







from:https://blog.csdn.net/on2way/article/details/72773771
之前
GAN网络是近两年深度学习领域的新秀,火的不行,本文旨在浅显理解传统GAN,分享学习心得。现有GAN网络大多数代码实现使用python、torch等语言,这里,后面用matlab搭建一个简单的GAN网络,便于理解GAN原理。
GAN的鼻祖之作是2014年NIPS一篇文章:Generative Adversarial Net,可以细细品味。
开始
我们知道GAN的思想是是一种二人零和博弈思想(two-player game),博弈双方的利益之和是一个常数,比如两个人掰手腕,假设总的空间是一定的,你的力气大一点,那你就得到的空间多一点,相应的我的空间就少一点,相反我力气大我就得到的多一点,但有一点是确定的就是,我两的总空间是一定的,这就是二人博弈,但是呢总利益是一定的。
引申到GAN里面就是可以看成,GAN中有两个这样的博弈者,一个人名字是生成模型(G),另一个人名字是判别模型(D)。他们各自有各自的功能。
相同点是:
- 这两个模型都可以看成是一个黑匣子,接受输入然后有一个输出,类似一个函数,一个输入输出映射。
不同点是:
- 生成模型功能:比作是一个样本生成器,输入一个噪声/样本,然后把它包装成一个逼真的样本,也就是输出。
- 判别模型:比作一个二分类器(如同0-1分类器),来判断输入的样本是真是假。(就是输出值大于0.5还是小于0.5);
直接上一张个人觉得解释的好的图说明: 
在之前,我们首先明白在使用GAN的时候的2个问题
- 我们有什么?
比如上面的这个图,我们有的只是真实采集而来的人脸样本数据集,仅此而已,而且很关键的一点是我们连人脸数据集的类标签都没有,也就是我们不知道那个人脸对应的是谁。 - 我们要得到什么
至于要得到什么,不同的任务得到的东西不一样,我们只说最原始的GAN目的,那就是我们想通过输入一个噪声,模拟得到一个人脸图像,这个图像可以非常逼真以至于以假乱真。
好了再来理解下GAN的两个模型要做什么。首先判别模型,就是图中右半部分的网络,直观来看就是一个简单的神经网络结构,输入就是一副图像,输出就是一个概率值,用于判断真假使用(概率值大于0.5那就是真,小于0.5那就是假),真假也不过是人们定义的概率而已。其次是生成模型,生成模型要做什么呢,同样也可以看成是一个神经网络模型,输入是一组随机数Z,输出是一个图像,不再是一个数值而已。从图中可以看到,会存在两个数据集,一个是真实数据集,这好说,另一个是假的数据集,那这个数据集就是有生成网络造出来的数据集。好了根据这个图我们再来理解一下GAN的目标是要干什么:
- 判别网络的目的:就是能判别出来属于的一张图它是来自真实样本集还是假样本集。假如输入的是真样本,网络输出就接近1,输入的是假样本,网络输出接近0,那么很完美,达到了很好判别的目的。
- 生成网络的目的:生成网络是造样本的,它的目的就是使得自己造样本的能力尽可能强,强到什么程度呢,你判别网络没法判断我是真样本还是假样本。
有了这个理解我们再来看看为什么叫做对抗网络了。判别网络说,我很强,来一个样本我就知道它是来自真样本集还是假样本集。生成网络就不服了,说我也很强,我生成一个假样本,虽然我生成网络知道是假的,但是你判别网络不知道呀,我包装的非常逼真,以至于判别网络无法判断真假,那么用输出数值来解释就是,生成网络生成的假样本进去了判别网络以后,判别网络给出的结果是一个接近0.5的值,极限情况就是0.5,也就是说判别不出来了,这就是纳什平衡了。
由这个分析可以发现,生成网络与判别网络的目的正好是相反的,一个说我能判别的好,一个说我让你判别不好。所以叫做对抗,叫做博弈。那么最后的结果到底是谁赢呢?这就要归结到设计者,也就是我们希望谁赢了。作为设计者的我们,我们的目的是要得到以假乱真的样本,那么很自然的我们希望生成样本赢了,也就是希望生成样本很真,判别网络能力不足以区分真假样本位置。
再理解
知道了GAN大概的目的与设计思路,那么一个很自然的问题来了就是我们该如何用数学方法解决这么一个对抗问题。这就涉及到如何训练这样一个生成对抗网络模型了,还是先上一个图,用图来解释最直接: 
需要注意的是生成模型与对抗模型可以说是完全独立的两个模型,好比就是完全独立的两个神经网络模型,他们之间没有什么联系。
好了那么训练这样的两个模型的大方法就是:单独交替迭代训练。
什么意思?因为是2个网络,不好一起训练,所以才去交替迭代训练,我们一一来看。
假设现在生成网络模型已经有了(当然可能不是最好的生成网络),那么给一堆随机数组,就会得到一堆假的样本集(因为不是最终的生成模型,那么现在生成网络可能就处于劣势,导致生成的样本就不咋地,可能很容易就被判别网络判别出来了说这货是假冒的),但是先不管这个,假设我们现在有了这样的假样本集,真样本集一直都有,现在我们人为的定义真假样本集的标签,因为我们希望真样本集的输出尽可能为1,假样本集为0,很明显这里我们就已经默认真样本集所有的类标签都为1,而假样本集的所有类标签都为0. 有人会说,在真样本集里面的人脸中,可能张三人脸和李四人脸不一样呀,对于这个问题我们需要理解的是,我们现在的任务是什么,我们是想分样本真假,而不是分真样本中那个是张三label、那个是李四label。况且我们也知道,原始真样本的label我们是不知道的。回过头来,我们现在有了真样本集以及它们的label(都是1)、假样本集以及它们的label(都是0),这样单就判别网络来说,此时问题就变成了一个再简单不过的有监督的二分类问题了,直接送到神经网络模型中训练就完事了。假设训练完了,下面我们来看生成网络。
对于生成网络,想想我们的目的,是生成尽可能逼真的样本。那么原始的生成网络生成的样本你怎么知道它真不真呢?就是送到判别网络中,所以在训练生成网络的时候,我们需要联合判别网络一起才能达到训练的目的。什么意思?就是如果我们单单只用生成网络,那么想想我们怎么去训练?误差来源在哪里?细想一下没有,但是如果我们把刚才的判别网络串接在生成网络的后面,这样我们就知道真假了,也就有了误差了。所以对于生成网络的训练其实是对生成-判别网络串接的训练,就像图中显示的那样。好了那么现在来分析一下样本,原始的噪声数组Z我们有,也就是生成了假样本我们有,此时很关键的一点来了,我们要把这些假样本的标签都设置为1,也就是认为这些假样本在生成网络训练的时候是真样本。那么为什么要这样呢?我们想想,是不是这样才能起到迷惑判别器的目的,也才能使得生成的假样本逐渐逼近为正样本。好了,重新顺一下思路,现在对于生成网络的训练,我们有了样本集(只有假样本集,没有真样本集),有了对应的label(全为1),是不是就可以训练了?有人会问,这样只有一类样本,训练啥呀?谁说一类样本就不能训练了?只要有误差就行。还有人说,你这样一训练,判别网络的网络参数不是也跟着变吗?没错,这很关键,所以在训练这个串接的网络的时候,一个很重要的操作就是不要判别网络的参数发生变化,也就是不让它参数发生更新,只是把误差一直传,传到生成网络那块后更新生成网络的参数。这样就完成了生成网络的训练了。
在完成生成网络训练好,那么我们是不是可以根据目前新的生成网络再对先前的那些噪声Z生成新的假样本了,没错,并且训练后的假样本应该是更真了才对。然后又有了新的真假样本集(其实是新的假样本集),这样又可以重复上述过程了。我们把这个过程称作为单独交替训练。我们可以实现定义一个迭代次数,交替迭代到一定次数后停止即可。这个时候我们再去看一看噪声Z生成的假样本会发现,原来它已经很真了。
看完了这个过程是不是感觉GAN的设计真的很巧妙,个人觉得最值得称赞的地方可能在于这种假样本在训练过程中的真假变换,这也是博弈得以进行的关键之处。
进一步
文字的描述相信已经让大多数的人知道了这个过程,下面我们来看看原文中几个重要的数学公式描述,首先我们直接上原始论文中的目标公式吧:
minGmaxDV(D,G)=Ex∼pdata(x)[log(D(x))]+Ez∼pz(z)[log(1−D(G(z)))]minGmaxDV(D,G)=Ex∼pdata(x)[log(D(x))]+Ez∼pz(z)[log(1−D(G(z)))]
上述这个公式说白了就是一个最大最小优化问题,其实对应的也就是上述的两个优化过程。有人说如果不看别的,能达看到这个公式就拍案叫绝的地步,那就是机器学习的顶级专家,哈哈,真是前路漫漫。同时也说明这个简单的公式意义重大。
这个公式既然是最大最小的优化,那就不是一步完成的,其实对比我们的分析过程也是这样的,这里现优化D,然后在取优化G,本质上是两个优化问题,把拆解就如同下面两个公式:
优化D:
maxDV(D,G)=Ex∼pdata(x)[log(D(x))]+Ez∼pz(z)[log(1−D(G(z)))]maxDV(D,G)=Ex∼pdata(x)[log(D(x))]+Ez∼pz(z)[log(1−D(G(z)))]
优化G:
minGV(D,G)=Ez∼pz(z)[log(1−D(G(z)))]minGV(D,G)=Ez∼pz(z)[log(1−D(G(z)))]
可以看到,优化D的时候,也就是判别网络,其实没有生成网络什么事,后面的G(z)这里就相当于已经得到的假样本。优化D的公式的第一项,使的真样本x输入的时候,得到的结果越大越好,可以理解,因为需要真样本的预测结果越接近于1越好嘛。对于假样本,需要优化是的其结果越小越好,也就是D(G(z))越小越好,因为它的标签为0。但是呢第一项是越大,第二项是越小,这不矛盾了,所以呢把第二项改成1-D(G(z)),这样就是越大越好,两者合起来就是越大越好。 那么同样在优化G的时候,这个时候没有真样本什么事,所以把第一项直接却掉了。这个时候只有假样本,但是我们说这个时候是希望假样本的标签是1的,所以是D(G(z))越大越好,但是呢为了统一成1-D(G(z))的形式,那么只能是最小化1-D(G(z)),本质上没有区别,只是为了形式的统一。之后这两个优化模型可以合并起来写,就变成了最开始的那个最大最小目标函数了。
所以回过头来我们来看这个最大最小目标函数,里面包含了判别模型的优化,包含了生成模型的以假乱真的优化,完美的阐释了这样一个优美的理论。
再进一步
有人说GAN强大之处在于可以自动的学习原始真实样本集的数据分布,不管这个分布多么的复杂,只要训练的足够好就可以学出来。针对这一点,感觉有必要好好理解一下为什么别人会这么说。
我们知道,传统的机器学习方法,我们一般都会定义一个什么模型让数据去学习。比如说假设我们知道原始数据属于高斯分布呀,只是不知道高斯分布的参数,这个时候我们定义高斯分布,然后利用数据去学习高斯分布的参数得到我们最终的模型。再比如说我们定义一个分类器,比如SVM,然后强行让数据进行东变西变,进行各种高维映射,最后可以变成一个简单的分布,SVM可以很轻易的进行二分类分开,其实SVM已经放松了这种映射关系了,但是也是给了一个模型,这个模型就是核映射(什么径向基函数等等),说白了其实也好像是你事先知道让数据该怎么映射一样,只是核映射的参数可以学习罢了。所有的这些方法都在直接或者间接的告诉数据你该怎么映射一样,只是不同的映射方法能力不一样。那么我们再来看看GAN,生成模型最后可以通过噪声生成一个完整的真实数据(比如人脸),说明生成模型已经掌握了从随机噪声到人脸数据的分布规律了,有了这个规律,想生成人脸还不容易。然而这个规律我们开始知道吗?显然不知道,如果让你说从随机噪声到人脸应该服从什么分布,你不可能知道。这是一层层映射之后组合起来的非常复杂的分布映射规律。然而GAN的机制可以学习到,也就是说GAN学习到了真实样本集的数据分布。
再拿原论文中的一张图来解释: 
这张图表明的是GAN的生成网络如何一步步从均匀分布学习到正太分布的。原始数据x服从正太分布,这个过程你也没告诉生成网络说你得用正太分布来学习,但是生成网络学习到了。假设你改一下x的分布,不管什么分布,生成网络可能也能学到。这就是GAN可以自动学习真实数据的分布的强大之处。
还有人说GAN强大之处在于可以自动的定义潜在损失函数。 什么意思呢,这应该说的是判别网络可以自动学习到一个好的判别方法,其实就是等效的理解为可以学习到好的损失函数,来比较好或者不好的判别出来结果。虽然大的loss函数还是我们人为定义的,基本上对于多数GAN也都这么定义就可以了,但是判别网络潜在学习到的损失函数隐藏在网络之中,不同的问题这个函数就不一样,所以说可以自动学习这个潜在的损失函数。
开始做小实验
本节主要实验一下如何通过随机数组生成mnist图像。mnist手写体数据库应该都熟悉的。这里简单的使用matlab来实现,方便看到整个实现过程。这里用到了一个工具箱
DeepLearnToolbox,关于该工具箱的一些其他使用说明
网络结构很简单,就定义成下面这样子: 
将上述工具箱添加到路径,然后运行下面代码:
clc
clear
%% 构造真实训练样本 60000个样本 1*784维(28*28展开)
load mnist_uint8;
train_x = double(train_x(1:60000,:)) / 255;
% 真实样本认为为标签 [1 0]; 生成样本为[0 1];
train_y = double(ones(size(train_x,1),1));
% normalize
train_x = mapminmax(train_x, 0, 1);
rand('state',0)
%% 构造模拟训练样本 60000个样本 1*100维
test_x = normrnd(0,1,[60000,100]); % 0-255的整数
test_x = mapminmax(test_x, 0, 1);
test_y = double(zeros(size(test_x,1),1));
