






Real-time Neural Radiance Talking Portrait Synthesis via Audio-spatial Decomposition.
作者来自北京大学、百度、悉尼新南威尔士大学。
论文地址:https://arxiv.org/pdf/2211.12368
代码地址:https://github.com/ashawkey/RAD-NeRF
虽然动态神经辐射场 (NeRF) 在talking head的高保真3D建模中取得了成功,但缓慢的训练和推理速度严重阻碍了它们的潜在使用。在本文中,我们提出了一个基于 NeRF 的高效框架,该框架通过利用基于网格的 NeRF 的最新成功实现了talking head的实时合成和更快的收敛。我们提出方案的关键在于将固有的高维说话肖像表示分解为三个低维特征网格。具体来说,分解的音频空间编码模块使用 3D 空间网格和 2D 音频网格对动态头部进行建模。躯干在轻量级伪 3D 可变形模块中与另一个 2D 网格处理。这两个模块都侧重于在良好的渲染质量的前提下的效率。大量实验表明,我们的方法可以生成真实和音频嘴唇同步的talking head视频,同时与以前的方法相比也非常高效。
应用:数字人类创作、虚拟视频会议和电影制作
参考:
- Thomas M ̈uller, Alex Evans, Christoph Schied, and Alexander Keller. Instant neural graphics primitives with a multiresolution hash encoding. arXiv:2201.05989, Jan. 2022. (网格Nerf)
- Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. In CVPR, 2018.(LIPloss)
1. 现有技术存在什么问题?
基于Nerf的人脸3d渲染能够有效的建模出比较真实的人脸,但是这些方法都具有一个问题,视频的生成速度都非常的慢。例如AD-Nerf,在显卡3090上,每一帧(450*450)的推理速度为12s,远低于25帧的可接受速度。
目前,提高NeRF效率的工作都是在减少MLP大小,并将3D场景显示存储在可训练的网络结构中。主要是将MLP替换为线性差值。然而,这些面向静态场景的方法并不直接适用于我们的动态情况。
我们确定了构建基于 NeRF 的实时音频驱动肖像的两个主要挑战:1)如何使用基于网格的NeRF有效地表示空间和音频信息仍未解决。2)对不那么复杂但同样重要的躯干部分进行有效的建模,以实现逼真的肖像,这不是微不足道的。
2. 本文的方案是什么?论文是如何解决这些问题的?创新点在什么地方?
我们利用最近的基于网格的NeRF表示[1],并将其高效的静态场景建模能力适应动态音频驱动的人像建模。我们的关键方案是将固有的高维音频引导肖像表示分解为三个低维可训练特征网格。具体来说,对于动态头部建模,我们提出了一个分解的音频空间编码模块,该模块将音频和视觉表示分解为两个网格。虽然我们在 3D 中保留了静态空间坐标,但音频动态被编码为低维“坐标”。此外,我们没有在一个高维特征网格中查询音频和视觉坐标,而是表明它们可以分为两个独立的低维特征网格,这进一步降低了插值的成本。这种分解的音频空间编码为说话头部建模提供了一种有效的动态NeRF。
