是手动设计或通过自动学习提取。例如,对于社交网络图,节点特征向量可能包含节点的属性信息,如年龄、性别、职业等。对于生物学中的分子图,节点特征向量可能表示节点的化学属性,如原子类型、键类型等。这些节点特征向量是GAE中编码器和解码器的输入和输出,以实现对图的重构和生成。
PyG应用: 教程(六) 图自编码器与变分图自编码器 - 知乎 (zhihu.com)
4.GNN简单概述
非常详细的GNN:A Gentle Introduction to Graph Neural Networks (distill.pub)
十多年来,研究人员开发了一种称之为图神经网络(Graph Neural Networks,GNNs)的技术,旨在将如今在深度学习的诸多任务中摧枯拉朽的神经网络,应用到图结构之上,从而让神经网络捕捉到更错综复杂的交叉特征,以期待在一些任务上取得更佳的效果。鉴于操作图数据结构的复杂性,尽管已经发展了十几年,它在实际应用中却刚刚起步,即时是google也才开始研究将其被应用到药品研发、物理模拟、假新闻检测、交通预测和推荐系统等领域。
每个节点或者边都可以包含它的一些属性信息,比如如果一个节点表示一个人,那么就可以包含这个人的姓名、性别、身高、体重之类的..我们研究需要的信息。而这些信息,都可以用通用的向量的形式存入其中:

attributes embedding
还有别忘了一点,边是可以有方向的,按此我们还能分为有向图或是无向图。边的方向代表了信息的传递方向,例如a是b的微信好友,那b也是a的微信好友,好友关系自然是没方向的,而比如a是b的爹,那显然b就不是a的爹,此时叫爹的关系就是有有方向的。

Direct
图结构的构建是非常灵活的,可以根据个人的设计构建出各种不一样的图。而作为开发者显然要结合实际解决的问题来构建合适的图。
图在哪里:正如前面所提到的,图无处不在。你可能已经熟悉例如知识图谱、社交网络之类的图数据。当时显然,图是一种极其强大的通用数据表示,传统神经网络中用到的欧式空间的数据,同样可以用图来表示,例如可以将图像和文本建模为图结构数据。
图像表示为图:比如,我们可以将一张图片的每个像素作为图的节点,再将相邻的像素用边连接起来,就构造了一个该图像的图。

Image Graph
如上图展示了一个5*5的图片的邻接矩阵表示和图表示。
文本表示为图:我们将每个单词作为节点,并将每个节点连接到下一个节点,就得到了一个文本的图:

Text Graph
当然,在实践中我们并不会这样来编码文本和图像,因为所有的图和文本都是非常规则的结构,表示成图就多此一举了。我们再来看一些例子,这些数据的结构更加复杂,除了图之外很难用其他方式来表达。
分子图表示为图:分子是构成物质的基石,我们可以用节点来表示它的原子和电子,用边来表示共价键,这样便将一个分子表示成了一个图:

Molecules Graph
不同的图可以表示出不同的分子结构:

Molecules Graph2
社交网络表示为图:身处其中的人和事物之间会发生极其复杂的关系。这种关系的表示用普通的表格数据是很难表示的,而图却能很好的展现。下图是将莎士比亚歌剧《奥赛罗》中的任务关系表示成图:

Othello Graph
怎么样,如果没看过歌剧能推测出那些是主角吗?下面是将一个空手道竞标赛的对战关系构建为图:

karate Graph
类似的可以表示为图的数据还有很多很多,比如论文的引用之类统统都可以表示为图,下面是现实世界中不同规模的数据图表示的统计数据:

可见,各种各样规模的数据都可以轻松的用图来表示。
图解决什么问题:
在上面我们列举了这么多的图,那么我们该对这些图数据执行什么任务呢?
图上的预测任务一般分为三类:
- 图级别
- 节点级别
- 边级别
下面我们通过具体的示例来说明GNN怎么来解决上述的三个级别的预测问题。
图级任务:
在图级别的任务中,我们的目标是预测整个图的属性。例如我们通过分子图,来预测该分子的气味或是者它是否是与某些疾病有关的受体。
它的输入是完整的图:

input
输出是图的分类:

output
例如上图用于分类一个图是否有两个环。
这种任务,有点像是图像分类和文本分类,预测整个图像或是文本是哪一类。
节点级任务:
节点级任务一般就是预测每个节点的类型。
一个经典的例子就是Zach的空手道俱乐部。该数据集市一个单一的社交网络图,犹豫政治分歧,讲师Hi先生和管理员John之间不和导致空手道俱乐部分裂,其中的学员一部分效忠于Hi先生,一部分效忠于John。每个节点代表空手道联系着,边代表空手道之外这些成员的互动,预测问题就是判断这些节点是效忠于谁的。

边级任务:
边级任务其实就是预测每个边的属性.
在目标检测的语义分割任务中,我们也许不止要识别每个目标的类型,还需要预测各个目标之间的关系.我们可以将其描述为边级别的分类任务:给定表示图像中的对象的节点,我们希望预测哪些节点共享一条边,或者该边的值是多少。如果我们希望发现实体之间的连接,我们可以考虑图是完全连通的,并根据它们的预测值修剪边来得到一个稀疏图。

用图表示就是这样的过程:

