







Hadoop Map,Reducer 输出压缩
1 压缩位置的选择

1.1 压缩参数配置
- Hadoop 引入了编码/解码器

2 Map,Reducer 输出端采用压缩
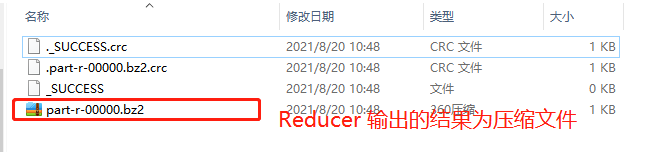
MapReduce 的输入输出文件都是未压缩的文件,Hadoop可以对 Map 任务的中间结果输出做压缩,因为它要写在硬盘并且通过网络传输到 Reduce 节点,对其压缩可以提高很多性能,这些工作只要设置两个属性即可,Reduce输出压缩根据实际的需求场景判断, 我们来看下代码怎么设置
2.1 code
- Driver
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.compress.BZip2Codec;
import org.apache.hadoop.io.compress.CompressionCodec;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCountDriver {
public static void main(String[] args) throws Exception {
// 1 获取配置信息以及获取 job 对象
Configuration conf = new Configuration();
// 开启 map 端输出压缩
conf.setBoolean("mapreduce.map.output.compress", true);
// 设置 map 端输出压缩方式
conf.setClass("mapreduce.map.output.compress.codec", BZip2Codec.class, CompressionCodec.class);
Job job = Job.getInstance(conf);
// 2 关联本 Driver 程序的 jar
job.setJarByClass(WordCountDriver.class);
// 3 关联 Mapper 和 Reducer 的 jar
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
// 4 设置 Mapper 输出的 kv 类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 5 设置最终输出 kv 类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 6 设置输入和输出路径
FileInputFormat.setInputPaths(job, new Path("D:\\xxx\\input.txt"));
FileOutputFormat.setOutputPath(job, new Path("D:\\xxx\\out"));
// 设置 reduce 端输出压缩开启
FileOutputFormat.setCompressOutput(job, true);
// 设置压缩的方式
FileOutputFormat.setOutputCompressorClass(job, BZip2Codec.class);
// FileOutputFormat.setOutputCompressorClass(job, GzipCodec.class);
// FileOutputForm
// 7 提交 job
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}
- Mapper
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
Text k = new Text();
IntWritable v = new IntWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 1 获取一行
String line = value.toString();
// 2 切割
String[] words = line.split(",");
// 3 输出
for (String word : words) {
k.set(word);
context.write(k, v);
}
}
}
- Reducer
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
int sum;
IntWritable v = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context
context) throws IOException, InterruptedException {
// 1 累加求和
sum = 0;
for (IntWritable count : values) {
sum += count.get();
}
// 2 输出
v.set(sum);
context.write(key, v);
}
}















 165
165











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