至于躯干部分,我们着眼于它的运动模式,以追求更低的计算成本。鉴于观察到拓扑变化较少参与躯干运动,我们提出了一种轻量级的伪 3D 可变形模块,以使用 2D 特征网格对躯干进行建模。将这两个模块与进一步的特定于肖像的NeRF加速设计相结合,我们的方法可以在现代GPU上实现实时推理速度。
创新点总结:
- 我们提出了一个分解的音频空间编码模块,使用两个低维特征网格有效地建模固有的高维音频驱动的面部动态。
- 我们提出了一种轻量级的伪 3D 可变形模块,以进一步提高合成与头部运动同步的自然躯干运动的效率。
- 我们的框架可以比以前的工作更快地运行 500 倍,具有更好的渲染质量,并且还支持说话肖像的各种显式控制,例如头部姿势、眨眼和背景图像。
- 增加眼动控制。
知识回顾
dynamic NeRF。原始的NeRF的过程可以表示为:
F
:
x
(
x
,
y
,
z
)
,
d
(
θ
,
ϕ
)
−
>
σ
,
c
(
r
,
g
,
b
)
F:x(x,y,z),d(\theta,\phi) ->\sigma,c(r,g,b)
F:x(x,y,z),d(θ,ϕ)−>σ,c(r,g,b)。在动态场景中,还需要添加一个附加条件(例如,当前时间等)。以前的方案通过两种方法进行建模:1)基于变形的方法,在每个位置和时间步长处学习变形
∆
x
∆x
∆x(
G
:
x
,
t
→
∆
x
G: x, t→∆x
G:x,t→∆x),然后将其添加到原始位置x。2)基于调制的方法直接将全视函数条件化为时间
F
:
x
,
d
,
t
→
σ
,
c
F: x, d, t→σ,c
F:x,d,t→σ,c。
由于变形场的内在连续性,基于变形的方法不擅长建模拓扑变化(如张嘴和闭口),我们选择基于调制的策略来建模头部部分,而基于变形的策略来建模躯干部分,运动模式更简单。
音频驱动的神经辐射talking head的训练数据通常是一个3-5分钟的场景特定视频,带有同步音频轨道,由静态摄像机记录。每个图像帧的预处理主要有三个步骤:(1)头部、颈部、躯干和背景部分的语义解析;(2)提取2d landmaker,包括眼睛和嘴唇;(3)人脸跟踪,估计头部姿态参数。请注意,这些步骤仅适用于培训过程。对于音频处理,采用自动语音识别(Automatic Speech Recognition, ASR)模型从音轨中提取音频特征。基于头部姿势和音频条件,NeRF可以用来学习合成头部部分。由于躯干部分与头部部分不在同一坐标系中,因此需要单独建模,例如由另一个完整的NeRF进行建模。
(什么是网格的NeRF)最近基于网格的NeRF[1]使用三维特征网格编码器
E
s
p
a
t
i
a
l
3
E^3_{spatial}
Espatial3(
f
=
E
s
p
a
t
i
a
l
3
(
x
)
f=E^3_{spatial}(x)
f=Espatial3(x))对静态场景的三维空间信息进行编码,其中
x
∈
R
3
x∈\R^3
x∈R3为空间坐标,
f
f
f为编码后的空间特征。这种特征网格编码器用线性插值代替MLP转发来查询空间特征,显著提高了训练和推理的效率。这使得实现静态3D场景的实时渲染速度成为可能[1]。我们以此为灵感,将其扩展到编码动态说话人像合成所需的高维音频空间信息。
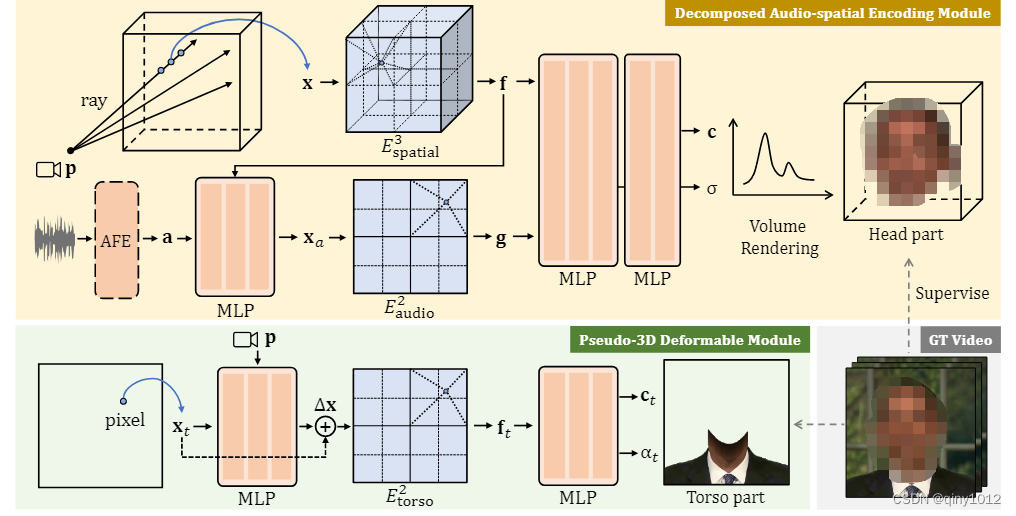
分解音频空间编码模块
什么是可训练的特征网格,