test_y_rel = double(ones(size(test_x,1),1));
%%
nn_G_t = nnsetup([100 784]);
nn_G_t.activation_function = 'sigm';
nn_G_t.output = 'sigm';
nn_D = nnsetup([784 100 1]);
nn_D.weightPenaltyL2 = 1e-4; % L2 weight decay
nn_D.dropoutFraction = 0.5; % Dropout fraction
nn_D.learningRate = 0.01; % Sigm require a lower learning rate
nn_D.activation_function = 'sigm';
nn_D.output = 'sigm';
% nn_D.weightPenaltyL2 = 1e-4; % L2 weight decay
nn_G = nnsetup([100 784 100 1]);
nn_G.weightPenaltyL2 = 1e-4; % L2 weight decay
nn_G.dropoutFraction = 0.5; % Dropout fraction
nn_G.learningRate = 0.01; % Sigm require a lower learning rate
nn_G.activation_function = 'sigm';
nn_G.output = 'sigm';
% nn_G.weightPenaltyL2 = 1e-4; % L2 weight decay
opts.numepochs = 1; % Number of full sweeps through data
opts.batchsize = 100; % Take a mean gradient step over this many samples
%%
num = 1000;
tic
for each = 1:1500
%----------计算G的输出:假样本-------------------
for i = 1:length(nn_G_t.W) %共享网络参数
nn_G_t.W{i} = nn_G.W{i};
end
G_output = nn_G_out(nn_G_t, test_x);
%-----------训练D------------------------------
index = randperm(60000);
train_data_D = [train_x(index(1:num),:);G_output(index(1:num),:)];
train_y_D = [train_y(index(1:num),:);test_y(index(1:num),:)];
nn_D = nntrain(nn_D, train_data_D, train_y_D, opts);%训练D
%-----------训练G-------------------------------
for i = 1:length(nn_D.W) %共享训练的D的网络参数
nn_G.W{length(nn_G.W)-i+1} = nn_D.W{length(nn_D.W)-i+1};
end
%训练G:此时假样本标签为1,认为是真样本
nn_G = nntrain(nn_G, test_x(index(1:num),:), test_y_rel(index(1:num),:), opts);
end
toc
for i = 1:length(nn_G_t.W)
nn_G_t.W{i} = nn_G.W{i};
end
fin_output = nn_G_out(nn_G_t, test_x);
函数nn_G_out为:
function output = nn_G_out(nn, x)
nn.testing = 1;
nn = nnff(nn, x, zeros(size(x,1), nn.size(end)));
nn.testing = 0;
output = nn.a{end};
end
看一下这个及其简单的函数,其实最值得注意的就是中间那个交替训练的过程,这里我分了三步列出来:
- 重新计算假样本(假样本每次是需要更新的,产生越来越像的样本)
- 训练D网络,一个二分类的神经网络;
- 训练G网络,一个串联起来的长网络,也是一个二分类的神经网络(不过只有假样本来训练),同时D部分参数在下一次的时候不能变了。
就这样调一调参数,最终输出在fin_output里面,多运行几次显示不同运行次数下的结果:

可以看到的是结果还是有点像模像样的。
实验总结
运行上述简单的网络我发现几个问题:
- 网络存在着不收敛问题;网络不稳定;网络难训练;读过原论文其实作者也提到过这些问题,包括GAN刚出来的时候,很多人也在致力于解决这些问题,当你实验自己碰到的时候,还是很有意思的。那么这些问题怎么体现的呢,举个例子,可能某一次你会发现训练的误差很小,在下一代训练时,马上又出现极限性的上升的很厉害,过几代又发现训练误差很小,震荡太严重。
- 其次网络需要调才能出像样的结果。交替迭代次数的不同结果也不一样。比如每一代训练中,D网络训练2回,G网络训练一回,结果就不一样。
- 这是简单的无条件GAN,所以每一代训练完后,只能出现一个结果,那就是0-9中的某一个数。要想在一代训练中出现好几种结果,就需要使用到条件GAN了。
最后
现在的GAN已经到了五花八门的时候了,各种GAN应用也很多,理解底层原理再慢慢往上层扩展。GAN还是一个很厉害的东西,它使得现有问题从有监督学习慢慢过渡到无监督学习,而无监督学习才是自然界中普遍存在的,因为很多时候没有办法拿到监督信息的。要不Yann Lecun赞叹GAN是机器学习近十年来最有意思的想法。
福利
该节部分出了个视频版的讲解,详情请点击:http://www.mooc.ai/open/course/301
欢迎关注【微信公众号:AInewworld】了解更多。
from: https://deephunt.in/the-gan-zoo-79597dc8c347
Every week, new papers on Generative Adversarial Networks (GAN) are coming out and it’s hard to keep track of them all, not to mention the incredibly creative ways in which researchers are naming these GANs! You can read more about GANs in this Generative Models post by OpenAI or this overview tutorial in KDNuggets.
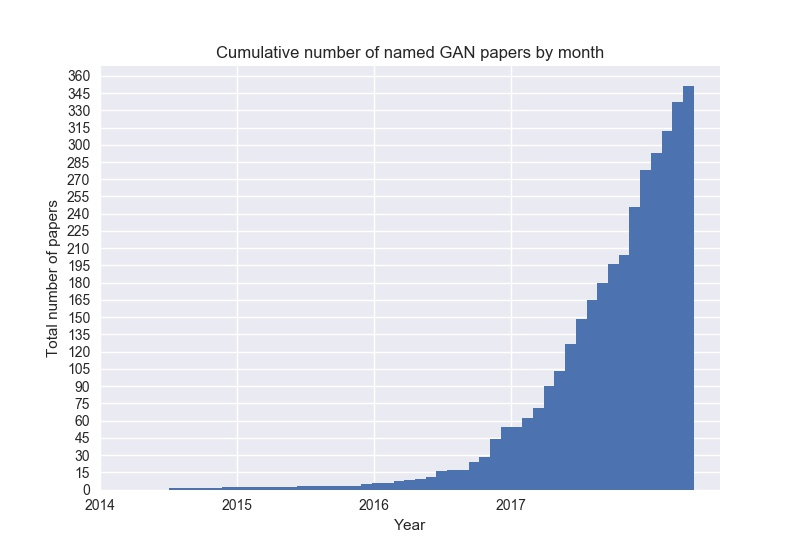
Explosive growth — All the named GAN variants cumulatively since 2014. Credit: Bruno Gavranović
So, here’s the current and frequently updated list, from what started as a fun activity compiling all named GANs in this format: Name and Source Paperlinked to Arxiv. Last updated on Feb 23, 2018.
- 3D-ED-GAN — Shape Inpainting using 3D Generative Adversarial Network and Recurrent Convolutional Networks
- 3D-GAN — Learning a Probabilistic Latent Space of Object Shapes via 3D Generative-Adversarial Modeling (github)
- 3D-IWGAN — Improved Adversarial Systems for 3D Object Generation and Reconstruction (github)
- 3D-PhysNet — 3D-PhysNet: Learning the Intuitive Physics of Non-Rigid Object Deformations
- 3D-RecGAN — 3D Object Reconstruction from a Single Depth View with Adversarial Learning (github)
- ABC-GAN — ABC-GAN: Adaptive Blur and Control for improved training stability of Generative Adversarial Networks(github)
- ABC-GAN — GANs for LIFE: Generative Adversarial Networks for Likelihood Free Inference
- AC-GAN — Conditional Image Synthesis With Auxiliary Classifier GANs
- acGAN — Face Aging With Conditional Generative Adversarial Networks
- ACGAN — Coverless Information Hiding Based on Generative adversarial networks
- ACtuAL — ACtuAL: Actor-Critic Under Adversarial Learning
- AdaGAN — AdaGAN: Boosting Generative Models
- Adaptive GAN — Customizing an Adversarial Example Generator with Class-Conditional GANs
- AdvEntuRe — AdvEntuRe: Adversarial Training for Textual Entailment with Knowledge-Guided Examples
- AdvGAN — Generating adversarial examples with adversarial networks
- AE-GAN — AE-GAN: adversarial eliminating with GAN
- AEGAN — Learning Inverse Mapping by Autoencoder based Generative Adversarial Nets
- AF-DCGAN — AF-DCGAN: Amplitude Feature Deep Convolutional GAN for Fingerprint Construction in Indoor Localization System
- AffGAN — Amortised MAP Inference for Image Super-resolution
- AL-CGAN — Learning to Generate Images of Outdoor Scenes from Attributes and Semantic Layouts
- ALI — Adversarially Learned Inference (github)
- AlignGAN — AlignGAN: Learning to Align Cross-Domain Images with Conditional Generative Adversarial Networks
- AlphaGAN — AlphaGAN: Generative adversarial networks for natural image matting
- AM-GAN — Activation Maximization Generative Adversarial Nets
- AmbientGAN — AmbientGAN: Generative models from lossy measurements (github)
- AMC-GAN — Video Prediction with Appearance and Motion Conditions
- AnoGAN — Unsupervised Anomaly Detection with Generative Adversarial Networks to Guide Marker Discovery
- APD — Adversarial Distillation of Bayesian Neural Network Posteriors
- APE-GAN — APE-GAN: Adversarial Perturbation Elimination with GAN
- ARAE — Adversarially Regularized Autoencoders for Generating Discrete Structures (github)
