







参考书:《机器学习 Python实践》
序言
泛人工智能( Artificial General Intelligence , AGI )
超级人工智能( Artificial Super Intelligence , ASI )
第一部分 初始
像一个优秀的工程师一样使用机器学习,而不要像一个机器学习专家一样 使用机器学习方法 -Google
1 初识机器学习
目标:机器学习在实践中的应用,介绍利用 yt on 的生态环境,使用机器 习的算法来解决工程实践中的问题,而不是介绍算法本身。
1.2 什么是机器学习
涉及概率论、统计 学、线性代数、算法等多门学科。
机器学习的算法分为两大类 监督学习和无监督学习(还有半监督学习,自监督学习)
补充:
监督学习是一种机器学习算法,其基本思想是使用有标签数据集来训练模型,已知输入数据和对应的输出数据,训练模型通过学习从输入到输出的映射关系,从而实现针对新样本的准确预测。
在监督学习中,有标签的数据集通常被分为训练集、验证集和测试集三部分,其中训练集用于训练模型,验证集用于确定模型的超参数等,测试集用于测试模型的泛化性能。
监督学习的任务通常可以分为分类和回归两类。分类是预测离散分类变量,如“是”和“否”、“0”和“1”等;回归是预测连续变量,如价格、温度等。监督学习在实际应用中被广泛用于图像识别、自然语言处理、语音识别等领域。
非监督学习是一种机器学习算法,其基本思想是使用未标注数据集来训练模型,从数据中发现潜在的模式或结构,无需预先指定输出变量。因此,非监督学习通常被用于探索性数据分析或数据预处理等领域。
在非监督学习中,数据集中的样本通常被视为特征空间上的点,算法通过寻找这些点之间的关系来发现数据中的模式。无监督学习的任务通常可以分为聚类、降维和关联等。
聚类是将数据集中的样本分成多个不同的组,每组内部的样本相似性较高,不同组之间的样本差异较大;降维是将高维数据映射到低维空间中,以便更好的可视化、存储和处理;关联则是探索数据集中不同变量之间的关系。非监督学习被广泛应用于医学、生物学、金融和社交网络等领域中的数据探索和预测。
半监督学习是介于监督学习和无监督学习之间的一种机器学习算法,其基本思想是在少量有标注数据和大量无标注数据的情况下,使用无标注数据来帮助提高有标注数据集的分类精度。在半监督学习中,使用有标注数据集来训练模型,并使用未标注数据来学习数据特征,从而提高模型的泛化性能。
半监督学习的一个关键的假设是:在相同的数据分布下,相似的样本点往往属于同一类别。因此,半监督学习以此为基础,将未标注数据与有标注数据联系起来,通过利用未标注数据的分布状态,来为分类问题提供更多的信息和数据。半监督学习适用于实际中标注数据难以获取的情况,可应用于文本分类、图像分类、推荐系统和语音识别等领域。
自监督学习是一种无需外部标签指定的监督学习方法,它利用数据的内部结构来监督学习过程。自监督学习使用未标注的数据来作为自学习的对象,通过针对数据进行某些隐式的或者显式的的监督任务,从而学习无监督方式下的特征表示。
与监督学习不同,自监督学习是通过推断数据的本身特性来提取特征,自身定义标签来进行潜在的监督,学习用于对测试数据的表示。自监督学习的任务可以是预测数据的相邻位置、颜色、大小、旋转等揭示的内在关系。
自监督学习可以节约大量的标注时间和费用,为推广并实现机器学习模型的快速全球化和推广提供了重要的基础。在自然语言处理、计算机视觉等领域,自监督学习已经证明是一种有效的学习技巧。
1.3 Python中的机器学习
重点关注监督学习中的分类与回归问题处理的预测模型
补充:scikit-learn是一个用于Python编程语言的机器学习模块,开源且免费。它提供了各种标准的机器学习算法和工具,包括分类、回归、聚类、降维、数据预处理、模型选择和评测等。同时,它还支持数据处理和可视化等功能,并包含了各种模型选择技术,比如交叉验证。
scikit-learn是一个易于上手和应用的机器学习工具包,对学习机器学习的初学者来说非常友好。它提供了许多易于使用的API,同时还支持高效的、针对大规模数据和稀疏数据的实现。~最近版本还支持了深度学习库如 TensorFlow和 PyTorch。 目前,scikit-learn是机器学习领域中最常用和最受欢迎的Python工具之一。
利用机器学习的预测模型来解决问题共有6个基本步骤:
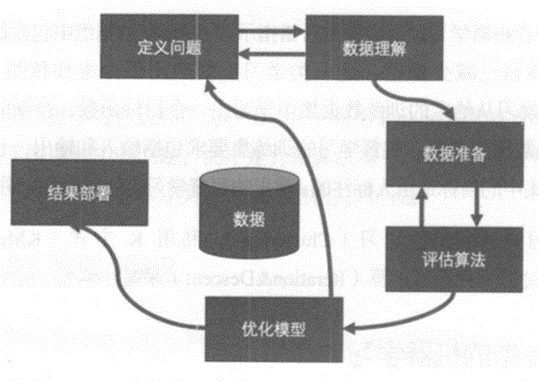
定义问题: 研究和提炼问题的特征,以帮助我们更好地理解项目的目标。
数据理解: 通过描述性统计和可视化来分析现有的数据。
数据准备: 对数据进行格式化,以便于构建一个预测模型
评估算法: 通过一定的方法分离一部分数据,用来评估算法模型,并选取一部分代表数据进行分析,以改善模型。
优化模型: 通过调参和集成算法提升预测结果的准确度。
结果部署: 完成模型 并执行模型来预测结果和展示。
1.4 学习机器学习的原则和技巧
了解自己已具备的能力和知识,明确要达到的目标,可以利用工具帮助自己快速达成目标
创建半正式的工作产品 以博客文章、技术报告和代码存储的形式记下学习和发现的内容,快速地为自己和他人提供一系列可以展示的技能、知识及反思
启动一个可以在一个小时内完成的小项目。
通过每周完成一个项目来保持你的学习势头,并建立积累自己的项目工作区。
在微博、微信、 Github 等社交工具上分享自己的成果,或者随时随地地展示自己的兴趣,增加技能、知识,并获得反馈。
Github地址:https://github.com/weizy1981/MachineLearning















 5418
5418











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