在之前的方案中,通常将音频转化为高维特征然后和空间特征进行拼接,然而,线性插值的复杂性随着输入维数的增加呈指数增长。如果我们直接在网格编码器中使用高维连接的音频空间特征,它很快就会变得计算负担不起。因此,我们提出了两种设计来缓解音频空间信息建模的维度诅咒。
首先,我们将高维音频特征
a
a
a压缩成一个低维音频坐标
x
a
∈
R
D
x_a∈\R^D
xa∈RD,其中维数
D
∈
[
1
,
2
,
3
]
D∈[1,2,3]
D∈[1,2,3]很小。这是通过与空间相关的MLP实现的
x
a
=
M
L
P
(
a
,
f
)
x_a =MLP(a, f)
xa=MLP(a,f)。我们在这里将空间特征连接起来,这样音频坐标就明确地依赖于空间位置。该操作使音频特征从隐式学习空间信息中解脱出来,从而使音频坐标更加紧凑。音频坐标的灵感来源于HyperNeRF中环境坐标的可变形切片曲面类型[39],但与特征网格编码器相结合,实现了高效率。
其次,我们不再使用高维
g
=
E
3
+
D
(
x
,
x
a
)
g = E^{3+D}(x, xa)
g=E3+D(x,xa)的组合音频-空间网格编码器,而是将其分解为两个低维网格编码器,分别对音频和空间坐标进行编码:
f
=
E
s
p
a
t
i
a
l
3
(
x
)
f = E^3_{spatial}(x)
f=Espatial3(x),
g
=
E
a
u
d
i
o
D
(
x
a
)
g = E^D_{audio}(xa)
g=EaudioD(xa)。这进一步将插值成本从
2
3
+
D
2^{3+D}
23+D降低到
2
3
+
2
D
(
D
≥
1
)
2^3+ 2^D (D≥1)
23+2D(D≥1)。进行插值后,可以将空间特征
f
f
f和音频特征
g
g
g串联起来。
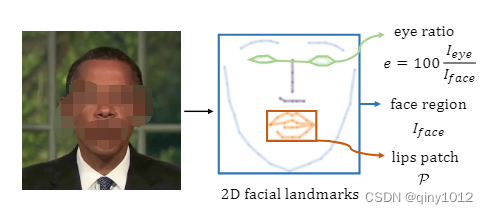
眼动也是自然说话人像合成的关键因素。然而,由于眨眼与音频信号之间没有很强的相关性,以往的方法往往忽略了眼睛的控制,从而导致眨眼过快或半眨眼等伪影。我们提供了一种明确控制眨眼的方法。如下图所示,我们根据二维面部标志计算眼部面积占整个图像的百分比,并使用这个比率(通常在0%到0.5%之间)作为一维眼部特征e。我们将NeRF网络条件化在这个眼部特征上,并表明这种简单的修改足以让模型通过普通的RGB损失来学习眼部动态。在测试时,我们可以很容易地调整眼睛的百分比来控制眼睛的眨眼。
最终,将空间特征f、音频特征g、眼睛特征e与潜在外观嵌入i串联起来[19,34],使用一个小的MLP产生密度和颜色:
c
,
σ
=
M
L
P
(
f
,
g
,
e
,
i
)
c,\sigma = MLP(f,g,e,i)
c,σ=MLP(f,g,e,i)
伪3D变形模块
与头部部分相比,躯干部分几乎是静态的,只有轻微的运动,没有拓扑变化。以前的方法要么使用另一个全动态NeRF来建模躯干[22],要么与头部一起学习纠缠变形场[32]。我们认为这些方法过多,并提出了一个更有效的伪3d变形模块,如上图的下半部分所示。
我们的方法可以看作是基于2D变形的动态NeRF的版本。我们不需要沿着每条相机光线采样一系列的点,我们只需要从图像空间中采样一个像素坐标
x
t
∈
R
2
x_t∈R^2
xt∈R2。变形以头部姿势
p
p
p为条件,使躯干运动与头部运动同步。我们采用MLP来预测变形:
∆
x
=
M
L
P
(
x
t
,
p
)
∆x =MLP(xt, p)
∆x=MLP(xt,p)。将变形坐标馈送到二维特征网格编码器,得到躯干特征:
f
t
=
E
t
o
r
s
o
2
(
x
t
+
∆
x
)
f_t = E^2_{torso}(x_t +∆x)
ft=Etorso2(xt+∆x)。另一个MLP用于生成躯干
R
G
B
RGB
RGB颜色和
σ
\sigma
σ值,
c
t
,
σ
t
=
M
L
P
(
f
t
,
i
t
)
c_t,\sigma_t = MLP(f_t,i_t)
ct,σt=MLP(ft,it)。该基于变形的模块可以成功地建模躯干动态,并合成与头部匹配的自然躯干图像。更重要的是,通过二维特征网格的伪三维表示非常轻巧和高效。
训练细节
最大占用网格修剪。提高NeRF效率的一种常用技术是保持占用网格来修剪射线采样空间[10,37]。这对于静态场景来说很简单。由于占用网格也是静态的,我们可以使用3D网格来存储它。对于动态场景,占用值也依赖于动态条件,这需要额外的维度。然而,高维占用网格更难存储和维护,导致模型尺寸和训练时间大大增加。
我们观察到,对于说话头来说,变化的音频条件引起的占用变化通常很小,可以忽略不计。因此,我们建议为所有音频条件维护一个最大占用网格,而不是为每个音频条件维护一个占用网格。在训练中,我们从训练数据集中随机抽取音频条件,并保持最大占用值。这样,我们只需要一个3D网格来存储占用值,就可以成功地对不同音频条件下的射线采样空间进行修剪。
损失函数,使用MSE来优化NeRF(和原始的NeRF相同):
L
c
o
l
o
r
=
∑
C
∣
∣
C
−
C
g
t
∣
∣
2
2
L_{color} = \sum_{C}||C - C_{gt}||^2_2
Lcolor=C∑∣∣C−Cgt∣∣22
此外,使用熵正则化项来鼓励像素透明度为0或1:
L
e
n
t
r
o
g
y
=
−
∑
σ
(
(
σ
l
o
g
(
σ
)
+
(
1
−
σ
)
l
o
g
(
1
−
σ
)
)
L_{entrogy} = -\sum_{\sigma}((\sigma log(\sigma) + (1- \sigma)log(1- \sigma))
Lentrogy=−σ∑((σlog(σ)+(1−σ)log(1−σ))
理想情况下,音频条件应该只影响面部区域。为了稳定动态建模,我们还在音频坐标上提出了L1正则化项:
L
d
y
n
a
m
i
c
=
∑
x
a
∣
x
a
∣
L_{dynamic} = \sum_{x_a}|x_a|
Ldynamic=xa∑∣xa∣
高品质的唇部对于合成肖像的自然效果至关重要。我们发现,仅通过
L
c
o
l
o
r
L_{color}
Lcolor中逐像素的MSE损失很难学习到嘴唇的复杂结构信息。因此,我们建议对具有斑块结构损失的嘴唇区域进行微调,例如LPIPS[63]损失。我们没有从整个图像中随机采样像素作为常见的NeRF训练管道,而是根据面部地标对嘴唇所在的图像补丁P进行采样。然后,我们可以应用LPIPS损失与λ平衡的MSE损失的组合来微调唇区:
L
f
i
n
e
t
u
n
e
=
∑
C
∣
∣
C
−
C
g
t
∣
∣
2
2
+
λ
L
I
P
I
P
S
(
P
,
P
g
t
)
L_{fine_tune} = \sum_{C}||C - C_{gt}||^2_2 + \lambda LIPIPS(P,P_{gt})
Lfinetune=C∑∣∣C−Cgt∣∣22+λLIPIPS(P,Pgt)
3.性能效果如何?