- ARDA — Adversarial Representation Learning for Domain Adaptation
- ARIGAN — ARIGAN: Synthetic Arabidopsis Plants using Generative Adversarial Network
- ArtGAN — ArtGAN: Artwork Synthesis with Conditional Categorial GANs
- ASDL-GAN — Automatic Steganographic Distortion Learning Using a Generative Adversarial Network
- ATA-GAN — Attention-Aware Generative Adversarial Networks (ATA-GANs)
- Attention-GAN — Attention-GAN for Object Transfiguration in Wild Images
- AttGAN — Arbitrary Facial Attribute Editing: Only Change What You Want(github)
- AttnGAN — AttnGAN: Fine-Grained Text to Image Generation with Attentional Generative Adversarial Networks (github)
- AVID — AVID: Adversarial Visual Irregularity Detection
- B-DCGAN — B-DCGAN:Evaluation of Binarized DCGAN for FPGA
- b-GAN — Generative Adversarial Nets from a Density Ratio Estimation Perspective
- BAGAN — BAGAN: Data Augmentation with Balancing GAN
- Bayesian GAN — Deep and Hierarchical Implicit Models
- Bayesian GAN — Bayesian GAN (github)
- BCGAN — Bayesian Conditional Generative Adverserial Networks
- BCGAN — Bidirectional Conditional Generative Adversarial networks
- BEAM — Boltzmann Encoded Adversarial Machines
- BEGAN — BEGAN: Boundary Equilibrium Generative Adversarial Networks
- BGAN — Binary Generative Adversarial Networks for Image Retrieval(github)
- BicycleGAN — Toward Multimodal Image-to-Image Translation (github)
- BiGAN — Adversarial Feature Learning
- BinGAN — BinGAN: Learning Compact Binary Descriptors with a Regularized GAN
- BourGAN — BourGAN: Generative Networks with Metric Embeddings
- BranchGAN — Branched Generative Adversarial Networks for Multi-Scale Image Manifold Learning
- BRE — Improving GAN Training via Binarized Representation Entropy (BRE) Regularization (github)
- BS-GAN — Boundary-Seeking Generative Adversarial Networks
- BWGAN — Banach Wasserstein GAN
- C-GAN — Face Aging with Contextual Generative Adversarial Nets
- C-RNN-GAN — C-RNN-GAN: Continuous recurrent neural networks with adversarial training (github)
- CA-GAN — Composition-aided Sketch-realistic Portrait Generation
- CaloGAN — CaloGAN: Simulating 3D High Energy Particle Showers in Multi-Layer Electromagnetic Calorimeters with Generative Adversarial Networks (github)
- CAN — CAN: Creative Adversarial Networks, Generating Art by Learning About Styles and Deviating from Style Norms
- CapsGAN — CapsGAN: Using Dynamic Routing for Generative Adversarial Networks
- CapsuleGAN — CapsuleGAN: Generative Adversarial Capsule Network
- CatGAN — Unsupervised and Semi-supervised Learning with Categorical Generative Adversarial Networks
- CatGAN — CatGAN: Coupled Adversarial Transfer for Domain Generation
- CausalGAN — CausalGAN: Learning Causal Implicit Generative Models with Adversarial Training
- CC-GAN — Semi-Supervised Learning with Context-Conditional Generative Adversarial Networks (github)
- cd-GAN — Conditional Image-to-Image Translation
- CDcGAN — Simultaneously Color-Depth Super-Resolution with Conditional Generative Adversarial Network
- CE-GAN — Deep Learning for Imbalance Data Classification using Class Expert Generative Adversarial Network
- CFG-GAN — Composite Functional Gradient Learning of Generative Adversarial Models
- CGAN — Conditional Generative Adversarial Nets
- CGAN — Controllable Generative Adversarial Network
- Chekhov GAN — An Online Learning Approach to Generative Adversarial Networks
- ciGAN — Conditional Infilling GANs for Data Augmentation in Mammogram Classification
- CipherGAN — Unsupervised Cipher Cracking Using Discrete GANs
- CM-GAN — CM-GANs: Cross-modal Generative Adversarial Networks for Common Representation Learning
- CoAtt-GAN — Are You Talking to Me? Reasoned Visual Dialog Generation through Adversarial Learning
- CoGAN — Coupled Generative Adversarial Networks
- ComboGAN — ComboGAN: Unrestrained Scalability for Image Domain Translation (github)
- ConceptGAN — Learning Compositional Visual Concepts with Mutual Consistency
- Conditional cycleGAN — Conditional CycleGAN for Attribute Guided Face Image Generation
- constrast-GAN — Generative Semantic Manipulation with Contrasting GAN
- Context-RNN-GAN — Contextual RNN-GANs for Abstract Reasoning Diagram Generation
- CorrGAN — Correlated discrete data generation using adversarial training
- Coulomb GAN — Coulomb GANs: Provably Optimal Nash Equilibria via Potential Fields
- Cover-GAN — Generative Steganography with Kerckhoffs’ Principle based on Generative Adversarial Networks
- cowboy — Defending Against Adversarial Attacks by Leveraging an Entire GAN
- CR-GAN — CR-GAN: Learning Complete Representations for Multi-view Generation
- Cramèr GAN — The Cramer Distance as a Solution to Biased Wasserstein Gradients
- Cross-GAN — Crossing Generative Adversarial Networks for Cross-View Person Re-identification
- crVAE-GAN — Channel-Recurrent Variational Autoencoders
- CS-GAN — Improving Neural Machine Translation with Conditional Sequence Generative Adversarial Nets
- CSG — Speech-Driven Expressive Talking Lips with Conditional Sequential Generative Adversarial Networks
- CT-GAN — CT-GAN: Conditional Transformation Generative Adversarial Network for Image Attribute Modification
- CVAE-GAN — CVAE-GAN: Fine-Grained Image Generation through Asymmetric Training
- CycleGAN — Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks (github)
- D-GAN — Differential Generative Adversarial Networks: Synthesizing Non-linear Facial Variations with Limited Number of Training Data
- D-WCGAN — I-vector Transformation Using Conditional Generative Adversarial Networks for Short Utterance Speaker Verification
- D2GAN — Dual Discriminator Generative Adversarial Nets
- D2IA-GAN — Tagging like Humans: Diverse and Distinct Image Annotation
- DA-GAN — DA-GAN: Instance-level Image Translation by Deep Attention Generative Adversarial Networks (with Supplementary Materials)
