







使用场景:
在根据非索引字段查询时,若查询结果只有一条记录,可以在sql语句中使用 " limit 1",来有效缩短查询时间。
缩短查询时间的原因:加入Limit后,查询结果能够被一级缓存保存!从底层分析的话,加入Limit 1后,匹配到一条数据后,就不会再往下查询了,所以,性能的提升和数据量的大小有很大关系。
实验:
创建表t-user;
create table t_user(
id int primary key auto_increment,
email varchar(25),
password varchar(25)
);

使用存储过程插入1000000条记录:
CREATE DEFINER=`root`@`localhost` PROCEDURE `NewProc`()
BEGIN
DECLARE i INT;
START TRANSACTION;
SET i=0;
WHILE i<1000000 DO
INSERT INTO t_user VALUES(NULL,CONCAT(i+1,'@qq.com'),i+1);
SET i=i+1;
END WHILE;
COMMIT;
END
在Navicat创建存储函数的步骤:
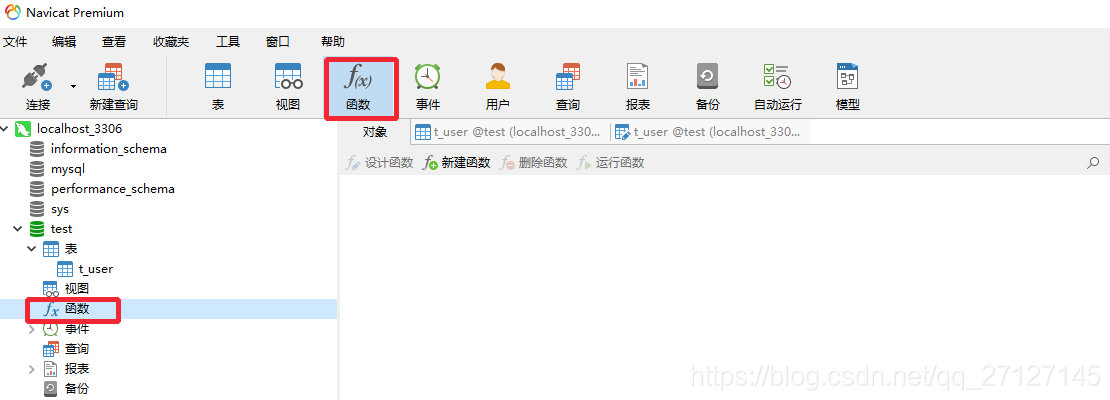

编写完后,一定要点击保存,然后才能点击运行。

查询结果:
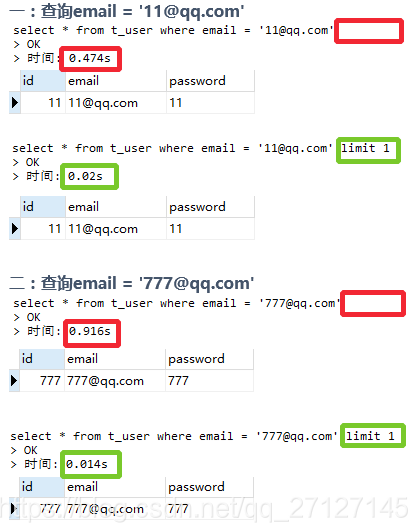
通过实验结果,发现使用limit 1可以有效缩短查询时间。使用这种方式避免了全表扫描。
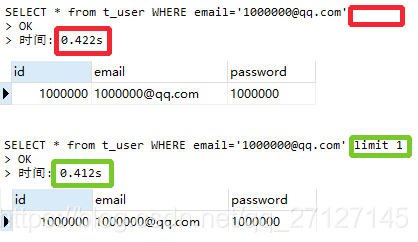
但是若果插查询的数据位于表的末尾,这种查询效果不大。
例如:

















 1927
1927

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









