






要想了解WSS通信的过程,可以使用浏览器中的开发者工具进行抓包,方法如下:
这里以Chrome浏览器为例,按F12打开开发者工具,打开有WSS通信的网址,这里使用讯飞开放平台中的语音听写API。它是采用的WSS来实现的。
https://www.xfyun.cn/services/voicedictation
在该网页下,有一个产品体验,可以直接在网页上使用语音识别,并实时听写,转换成文字。
在开发者工具中,打开Network 标签页,并将Filter筛选设为WS。即为WebSockets
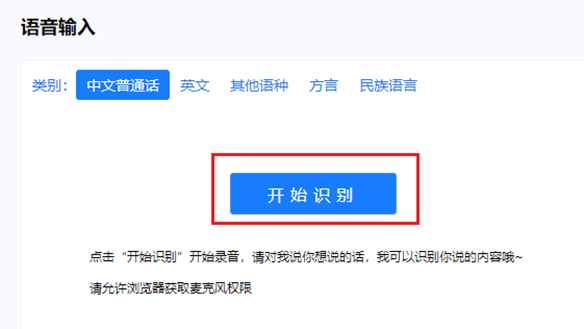
然后点击语音听写页中开始识别。
在开发者工具中,点击其中一个WSS请求,就可以在右边的一些标签页中查看该WSS的动态请求内容了。
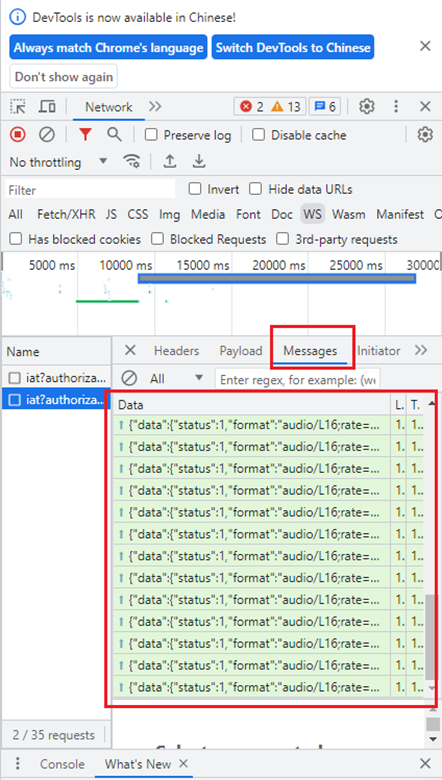
可以点开每一个数据查看具体内容。

这里,是将音频按每一固定大小的帧作为一个包,通过WSS发送给服务器端。
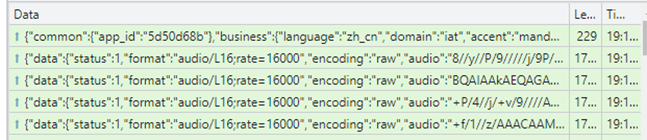
从包可以看到,首先是发送一些API的参数配置
然后就开始发送音频帧数据,数据是使用的Base64编码后的字符串
当API收到一定的数据,有返回时,就可以查看返回的包中的数据了。
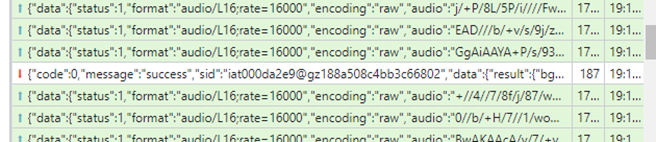
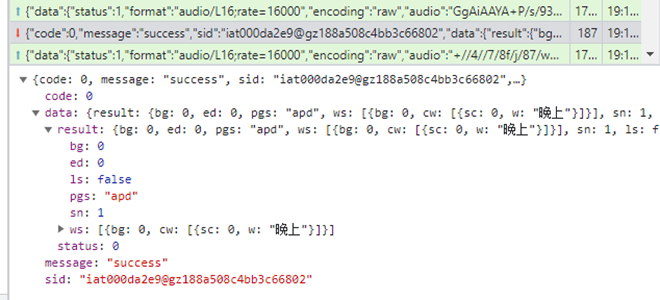
从返回的数据中可以看到,通过前面的音频,识别出了”晚上“这段文字,就返回给客户端。
再经过一些发送的请求包后,又返回到客户端识别结果数据
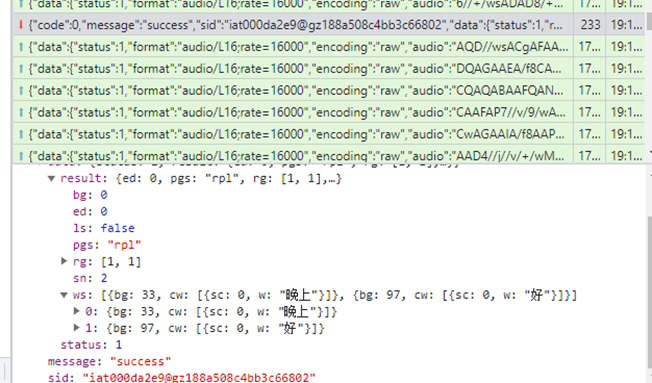
这里,将前面识别的文字也一并包含在其内了。这应该是对前面识别的内容进行了统一的调整或在智能理解后的基础上的调整结果。















 3209
3209











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