- DAGAN — Data Augmentation Generative Adversarial Networks
- DAN — Distributional Adversarial Networks
- DBLRGAN — Adversarial Spatio-Temporal Learning for Video Deblurring
- DCGAN — Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks (github)
- DE-GAN — Generative Adversarial Networks with Decoder-Encoder Output Noise
- DeblurGAN — DeblurGAN: Blind Motion Deblurring Using Conditional Adversarial Networks (github)
- Defense-GAN — Defense-GAN: Protecting Classifiers Against Adversarial Attacks Using Generative Models (github)
- Defo-Net — Defo-Net: Learning Body Deformation using Generative Adversarial Networks
- DeliGAN — DeLiGAN : Generative Adversarial Networks for Diverse and Limited Data (github)
- DF-GAN — Learning Disentangling and Fusing Networks for Face Completion Under Structured Occlusions
- DialogWAE — DialogWAE: Multimodal Response Generation with Conditional Wasserstein Auto-Encoder
- DiscoGAN — Learning to Discover Cross-Domain Relations with Generative Adversarial Networks
- DistanceGAN — One-Sided Unsupervised Domain Mapping
- DM-GAN — Dual Motion GAN for Future-Flow Embedded Video Prediction
- DMGAN — Disconnected Manifold Learning for Generative Adversarial Networks
- DNA-GAN — DNA-GAN: Learning Disentangled Representations from Multi-Attribute Images
- dp-GAN — Differentially Private Releasing via Deep Generative Model
- DP-GAN — DP-GAN: Diversity-Promoting Generative Adversarial Network for Generating Informative and Diversified Text
- DPGAN — Differentially Private Generative Adversarial Network
- DR-GAN — Representation Learning by Rotating Your Faces
- DRAGAN — How to Train Your DRAGAN (github)
- DRPAN — Discriminative Region Proposal Adversarial Networks for High-Quality Image-to-Image Translation
- DSH-GAN — Deep Semantic Hashing with Generative Adversarial Networks
- DSP-GAN — Depth Structure Preserving Scene Image Generation
- DTLC-GAN — Generative Adversarial Image Synthesis with Decision Tree Latent Controller
- DTN — Unsupervised Cross-Domain Image Generation
- DTR-GAN — DTR-GAN: Dilated Temporal Relational Adversarial Network for Video Summarization
- DualGAN — DualGAN: Unsupervised Dual Learning for Image-to-Image Translation
- Dualing GAN — Dualing GANs
- DVGAN — Human Motion Modeling using DVGANs
- Dynamics Transfer GAN — Dynamics Transfer GAN: Generating Video by Transferring Arbitrary Temporal Dynamics from a Source Video to a Single Target Image
- E-GAN — Evolutionary Generative Adversarial Networks
- EAR — Generative Model for Heterogeneous Inference
- EBGAN — Energy-based Generative Adversarial Network
- ecGAN — eCommerceGAN : A Generative Adversarial Network for E-commerce
- ED//GAN — Stabilizing Training of Generative Adversarial Networks through Regularization
- Editable GAN — Editable Generative Adversarial Networks: Generating and Editing Faces Simultaneously
- EGAN — Enhanced Experience Replay Generation for Efficient Reinforcement Learning
- EL-GAN — EL-GAN: Embedding Loss Driven Generative Adversarial Networks for Lane Detection
- ELEGANT — ELEGANT: Exchanging Latent Encodings with GAN for Transferring Multiple Face Attributes
- EnergyWGAN — Energy-relaxed Wassertein GANs (EnergyWGAN): Towards More Stable and High Resolution Image Generation
- ExGAN — Eye In-Painting with Exemplar Generative Adversarial Networks
- ExposureGAN — Exposure: A White-Box Photo Post-Processing Framework(github)
- ExprGAN — ExprGAN: Facial Expression Editing with Controllable Expression Intensity
- f-CLSWGAN — Feature Generating Networks for Zero-Shot Learning
- f-GAN — f-GAN: Training Generative Neural Samplers using Variational Divergence Minimization
- FairGAN — FairGAN: Fairness-aware Generative Adversarial Networks
- Fairness GAN — Fairness GAN
- FakeGAN — Detecting Deceptive Reviews using Generative Adversarial Networks
- FBGAN — Feedback GAN (FBGAN) for DNA: a Novel Feedback-Loop Architecture for Optimizing Protein Functions
- FBGAN — Featurized Bidirectional GAN: Adversarial Defense via Adversarially Learned Semantic Inference
- FC-GAN — Fast-converging Conditional Generative Adversarial Networks for Image Synthesis
- FF-GAN — Towards Large-Pose Face Frontalization in the Wild
- FGGAN — Adversarial Learning for Fine-grained Image Search
- Fictitious GAN — Fictitious GAN: Training GANs with Historical Models
- FIGAN — Frame Interpolation with Multi-Scale Deep Loss Functions and Generative Adversarial Networks
- Fila-GAN — Synthesizing Filamentary Structured Images with GANs
- First Order GAN — First Order Generative Adversarial Networks (github)
- Fisher GAN — Fisher GAN
- Flow-GAN — Flow-GAN: Bridging implicit and prescribed learning in generative models
- FrankenGAN — rankenGAN: Guided Detail Synthesis for Building Mass-Models Using Style-Synchonized GANs
- FSEGAN — Exploring Speech Enhancement with Generative Adversarial Networks for Robust Speech Recognition
- FTGAN — Hierarchical Video Generation from Orthogonal Information: Optical Flow and Texture
- FusedGAN — Semi-supervised FusedGAN for Conditional Image Generation
- FusionGAN — Learning to Fuse Music Genres with Generative Adversarial Dual Learning
- FusionGAN — Generating a Fusion Image: One’s Identity and Another’s Shape
- G2-GAN — Geometry Guided Adversarial Facial Expression Synthesis
- GAAN — Generative Adversarial Autoencoder Networks
- GAF — Generative Adversarial Forests for Better Conditioned Adversarial Learning
- GAGAN — GAGAN: Geometry-Aware Generative Adverserial Networks
- GAIA — Generative adversarial interpolative autoencoding: adversarial training on latent space interpolations encourage convex latent distributions
- GAIN — GAIN: Missing Data Imputation using Generative Adversarial Nets
- GAMN — Generative Adversarial Mapping Networks
- GAN — Generative Adversarial Networks (github)
- GAN Q-learning — GAN Q-learning
