






- 总体框架图
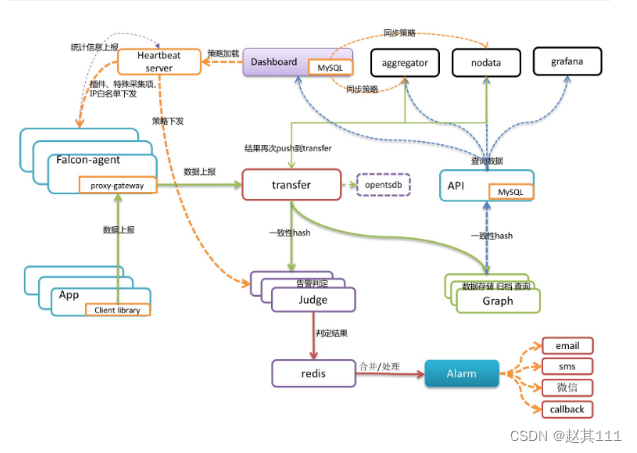
- transfer的数据来源:
- falcon-agent采集的基础监控数据
- falcon-agent执行用户自定义的插件返回的数据
- client library:线上的业务系统,都嵌入使用了统一的perfcounter.jar,对于业务系统中每个RPC接口的qps、latency都会主动采集并上报,上面这三种数据,都会先发送给本机的proxy-gateway,再由gateway转发给transfer
- falcon-agent
falcon-agent:用于自发现的采集单机的各种数据和指标,agent发送心跳信息给
HBS的时候,会把hostname、ip、agent version、plugin version等信息告诉HBS,hbs负责写入host表。如果host表中没数据,需要检查这条链路是否通畅
- transfer目前支持的业务后端
有三种,judge、graph、opentsdb。
judge是我们开发的高性能告警判定组件,满足规则后发送给alerm,alerm再以邮件,短信等形式发送给用户
graph是我们开发的高性能数据存储、归档、查询组件,graph收到数据以后,会以rrdtool的数据归档方式来存储,同时提供查询RPC接口。query面向终端用户,收到查询请求后,会去多个graph里面,查询不同metric的数据,汇总后统一返回给用户
opentsdb是开源的时间序列数据存储服务。可以通过transfer的配置文件来开启。
- 整体工作流程
- 服务器运行agent
- agent采集各项监控项值,传递给transfer
- transfer校验和整理监控项值,做一致性hash分片,传给judge组件判断是否触发告警策略
- transfer校验和整理监控项值,做一致性hash分片,传给graph组件做数据存储
- judge根据具体报警策略或阈值进行告警判断,如触发告警则组装告警event事件,写入缓存队列
- alerm和sender根据event事件的判断结果,执行event,向用户组发送短信或邮件
- graph收到监控项数据后,将数据存储为rrd格式,进行归档并提供查询接口
- query将调用graph查询接口,将监控数据传送到dashboard页面
- dashboard渲染页面,展示曲线报表图
- portal提交界面供用户配置机器分组,报警策略,表达式,nodata等配置
- transfer工作流程
- 每个后端的graph或judge实例都建立了一个rpc连接池和一个定长Queue队列
- 定长Queue队列目的是应对高峰流量,丢失一部分高峰时段的数据保证了后端的graph和judge组件不受影响
- v1.0版本的openfalcon中,每个graph实例可以有多个ip而且transfer会给每个ip发送相同的一份数据,但是judge中每个实例只能有1个ip。
- hbs工作流程(hbs更多承担配置中心)
- agent可以从hbs同步报警策略,进程存活监控,端口存活监控等信息
- agent定期发送心跳信息,hbs负责更新host表,hbs读取portal数据库
- 心跳服务器,公司所有agent都会连到HBS,每分钟发一次心跳请求















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









