







性能分析原理
应用程序CPU占用分析主要可以由cpu占用率和程序运行指令数两方面进行分析,两个指标的侧重点不同:
CPU占用率:程序运行占用CPU时间与对应CPU运行总时间的比值,该数值为相对值,与每个cpu的运算效 率有关,在不同的CPU以及硬件环境下运行的差距较大
程序运行指令数据:该衡量指标采用MIPS来衡量,这里有几个概念需要澄清
1,主频
主频 = 时钟频率,它是指CPU内部晶振的频率,常用单位为MHz,它反映了CPU的基本工作节拍。
当前大部分cpu,实际主频一般会比标注的时钟频率要高,计算性能时需要以实际主频进行计算
2,时钟周期
时钟周期 t =1/ f; 主频的倒数
3,机器周期
机器周期A = mt ;一个机器周期包含若干个时钟周期
4,指令周期
指令周期B = mtn; 执行一条指令所需要的时间,一般包含若干个机器周期
5,CPI
CPI = mn; 平均每条指令的平均时钟周期个数
指令周期B = CPI×机器周期 = n(CPI=n)×m×时钟周期=nm/主频f, 注意指令周期单位是s或者ns,CPI无量纲
6,MIPS(MillionInstructions Per Second)
MIPS = 每秒执行百万条指令数 = 1/(CPI×时钟周期)= 主频/CPI
MFLOPS 每秒百万浮点运算次数。
表示秒钟所能执行的指令条数,对于微型计算机可用CPU的主频和每条指令的执行所需的时钟周期来衡量。
从上面的计算方法可以看出来,应用程序的MIPS是可以衡量应用程序运行效率的绝对参数,根据每秒钟程序的指令数,以及对应芯片的处理速度可大概得出需要的主频频率
主频与计算机频率的关系
假如我们知道了程序的每秒指令数,那么该如何推导出对应的芯片的时钟频率呢?
答:根据市场上的芯片时钟频率和对应运算速度我们可以得出结论,市场上大部分的cpu已经可以满足一个时钟周期内处理超过一条指令的需要,具体数据如下:
A系列—(Application应用处理器—多用于手机、平板等移动终端)
R系列—(Realtime实时性—如TI的TMS570LS2135)
M系列—(Microcontroller微控制器—即单片机,如STM32系列)
经典系列—(经典应用处理器慢慢在淘汰—如s3c2410)
安全内核系列—(主打安全,金融产品较常见,如POS机、UKEY、加密芯片、SE等)
series A DMIPS/MHz series B DMIPS/MHz
Arm Cortex-A5 1.57 Arm Cortex-R4 1.67 / 2.01 / 2.45
Arm Cortex-A7 1.9 Arm Cortex-R5 1.67 / 2.01 / 2.45
Arm Cortex-A8 2 Arm Cortex-R7 2.50 / 2.90 / 3.77
Arm Cortex-A9 2.5 Arm Cortex-R8 2.50 / 2.90 / 3.77
Arm Cortex-A12 3.5 Arm Cortex-R52 2.04 / 2.60/ 5.07
Arm Cortex-A15 3.4 Cortex-M0 0.87-1.27
Arm Cortex-A17 3.2 Cortex-M0+ 0.95-1.36
Arm Cortex-A32 2.3 Cortex-M1 0.8
Arm Cortex-A35 2.5 Cortex-M23 0.98
Arm Cortex-A53 2.3 Cortex-M3 1.25-1.89
Arm Cortex-A55 2.7 Cortex-M4 1.25-1.95
Arm Cortex-A57 4.1 Cortex-M33 1.5
Arm Cortex-A72 4.7 Cortex-M35P 1.5
Arm Cortex-A73 4.8 Cortex-M55 1.6
Arm Cortex-A75 5.2 Cortex-M7 2.14-3.23
Arm 7 0.9 SC000 0.87/1.02/1.27
Arm 9 1.1 SC300 1.25/1.50/1.89
Arm 10E 1.35
Arm 11 1.2
通过以上数据我们可以任务大部分的芯片运行效率在1.5左右,因此可以根据时钟频率大概得出对应芯片运算的效率
其运算逻辑大致为:
CPU主频 = MIPS / k (这个算出来的微cpu主频占用100%)
其中k为芯片运行效率(根据不同芯片取值变动,范围在1 ~ 5之间)
因此得出我们程序运算的MIPS即可得出我们程序所能够支持的CPU性能要求
如何得出程序MIPS
利用linux下的性能测试工具
perf可以得出对应的cpi数据,再根据主频即可计算出MIPS
通过perf 计算CPI以及绘制火焰图方法如下:
环境:Windows + Vmware(虚拟机环境,vmware支持cpu计数)
系统:centos7
安装perf:
yum install perf
CPU数据获取:
获取对应程序CPU运行时数据:
perf stat -p 【对应进程id】
结果例子如下:

CPI为instructions
火焰图生成
1、下载火焰图工具:
git clone https://github.com/brendangregg/FlameGraph.git
2、进行程序cpu采样:
perf record -F 99 -p 181 -g --call-graph dwarf -- sleep 60
3、转化为火焰图:
perf script -i perf.data &> perf.unfold //生成脚本文件
./FlameGraph/stackcollapse-perf.pl perf.unfold &> perf.folded
./FlameGraph/flamegraph.pl perf.folded > perf.svg //执行完成后生成perf.svg图片,可以下载到本地,用浏览器打开 perf.svg,如下图
4、最终火焰图
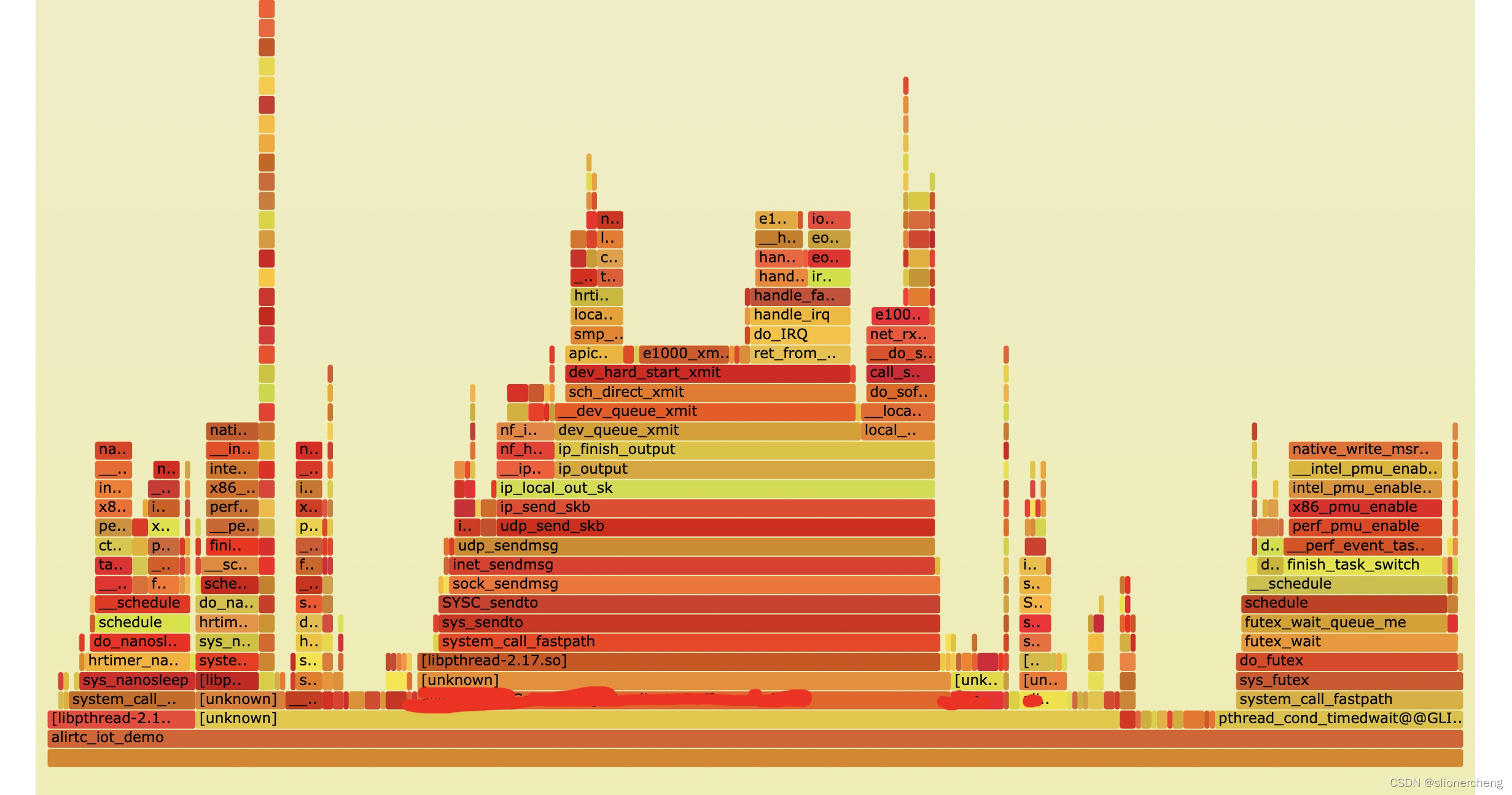
火焰图表示的是采样时间内落在该对应函数的次数,也就是说火焰图越宽的地方代表越占用cpu,那个地方就是可以优化的点

















 1624
1624

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