- GAN-ATV — A Novel Approach to Artistic Textual Visualization via GAN
- GAN-CLS — Generative Adversarial Text to Image Synthesis (github)
- GAN-RS — Towards Qualitative Advancement of Underwater Machine Vision with Generative Adversarial Networks
- GAN-SD — Virtual-Taobao: Virtualizing Real-world Online Retail Environment for Reinforcement Learning
- GAN-sep — GANs for Biological Image Synthesis (github)
- GAN-VFS — Generative Adversarial Network-based Synthesis of Visible Faces from Polarimetric Thermal Faces
- GAN-Word2Vec — Adversarial Training of Word2Vec for Basket Completion
- GANAX — GANAX: A Unified MIMD-SIMD Acceleration for Generative Adversarial Networks
- GANCS — Deep Generative Adversarial Networks for Compressed Sensing Automates MRI
- GANDI — Guiding the search in continuous state-action spaces by learning an action sampling distribution from off-target samples
- GANG — GANGs: Generative Adversarial Network Games
- GANG — Beyond Local Nash Equilibria for Adversarial Networks
- GANosaic — GANosaic: Mosaic Creation with Generative Texture Manifolds
- GAP — Context-Aware Generative Adversarial Privacy
- GAP — Generative Adversarial Privacy
- GATS — Sample-Efficient Deep RL with Generative Adversarial Tree Search
- GAWWN — Learning What and Where to Draw (github)
- GC-GAN — Geometry-Contrastive Generative Adversarial Network for Facial Expression Synthesis
- GeneGAN — GeneGAN: Learning Object Transfiguration and Attribute Subspace from Unpaired Data (github)
- GeoGAN — Generating Instance Segmentation Annotation by Geometry-guided GAN
- Geometric GAN — Geometric GAN
- GLCA-GAN — Global and Local Consistent Age Generative Adversarial Networks
- GMAN — Generative Multi-Adversarial Networks
- GMM-GAN — Towards Understanding the Dynamics of Generative Adversarial Networks
- GoGAN — Gang of GANs: Generative Adversarial Networks with Maximum Margin Ranking
- GONet — GONet: A Semi-Supervised Deep Learning Approach For Traversability Estimation
- GP-GAN — GP-GAN: Towards Realistic High-Resolution Image Blending(github)
- GP-GAN — GP-GAN: Gender Preserving GAN for Synthesizing Faces from Landmarks
- GPU — A generative adversarial framework for positive-unlabeled classification
- GRAN — Generating images with recurrent adversarial networks (github)
- Graphical-GAN — Graphical Generative Adversarial Networks
- GraspGAN — Using Simulation and Domain Adaptation to Improve Efficiency of Deep Robotic Grasping
- GT-GAN — Deep Graph Translation
- HAN — Chinese Typeface Transformation with Hierarchical Adversarial Network
- HAN — Bidirectional Learning for Robust Neural Networks
- HiGAN — Exploiting Images for Video Recognition with Hierarchical Generative Adversarial Networks
- HP-GAN — HP-GAN: Probabilistic 3D human motion prediction via GAN
- HR-DCGAN — High-Resolution Deep Convolutional Generative Adversarial Networks
- hredGAN — Multi-turn Dialogue Response Generation in an Adversarial Learning framework
- IAN — Neural Photo Editing with Introspective Adversarial Networks(github)
- IcGAN — Invertible Conditional GANs for image editing (github)
- ID-CGAN — Image De-raining Using a Conditional Generative Adversarial Network
- IdCycleGAN — Face Translation between Images and Videos using Identity-aware CycleGAN
- IFcVAEGAN — Conditional Autoencoders with Adversarial Information Factorization
- iGAN — Generative Visual Manipulation on the Natural Image Manifold(github)
- Improved GAN — Improved Techniques for Training GANs (github)
- In2I — In2I : Unsupervised Multi-Image-to-Image Translation Using Generative Adversarial Networks
- InfoGAN — InfoGAN: Interpretable Representation Learning by Information Maximizing Generative Adversarial Nets(github)
- IntroVAE — IntroVAE: Introspective Variational Autoencoders for Photographic Image Synthesis
- IR2VI — IR2VI: Enhanced Night Environmental Perception by Unsupervised Thermal Image Translation
- IRGAN — IRGAN: A Minimax Game for Unifying Generative and Discriminative Information Retrieval models
- IRGAN — Generative Adversarial Nets for Information Retrieval: Fundamentals and Advances
- ISGAN — Invisible Steganography via Generative Adversarial Network
- Iterative-GAN — Two Birds with One Stone: Iteratively Learn Facial Attributes with GANs (github)
- IterGAN — IterGANs: Iterative GANs to Learn and Control 3D Object Transformation
- IVE-GAN — IVE-GAN: Invariant Encoding Generative Adversarial Networks
- iVGAN — Towards an Understanding of Our World by GANing Videos in the Wild (github)
- IWGAN — On Unifying Deep Generative Models
- JointGAN — JointGAN: Multi-Domain Joint Distribution Learning with Generative Adversarial Nets
- JR-GAN — JR-GAN: Jacobian Regularization for Generative Adversarial Networks
- KBGAN — KBGAN: Adversarial Learning for Knowledge Graph Embeddings
- KGAN — KGAN: How to Break The Minimax Game in GAN
- l-GAN — Representation Learning and Adversarial Generation of 3D Point Clouds
- LAC-GAN — Grounded Language Understanding for Manipulation Instructions Using GAN-Based Classification
- LAGAN — Learning Particle Physics by Example: Location-Aware Generative Adversarial Networks for Physics Synthesis
- LAPGAN — Deep Generative Image Models using a Laplacian Pyramid of Adversarial Networks (github)
- LB-GAN — Load Balanced GANs for Multi-view Face Image Synthesis
- LBT — Learning Implicit Generative Models by Teaching Explicit Ones
- LCC-GAN — Adversarial Learning with Local Coordinate Coding
- LD-GAN — Linear Discriminant Generative Adversarial Networks
- LDAN — Label Denoising Adversarial Network (LDAN) for Inverse Lighting of Face Images
- LeakGAN — Long Text Generation via Adversarial Training with Leaked Information
- LeGAN — Likelihood Estimation for Generative Adversarial Networks
- LGAN — Global versus Localized Generative Adversarial Nets
- Lipizzaner — Towards Distributed Coevolutionary GANs
