







本文转载自 瑟荻 http://blog.csdn.net/neal1991/article/details/46571999 ,仅用作学习。
PCA算法
算法步骤:
假设有m条n维数据。
1. 将原始数据按列组成n行m列矩阵X
2. 将X的每一行(代表一个属性字段)进行零均值化,即减去这一行的均值
3. 求出协方差矩阵C=1/mXXT
4. 求出协方差矩阵的特征值以及对应的特征向量
5. 将特征向量按对应特征值大小从上到下按行排列成矩阵,取前k行组成矩阵P
6. Y=PX即为降维到k维后的数据
实例

以这个为例,我们用PCA的方法将这组二维数据降到一维
因为这个矩阵的每行已经是零均值,所以我们可以直接求协方差矩阵:
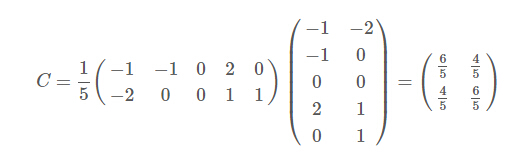
然后求其特征值和特征向量,求解后的特征值为:
λ1=2,λ2=2/5
其对应的特征向量分别是:
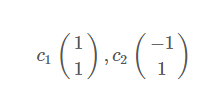
由于对应的特征向量分别是一个通解,c1和c2可取任意实数。那么标准化后的特征向量为:
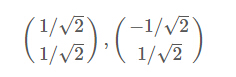
因此我们的矩阵P是:
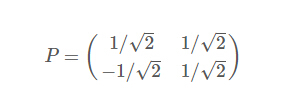
可以验证协方差矩阵C的对角化:
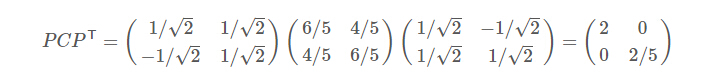
最好我们用P的第一行诚意数据矩阵,就得到了降维后的数据表示:
降维后的投影结果如下图:
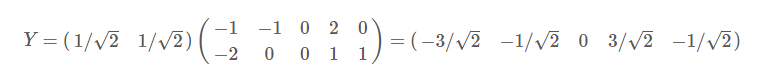
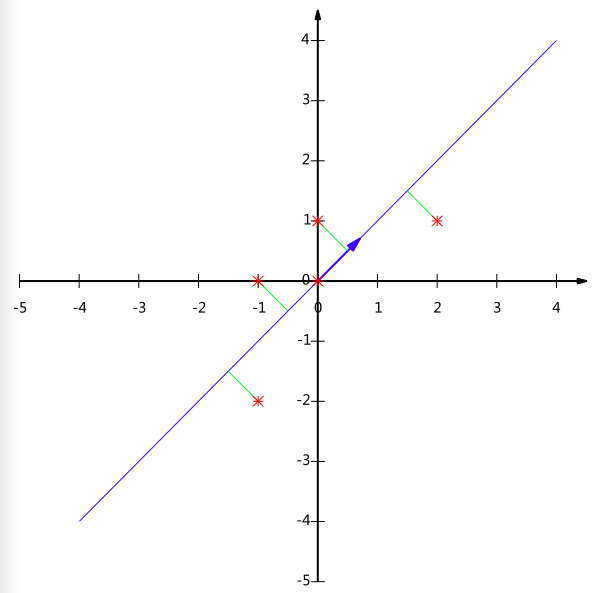
PCA本质上是将方差最大的方向作为主要特征,并且在各个正交方向上将数据“离相关”,也就是让它们在不同的正交方向上没有相关性。
因此,PCA也存在一些限制,例如它可以很好地解除线性相关,但是对于高阶相关性就没有办法了。对于存在高阶相关性的数据,可以考虑Kernel PCA,通过Kernel将非线性相关转化为线性相关。另外,PCA假设数据各特征分布在正交方向上,如果在非正交方向上存在几个方差较大的方向,PCA的效果就大打折扣。
PCA是一种无参数技术,也就是说面对同样的数据,如果不考虑清晰,谁来做结果都一样,没有主观参数的介入,所以PCA便于通用实现,但是本身没有个性化的优化。
本文主要参考:http://blog.codinglabs.org/articles/pca-tutorial.html















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