我们为 20, 000 步训练头部部分,并为 5,000步微调嘴唇。在头部部分收敛后,我们使用相同的学习率策略训练躯干部分 20, 000 步。头部和躯干的训练分别大约需要 5 小时和 2 小时。所有实验均在一个 NVIDIA V100 GPU 上执行。
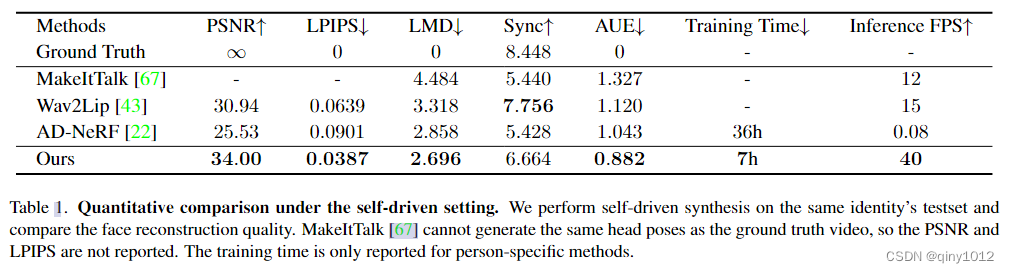
4.2定量评估 (Quantitative Evaluation)
比较设置和指标:
- 自驱动设置 (Self-driven
setting):使用与AD-NeRF相同的Obama数据集进行训练和测试。由于有同一身份的地面真实图像,可以使用如PSNR(峰值信噪比)、LPIPS(Learned Perceptual Image Patch Similarity)和LMD(Landmark Distance)等指标来评估肖像重建质量。 - 交叉驱动设置 (Cross-driven setting):选择NVP和SynObama的两个音频剪辑来驱动其他方法。在这种情况下,没有相同身份的地面真实图像,因此采用SyncNet置信度(Sync)和动作单元误差(AUE)来衡量音频-唇动同步和唇部相关肌肉动作的一致性。
评估结果:
- 在自驱动评估中,与能够生成全分辨率视频的最新方法相比,提出的方法在大多数指标上都取得了更好的质量,并且具有实时推理帧率。
- 具体来说,与基线AD-NeRF相比,提出的方法推理速度快了约500倍,并且收敛速度快了约5倍。
- 在交叉驱动结果中,提出的方法与最近的方法相比具有可比的性能,证明了合成唇部的准确性。
4.3定性评估 (Qualitative Evaluation)
评估结果:
- 在自驱动设置下,提出的方法生成的说话人像在嘴唇区域更为清晰和准确,与AD-NeRF相比,同时在训练和推理方面也快得多。
- 在交叉驱动设置下,提出的方法能够稳健地合成音频同步的唇动,尤其是唇部运动较大时(例如,发音‘wa’时的大张口)。
- 与使用14小时视频进行训练的SynObama相比,提出的方法只在5分钟视频上训练,但生成的质量相当。
消融实验
- 音频坐标维度 (Audio Coordinate Dimension):作者探讨了音频坐标维度D的不同选择对模型性能的影响。他们测试了1D、2D和3D音频坐标,并发现较低的维度可以加快推理速度,但可能会牺牲生成质量;而较高的维度则会使模型更慢且更难收敛。实验结果表明,2D音频坐标最适合他们的设置。
- 动态建模 (Dynamic Modeling):对于头部建模,作者实验了不同的网络主干结构,包括仅使用MLP的隐式主干、组合的音频-空间特征网格以及分解的音频-空间特征网格。他们还测试了基于变形和调制的动态建模策略,并发现所提出的分解音频-空间编码在性能和速度之间取得了最佳平衡。
- 光线采样数量 (Ray Sampling Count):作者研究了每个光线的最大采样点数对推理速度和图像质量的影响。他们发现,与一般的3D场景相比,人头部由于结构更简单,因此需要较少的采样点就能达到良好的渲染质量。实验表明,每条光线16个采样点足够合成逼真的图像,同时保持快速的推理速度。
- 网络主干结构 (Network Backbone):作者展示了不同网络主干结构对RGB和深度合成的影响。隐式主干倾向于生成模糊的深度,而基于变形的主干无法有效模拟唇部区域的拓扑变化。















 312
312

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