- LR-GAN — LR-GAN: Layered Recursive Generative Adversarial Networks for Image Generation
- LS-GAN — Loss-Sensitive Generative Adversarial Networks on Lipschitz Densities
- LSGAN — Least Squares Generative Adversarial Networks
- M-AAE — Mask-aware Photorealistic Face Attribute Manipulation
- MAD-GAN — Multi-Agent Diverse Generative Adversarial Networks
- MAGAN — MAGAN: Margin Adaptation for Generative Adversarial Networks
- MAGAN — MAGAN: Aligning Biological Manifolds
- MalGAN — Generating Adversarial Malware Examples for Black-Box Attacks Based on GAN
- MaliGAN — Maximum-Likelihood Augmented Discrete Generative Adversarial Networks
- manifold-WGAN — Manifold-valued Image Generation with Wasserstein Adversarial Networks
- MARTA-GAN — Deep Unsupervised Representation Learning for Remote Sensing Images
- MaskGAN — MaskGAN: Better Text Generation via Filling in the ______
- MC-GAN — Multi-Content GAN for Few-Shot Font Style Transfer (github)
- MC-GAN — MC-GAN: Multi-conditional Generative Adversarial Network for Image Synthesis
- McGAN — McGan: Mean and Covariance Feature Matching GAN
- MD-GAN — Learning to Generate Time-Lapse Videos Using Multi-Stage Dynamic Generative Adversarial Networks
- MDGAN — Mode Regularized Generative Adversarial Networks
- MedGAN — Generating Multi-label Discrete Electronic Health Records using Generative Adversarial Networks
- MedGAN — MedGAN: Medical Image Translation using GANs
- MEGAN — MEGAN: Mixture of Experts of Generative Adversarial Networks for Multimodal Image Generation
- MelanoGAN — MelanoGANs: High Resolution Skin Lesion Synthesis with GANs
- memoryGAN — Memorization Precedes Generation: Learning Unsupervised GANs with Memory Networks
- MGAN — Precomputed Real-Time Texture Synthesis with Markovian Generative Adversarial Networks (github)
- MGGAN — Multi-Generator Generative Adversarial Nets
- MGGAN — MGGAN: Solving Mode Collapse using Manifold Guided Training
- MIL-GAN — Multimodal Storytelling via Generative Adversarial Imitation Learning
- MIX+GAN — Generalization and Equilibrium in Generative Adversarial Nets (GANs)
- MIXGAN — MIXGAN: Learning Concepts from Different Domains for Mixture Generation
- MLGAN — Metric Learning-based Generative Adversarial Network
- MMC-GAN — A Multimodal Classifier Generative Adversarial Network for Carry and Place Tasks from Ambiguous Language Instructions
- MMD-GAN — MMD GAN: Towards Deeper Understanding of Moment Matching Network (github)
- MMGAN — MMGAN: Manifold Matching Generative Adversarial Network for Generating Images
- MoCoGAN — MoCoGAN: Decomposing Motion and Content for Video Generation (github)
- Modified GAN-CLS — Generate the corresponding Image from Text Description using Modified GAN-CLS Algorithm
- ModularGAN — Modular Generative Adversarial Networks
- MolGAN — MolGAN: An implicit generative model for small molecular graphs
- MPM-GAN — Message Passing Multi-Agent GANs
- MS-GAN — Temporal Coherency based Criteria for Predicting Video Frames using Deep Multi-stage Generative Adversarial Networks
- MTGAN — MTGAN: Speaker Verification through Multitasking Triplet Generative Adversarial Networks
- MuseGAN — MuseGAN: Symbolic-domain Music Generation and Accompaniment with Multi-track Sequential Generative Adversarial Networks
- MV-BiGAN — Multi-view Generative Adversarial Networks
- N2RPP — N2RPP: An Adversarial Network to Rebuild Plantar Pressure for ACLD Patients
- NAN — Understanding Humans in Crowded Scenes: Deep Nested Adversarial Learning and A New Benchmark for Multi-Human Parsing
- NCE-GAN — Dihedral angle prediction using generative adversarial networks
- ND-GAN — Novelty Detection with GAN
- NetGAN — NetGAN: Generating Graphs via Random Walks
- OCAN — One-Class Adversarial Nets for Fraud Detection
- OptionGAN — OptionGAN: Learning Joint Reward-Policy Options using Generative Adversarial Inverse Reinforcement Learning
- ORGAN — Objective-Reinforced Generative Adversarial Networks (ORGAN) for Sequence Generation Models
- ORGAN — 3D Reconstruction of Incomplete Archaeological Objects Using a Generative Adversary Network
- OT-GAN — Improving GANs Using Optimal Transport
- PacGAN — PacGAN: The power of two samples in generative adversarial networks
- PAN — Perceptual Adversarial Networks for Image-to-Image Transformation
- PassGAN — PassGAN: A Deep Learning Approach for Password Guessing
- PD-WGAN — Primal-Dual Wasserstein GAN
- Perceptual GAN — Perceptual Generative Adversarial Networks for Small Object Detection
- PGAN — Probabilistic Generative Adversarial Networks
- PGD-GAN — Solving Linear Inverse Problems Using GAN Priors: An Algorithm with Provable Guarantees
- PGGAN — Patch-Based Image Inpainting with Generative Adversarial Networks
- PIONEER — Pioneer Networks: Progressively Growing Generative Autoencoder
- Pip-GAN — Pipeline Generative Adversarial Networks for Facial Images Generation with Multiple Attributes
- pix2pix — Image-to-Image Translation with Conditional Adversarial Networks (github)
- pix2pixHD — High-Resolution Image Synthesis and Semantic Manipulation with Conditional GANs (github)
- PixelGAN — PixelGAN Autoencoders
- PM-GAN — PM-GANs: Discriminative Representation Learning for Action Recognition Using Partial-modalities (github)
- PN-GAN — Pose-Normalized Image Generation for Person Re-identification
- POGAN — Perceptually Optimized Generative Adversarial Network for Single Image Dehazing
- Pose-GAN — The Pose Knows: Video Forecasting by Generating Pose Futures
- PP-GAN — Privacy-Protective-GAN for Face De-identification
- PPAN — Privacy-Preserving Adversarial Networks
- PPGN — Plug & Play Generative Networks: Conditional Iterative Generation of Images in Latent Space
- PrGAN — 3D Shape Induction from 2D Views of Multiple Objects
- ProGanSR — A Fully Progressive Approach to Single-Image Super-Resolution
