










解析数据的BeautifulSoup模块

1. 获取节点内容
# 创建一个BeautifulSoup对象,获取页面正文
soup = BeautifulSoup(html_doc, features="lxml")
print('head节点内容为:\n',soup.head) # 打印head节点
print('body节点内容为:\n',soup.body) # 打印body节点
print('title节点内容为:\n',soup.title) # 打印title节点
print('p节点内容为:\n',soup.p) # 打印p节点
2. 获取节点属性
soup = BeautifulSoup(html_doc, features="lxml")
print('meta节点中属性如下:\n',soup.meta.attrs)
print('link节点中属性如下:\n',soup.link.attrs)
print('div节点中属性如下:\n',soup.div.attrs)
3. 获取节点包含的文本内容
print('title节点所包含的文本内容为:',soup.title.string)
print('h3节点所包含的文本内容为:',soup.h3.string)
4. 嵌套获取节点内容
soup = BeautifulSoup(html_doc, features="lxml")
print('head节点内容如下:\n',soup.head)
print('head节点数据类型为:',type(soup.head))
print('head节点中title节点内容如下:\n',soup.head.title)
print('head节点中title节点数据类型为:',type(soup.head.title))
print('head节点中title节点中的文本内容为:',soup.head.title.string)
print('head节点中title节点中文本内容的数据类型为:',type(soup.head.title.string))
4.1.获取子节点
# 创建一个BeautifulSoup对象,获取页面正文
soup = BeautifulSoup(html_doc, features="lxml")
print(soup.head.contents) # 列表形式打印head下所有子节点
print(soup.head.children) # 可迭代对象形式打印head下所有子节点
4.2.获取孙节点
# 创建一个BeautifulSoup对象,获取页面正文
soup = BeautifulSoup(html_doc, features="lxml")
print(soup.body.descendants) # 打印body节点下所有子孙节点内容的generator对象
for i in soup.body.descendants: # 循环遍历generator对象中的所有子孙节点
print(i) # 打印子孙节点内容
4.3.获取父节点
# 创建一个BeautifulSoup对象,获取页面正文
soup = BeautifulSoup(html_doc, features="lxml")
print(soup.title.parent) # 打印title节点的父节点内容
print(soup.title.parents) # 打印title节点的父节点及以上内容的generator对象
for i in soup.title.parents: # 循环遍历generator对象中的所有父节点及以上内容
print(i.name) # 打印父节点及祖先节点名称
4.4.获取兄弟节点
# 创建一个BeautifulSoup对象,获取页面正文
soup = BeautifulSoup(html_doc, features="lxml")
print(soup.p.next_sibling) # 打印第一个p节点下一个兄弟节点(文本节点内容)
print(list(soup.p.next_sibling)) # 以列表形式打印文本节点中的所有元素
div = soup.p.next_sibling.next_sibling # 获取p节点同级的第一个div节点
print(div) # 打印第一个div节点内容
print(div.previous_sibling) # 打印第一个div节点上一个兄弟节点(文本节点内容)
4.5 方法获取内容
4.5.1 find_all()获取所有符合条件的内容
1.name参数
# 创建一个BeautifulSoup对象,获取页面正文
soup = BeautifulSoup(html_doc, features="lxml")
print(soup.find_all(name='p')) # 打印名称为p的所有节点内容
print(type(soup.find_all(name='p'))) # 打印数据类型
2.attrs参数
# 创建一个BeautifulSoup对象,获取页面正文
soup = BeautifulSoup(html_doc, features="lxml")
print('字典参数结果如下:')
print(soup.find_all(attrs={'value':'1'})) # 打印value值为1的所有内容,字典参数
print('赋值参数结果如下:')
print(soup.find_all(class_='p-1')) # 打印class为p-1的所有内容,赋值参数
print(soup.find_all(value='3')) # 打印value值为3的所有内容,赋值参数
3.text参数
# 创建一个BeautifulSoup对象,获取页面正文
soup = BeautifulSoup(html_doc, features="lxml")
print('指定字符串所获取的内容如下:')
print(soup.find_all(text='零基础学Python')) # 打印指定字符串所获取的内容
print('指定正则表达式对象所获取的内容如下:')
print(soup.find_all(text=re.compile('Python'))) # 打印指定正则表达式对象所获取的内容
4.5.2 find()获取第一个匹配的节点内容
# 创建一个BeautifulSoup对象,获取页面正文
soup = BeautifulSoup(html_doc, features="lxml")
print(soup.find(name='p')) # 打印第一个name为p的节点内容
print(soup.find(class_='p-3')) # 打印第一个class为p-3的节点内容
print(soup.find(attrs={'value':'4'})) # 打印第一个value为4的节点内容
print(soup.find(text=re.compile('Python'))) # 打印第一个文本中包含Python的文本信息
4.5.3 其他方法

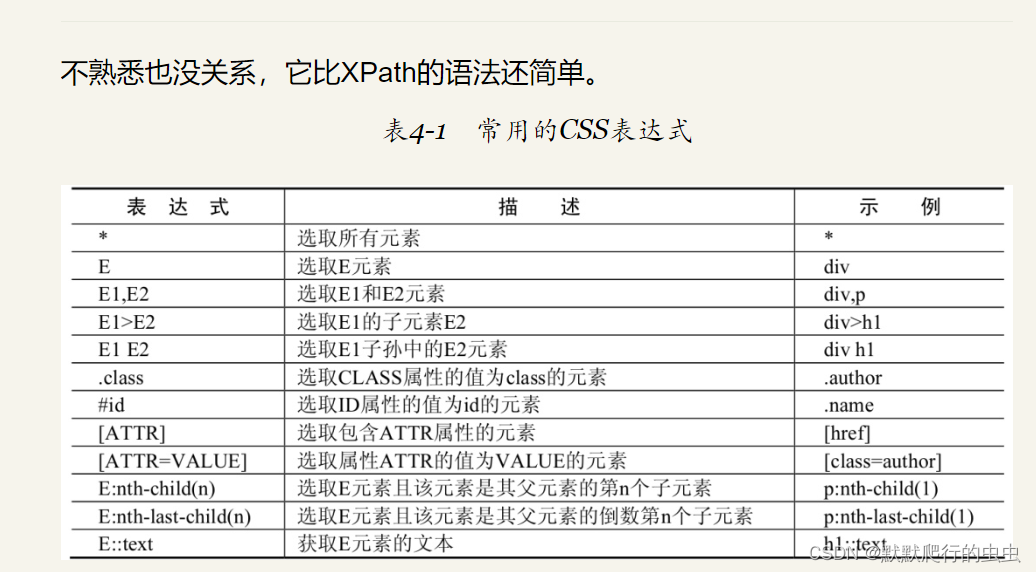
4.6 CSS选择器
使用CSS选择器获取节点内容。
# 创建一个BeautifulSoup对象,获取页面正文
soup = BeautifulSoup(html_doc, features="lxml")
print('所有p节点内容如下:')
print(soup.select('p')) # 打印所有p节点内容
print('所有p节点中的第二个p节点内容如下:')
print(soup.select('p')[1]) # 打印所有p节点中的第二个p节点
print('逐层获取的title节点如下:')
print(soup.select('html head title')) # 打印逐层获取的title节点
print('类名为test_2所对应的节点如下:')
print(soup.select('.test_2')) # 打印类名为test_2所对应的节点
print('id值为class_1所对应的节点如下:')
print(soup.select('#class_1')) # 打印id值为class_1所对应的节点

















 832
832











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