在机器学习中使用图的挑战:
那么我们要如何使用神经网络来处理上述各种类型的任务呢?
首先要考虑的是如何将图结构数据适配到神经网络.
回想一下啊,传统的神经网络输入的往往是矩阵形式的数据,那么要如何把图作为输入呢?
图表示有四种类型的信息:节点(nodes),边(edges),全局上下文(global-context),联通性(connectivity).对于前三种信息,有一个非常简单的方案,比如将节点排序,然后每个节点表示为一个向量,所有节点就得到了一个节点的矩阵,同理,边和上下文也可以这么搞.
但是要标识连通性就没有这么简单了,也许你会想到用临街矩阵来表示,但是这样表示会有明显的缺陷,因为节点数的规模往往是巨大的,对于一个数百万节点的图,那将耗费大量的空间,而且得到的矩阵往往也十分的稀疏,可以说空间利用率会很低.
当然,你也许会想,可以用稀疏矩阵来存储,这样就只需要存储连通的情况,空间利用率将大大提升,但是我们还要考虑到一点,就是稀疏矩阵的高性能计算一直是个艰难的,尤其是在用到GPU的情况.
并且,使用邻接矩阵还有一个问题就是各种不同的邻接矩阵可以标识相同的连通性,而这些矩阵并不能保证在神经网络中取的相同的效果.比如,同样的连通性,通过调换列的顺序,就能得到不同的邻接矩阵:

不过,好在有一种更加优雅的方式来标识邻接关系,即邻接表.

如上图所示,我们还是用一个向量来标识nodes和edges和global,然后用一个adjacency list来记录连接关系,比如[1,0]标识节点1和节点2相连...这样就解决了上述邻接矩阵的各种问题了~
GNN是怎么炼成的:
现在,我们成功的将图结构成功表示成了置换不变的矩阵格式,终于可以使用图形神经网络(GNN)来做图形预测任务了。
GNN是对保持图对称性(置换不变性)的图的所有属性(节点、边、全局上下文)的可优化变换。
我们将使用Gilmer等人提出的“消息传递神经网络”框架构建GNN,并使用Battaglia等人介绍的图网络网络架构示意图。GNNS采用“图输入,图输出”架构,这意味着这些模型类型接受图作为输入,其中包含节点,边和全局上下文的信息,并逐步地转换这些图嵌入,而不会更改输入的连接图结构。
最简单的GNN:
我们使用最开始提到的那个图来构建一个最简单的GNN,输入的图是相应节点,边,全局信息的向量,我们针对每个向量使用一个MLP层来作变换,于是得到一个新的图。

针对上述构建的最简单的GNN,我们如何在上面描述的任何任务中进行预测呢?这里我们仅仅考虑二进制分类的情况,但这个框架可以很容易地扩展到多类或回归的情况。
如果是对节点分类,我们只要在最后一层接一个线性类器就可以了:

但是上面的预测过程有点过于简单了,完全没有用到图的结构信息,我们在此基础上增加一个pooling操作,以增加它的边缘信息:

具体操作是把待预测节点的邻居节点以及全局的信息进行聚合再做预测,即将这些embedding向量加到一起得到一个新的向量,再输入到最后的线性分类器.
同理,如果我们只有节点相应边的信息的话,也可以用类似的方式pooling,然后得到节点的向量表示再输入分类器:

反之,如果我们只有节点的信息,那么也可以用边所连接的两个节点来pooling出边的向量,然后将器输入到分类器预测边的类型:

当然,如果我们只有节点的信息而要预测全图的类型,我们同样可以将节点信息和全局信息全部聚合之后,再将聚合信息输入到分类器做预测:

显然,不管是哪种任务,整个GNN的推理过程都是一样的,可以表示为这样一个端到端的过程:

不过,显而易见的,这个简单的GNN在分类前只是对每个向量进行了一个变换,而没有用到图结构的任何信息,虽然在最后做预测的时候做了一些pooling的聚合,但也始终没有用到adjacency的信息,因此这个GNN的作用相当有限,但是它为我们提供了一个图结构层变换和堆叠的基本思路.
在图的各部分进行信息传递
针对上面最简单GNN的不足,我们可以在其中根据连通性增加更加复杂的变换从而引入整个图结构的信息,我们将这个过程称之为信息传递.
信息传递包含三个步骤:
- 取出每个节点聚合其邻居节点的信息
- 通过聚合函数转换以上所有信息
- 通过一个更新函数(通常是一个学习过的神经网络)更新节点信息

这个过程有点类似于卷积操作,每个节点汇聚了其邻居的节点,经过多个层的变换,它将涵盖全图的信息.
于是我们可以将这个节点信息传递应用到上述的图变换过程中:

然后,我们发现它并没用用上边的信息,于是可以把边信息也加上,变成这样:

另外,我们可以发现聚合顺序不同,结果就会不同:

那么按照哪个顺序呢?这并没有明确的答案,就靠开发者来决策了,或者使用一种交替聚合的策略,这样就跟顺序无关了:

既然把边的信息加上了,那怎么可以漏掉全局信息呢,于是完整的信息传递就可以表示成这样:

在这个视图中,所有图属性都学习了表示,因此我们可以在pooling过程中通过调节我们感兴趣的属性的信息相对于其余属性来利用它们。例如,对于一个节点,我们可以考虑来自相邻节点、连接边和全局信息的信息。为了在所有这些可能的信息源上调节新节点嵌入,我们可以简单地将它们连接起来。此外,我们还可以通过线性映射将它们映射到相同的空间并累加它们或应用特征调节层,这可以被认为是一种特征化注意力机制。

5.GCN(图卷积神经网络)
GCN,图卷积神经网络,实际上跟CNN的作用一样,就是一个特征提取器,只不过它的对象是图数据。GCN精妙地设计了一种从图数据中提取特征的方法,从而让我们可以使用这些特征去对图数据进行节点分类(node classification)、图分类(graph classification)、边预测(link prediction),还可以顺便得到图的嵌入表示(graph embedding),可见用途广泛。因此现在人们脑洞大开,让GCN到各个领域中发光发热。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