- Progressive GAN — Progressive Growing of GANs for Improved Quality, Stability, and Variation (github)
- PS-GAN — Pedestrian-Synthesis-GAN: Generating Pedestrian Data in Real Scene and Beyond
- PSGAN — Learning Texture Manifolds with the Periodic Spatial GAN
- PSGAN — PSGAN: A Generative Adversarial Network for Remote Sensing Image Pan-Sharpening
- PS²-GAN — High-Quality Facial Photo-Sketch Synthesis Using Multi-Adversarial Networks
- RadialGAN — RadialGAN: Leveraging multiple datasets to improve target-specific predictive models using Generative Adversarial Networks
- RaGAN — The relativistic discriminator: a key element missing from standard GAN
- RAN — RAN4IQA: Restorative Adversarial Nets for No-Reference Image Quality Assessment (github)
- RankGAN — Adversarial Ranking for Language Generation
- RCGAN — Real-valued (Medical) Time Series Generation with Recurrent Conditional GANs
- ReConNN — Reconstruction of Simulation-Based Physical Field with Limited Samples by Reconstruction Neural Network
- RefineGAN — Compressed Sensing MRI Reconstruction with Cyclic Loss in Generative Adversarial Networks
- ReGAN — ReGAN: RE[LAX|BAR|INFORCE] based Sequence Generation using GANs (github)
- RegCGAN — Unpaired Multi-Domain Image Generation via Regularized Conditional GANs
- RenderGAN — RenderGAN: Generating Realistic Labeled Data
- Resembled GAN — Resembled Generative Adversarial Networks: Two Domains with Similar Attributes
- ResGAN — Generative Adversarial Network based on Resnet for Conditional Image Restoration
- RNN-WGAN — Language Generation with Recurrent Generative Adversarial Networks without Pre-training (github)
- RoCGAN — Robust Conditional Generative Adversarial Networks
- RPGAN — Stabilizing GAN Training with Multiple Random Projections(github)
- RTT-GAN — Recurrent Topic-Transition GAN for Visual Paragraph Generation
- RWGAN — Relaxed Wasserstein with Applications to GANs
- SAD-GAN — SAD-GAN: Synthetic Autonomous Driving using Generative Adversarial Networks
- SAGA — Generative Adversarial Learning for Spectrum Sensing
- SAGAN — Self-Attention Generative Adversarial Networks
- SalGAN — SalGAN: Visual Saliency Prediction with Generative Adversarial Networks (github)
- sAOG — Deep Structured Generative Models
- SAR-GAN — Generating High Quality Visible Images from SAR Images Using CNNs
- SBADA-GAN — From source to target and back: symmetric bi-directional adaptive GAN
- SCH-GAN — SCH-GAN: Semi-supervised Cross-modal Hashing by Generative Adversarial Network
- SD-GAN — Semantically Decomposing the Latent Spaces of Generative Adversarial Networks
- Sdf-GAN — Sdf-GAN: Semi-supervised Depth Fusion with Multi-scale Adversarial Networks
- SEGAN — SEGAN: Speech Enhancement Generative Adversarial Network
- SeGAN — SeGAN: Segmenting and Generating the Invisible
- SegAN — SegAN: Adversarial Network with Multi-scale L1 Loss for Medical Image Segmentation
- Sem-GAN — Sem-GAN: Semantically-Consistent Image-to-Image Translation
- SeqGAN — SeqGAN: Sequence Generative Adversarial Nets with Policy Gradient (github)
- SeUDA — Semantic-Aware Generative Adversarial Nets for Unsupervised Domain Adaptation in Chest X-ray Segmentation
- SG-GAN — Semantic-aware Grad-GAN for Virtual-to-Real Urban Scene Adaption (github)
- SG-GAN — Sparsely Grouped Multi-task Generative Adversarial Networks for Facial Attribute Manipulation
- SGAN — Texture Synthesis with Spatial Generative Adversarial Networks
- SGAN — Stacked Generative Adversarial Networks (github)
- SGAN — Steganographic Generative Adversarial Networks
- SGAN — SGAN: An Alternative Training of Generative Adversarial Networks
- SGAN — CT Image Enhancement Using Stacked Generative Adversarial Networks and Transfer Learning for Lesion Segmentation Improvement
- sGAN — Generative Adversarial Training for MRA Image Synthesis Using Multi-Contrast MRI
- SiGAN — SiGAN: Siamese Generative Adversarial Network for Identity-Preserving Face Hallucination
- SimGAN — Learning from Simulated and Unsupervised Images through Adversarial Training
- SisGAN — Semantic Image Synthesis via Adversarial Learning
- Sketcher-Refiner GAN — Learning Myelin Content in Multiple Sclerosis from Multimodal MRI through Adversarial Training(github)
- SketchGAN — Adversarial Training For Sketch Retrieval
- SketchyGAN — SketchyGAN: Towards Diverse and Realistic Sketch to Image Synthesis
- SL-GAN — Semi-Latent GAN: Learning to generate and modify facial images from attributes
- SN-DCGAN — Generative Adversarial Networks for Unsupervised Object Co-localization
- SN-GAN — Spectral Normalization for Generative Adversarial Networks(github)
- SN-PatchGAN — Free-Form Image Inpainting with Gated Convolution
- Sobolev GAN — Sobolev GAN
- Social GAN — Social GAN: Socially Acceptable Trajectories with Generative Adversarial Networks
- Softmax GAN — Softmax GAN
- SoPhie — SoPhie: An Attentive GAN for Predicting Paths Compliant to Social and Physical Constraints
- Spike-GAN — Synthesizing realistic neural population activity patterns using Generative Adversarial Networks
- Splitting GAN — Class-Splitting Generative Adversarial Networks
- SR-CNN-VAE-GAN — Semi-Recurrent CNN-based VAE-GAN for Sequential Data Generation (github)
- SRGAN — Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network
- SRPGAN — SRPGAN: Perceptual Generative Adversarial Network for Single Image Super Resolution
- SS-GAN — Semi-supervised Conditional GANs
- ss-InfoGAN — Guiding InfoGAN with Semi-Supervision
- SSGAN — SSGAN: Secure Steganography Based on Generative Adversarial Networks
- SSL-GAN — Semi-Supervised Learning with Context-Conditional Generative Adversarial Networks
- ST-CGAN — Stacked Conditional Generative Adversarial Networks for Jointly Learning Shadow Detection and Shadow Removal
- ST-GAN — Style Transfer Generative Adversarial Networks: Learning to Play Chess Differently
- ST-GAN — ST-GAN: Spatial Transformer Generative Adversarial Networks for Image Compositing
- StackGAN — StackGAN: Text to Photo-realistic Image Synthesis with Stacked Generative Adversarial Networks (github)
- StainGAN — StainGAN: Stain Style Transfer for Digital Histological Images
- StarGAN — StarGAN: Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation (github)
- StarGAN-VC — StarGAN-VC: Non-parallel many-to-many voice conversion with star generative adversarial networks
- SteinGAN — Learning Deep Energy Models: Contrastive Divergence vs. Amortized MLE
- Super-FAN — Super-FAN: Integrated facial landmark localization and super-resolution of real-world low resolution faces in arbitrary poses with GANs
- SVSGAN — SVSGAN: Singing Voice Separation via Generative Adversarial Network
- SWGAN — Solving Approximate Wasserstein GANs to Stationarity
- SyncGAN — SyncGAN: Synchronize the Latent Space of Cross-modal Generative Adversarial Networks
- S²GAN — Generative Image Modeling using Style and Structure Adversarial Networks
- table-GAN — Data Synthesis based on Generative Adversarial Networks
- TAC-GAN — TAC-GAN — Text Conditioned Auxiliary Classifier Generative Adversarial Network (github)
- TAN — Outline Colorization through Tandem Adversarial Networks
- tcGAN — Cross-modal Hallucination for Few-shot Fine-grained Recognition
- TD-GAN — Task Driven Generative Modeling for Unsupervised Domain Adaptation: Application to X-ray Image Segmentation
- tempCycleGAN — Improving Surgical Training Phantoms by Hyperrealism: Deep Unpaired Image-to-Image Translation from Real Surgeries
- tempoGAN — tempoGAN: A Temporally Coherent, Volumetric GAN for Super-resolution Fluid Flow
- TequilaGAN — TequilaGAN: How to easily identify GAN samples
- Text2Shape — Text2Shape: Generating Shapes from Natural Language by Learning Joint Embeddings
- textGAN — Generating Text via Adversarial Training
- TextureGAN — TextureGAN: Controlling Deep Image Synthesis with Texture Patches
- TGAN — Temporal Generative Adversarial Nets
- TGAN — Tensorizing Generative Adversarial Nets
- TGAN — Tensor-Generative Adversarial Network with Two-dimensional Sparse Coding: Application to Real-time Indoor Localization
- TGANs-C — To Create What You Tell: Generating Videos from Captions
- tiny-GAN — Analysis of Nonautonomous Adversarial Systems
- TP-GAN — Beyond Face Rotation: Global and Local Perception GAN for Photorealistic and Identity Preserving Frontal View Synthesis
- Triple-GAN — Triple Generative Adversarial Nets
- tripletGAN — TripletGAN: Training Generative Model with Triplet Loss
- TV-GAN — TV-GAN: Generative Adversarial Network Based Thermal to Visible Face Recognition
- UGACH — Unsupervised Generative Adversarial Cross-modal Hashing
- UGAN — Enhancing Underwater Imagery using Generative Adversarial Networks
- Unim2im — Unsupervised Image-to-Image Translation with Generative Adversarial Networks (github)
- UNIT — Unsupervised Image-to-image Translation Networks (github)
- Unrolled GAN — Unrolled Generative Adversarial Networks (github)
- UT-SCA-GAN — Spatial Image Steganography Based on Generative Adversarial Network
- UV-GAN — UV-GAN: Adversarial Facial UV Map Completion for Pose-invariant Face Recognition
- VA-GAN — Visual Feature Attribution using Wasserstein GANs
- VAC+GAN — Versatile Auxiliary Classifier with Generative Adversarial Network (VAC+GAN), Multi Class Scenarios
- VAE-GAN — Autoencoding beyond pixels using a learned similarity metric
- VariGAN — Multi-View Image Generation from a Single-View
- VAW-GAN — Voice Conversion from Unaligned Corpora using Variational Autoencoding Wasserstein Generative Adversarial Networks
- VEEGAN — VEEGAN: Reducing Mode Collapse in GANs using Implicit Variational Learning (github)
- VGAN — Generating Videos with Scene Dynamics (github)
- VGAN — Generative Adversarial Networks as Variational Training of Energy Based Models (github)
- VGAN — Text Generation Based on Generative Adversarial Nets with Latent Variable
- ViGAN — Image Generation and Editing with Variational Info Generative Adversarial Networks
- VIGAN — VIGAN: Missing View Imputation with Generative Adversarial Networks
- VoiceGAN — Voice Impersonation using Generative Adversarial Networks
- VOS-GAN — VOS-GAN: Adversarial Learning of Visual-Temporal Dynamics for Unsupervised Dense Prediction in Videos
- VRAL — Variance Regularizing Adversarial Learning
- WaterGAN — WaterGAN: Unsupervised Generative Network to Enable Real-time Color Correction of Monocular Underwater Images
- WaveGAN — Synthesizing Audio with Generative Adversarial Networks
- weGAN — Generative Adversarial Nets for Multiple Text Corpora
- WGAN — Wasserstein GAN (github)
- WGAN-CLS — Text to Image Synthesis Using Generative Adversarial Networks
- WGAN-GP — Improved Training of Wasserstein GANs (github)
- WGAN-L1 — Subsampled Turbulence Removal Network
- WS-GAN — Weakly Supervised Generative Adversarial Networks for 3D Reconstruction
- XGAN — XGAN: Unsupervised Image-to-Image Translation for many-to-many Mappings
- ZipNet-GAN — ZipNet-GAN: Inferring Fine-grained Mobile Traffic Patterns via a Generative Adversarial Neural Network
- α-GAN — Variational Approaches for Auto-Encoding Generative Adversarial Networks (github)
- β-GAN — Annealed Generative Adversarial Networks
- Δ-GAN — Triangle Generative Adversarial Networks
Visit the Github repository to add more links via pull requests or create an issue to lemme know something I missed or to start a discussion. Thanks to all the contributors, especially Emanuele Plebani, Lukas Galke, Peter Waller and Bruno Gavranović.
If you like what you are reading, follow Deep Hunt — a weekly AI newsletter with special focus on Machine Learning to stay updated in this fast moving field.

















 2124
2124

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









