







文章目录
大数据4v特征:
- 数据量大
- 数据种类多
- 速度快
- 价值密度低
回归和分类
回归问题与分类问题本质上都是要建立映射关系
- 回归:回归问题的输出空间定义了一个度量 [公式] 去衡量输出值与真实值之间的“误差大小”。
- 分类:其输出空间B不是度量空间,即所谓“定性”。也就是说,在分类问题中,只有分类“正确”与“错误”之分。
损失函数
0-1损失:
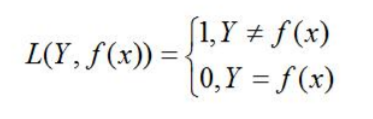
平方损失:
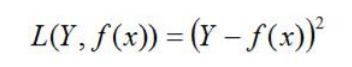
绝对损失:
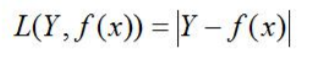
对数损失:
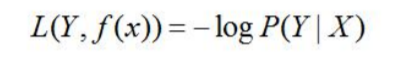
策略
经验风险
模型f(x)关于训练数据集的平均损失记为经验损失(Remp):
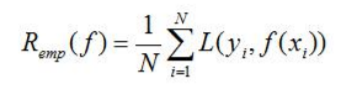
期望风险Remp是模型关于联合分布的期望损失,经验风险Remp是模型关于训练集的平均损失。根据大数定理,当N趋于无穷时,经验风险Remp趋于期望风险。
经验风险最小化
经验风险最小化策略认为,经验风险最小的模型是最优模型:
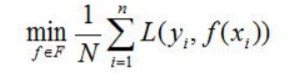
例子:极大似然估计(模型为条件概率分布,损失函数为对数损失函数,经验风险最小化等价于极大似然估计)
结构风险
经验风险最小化,在样本量很小时会产生过拟合现象。结构风险最小化为了防止过拟合提出的策略,在经验风险上加上表示模型复杂程度的正则化项。结构风险的定义为:
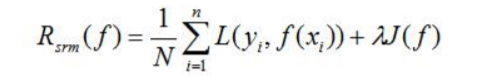
结构风险最小化
其中J为模型复杂程度,模型越复杂J越大;反之模型越简单J越小。
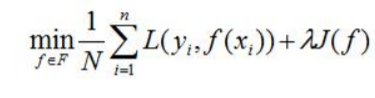
正则化项
一般形式如下:
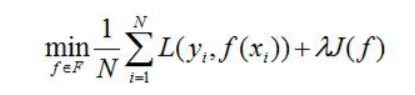
第二项J为正则化项。正则化项可以取不同的形式,可以为模型参数向量的范数。例如在回归问题中,损失函数是平方损失,正则化项可以为L2范数:
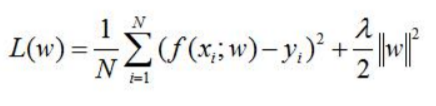
亦可为L1范数:
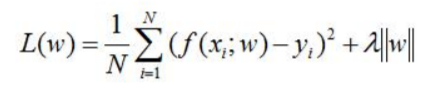
交叉验证
一般取少于1/3的数据作为验证数据。
10折验证
把数据样本分为10份,轮流选其中9份作为训练数据,将剩下一份作为测试数据,把10次结果的均值作为对算法精度的估计。
同理有K折验证,取K-1份数据作为训练数据,剩下一份做验证。亦称作留一验证。
混淆矩阵

- 若一个实例是正类并且被预测为正类,即为真正类(True Postive TP)
- 若一个实例是正类,但是被预测成为负类,即为假负类(False Negative FN)
- 若一个实例是负类,但是被预测成为正类,即为假正类(False Postive FP)
- 若一个实例是负类,但是被预测成为负类,即为真负类(True Negative TN)
准确率(P值)
准确率是针对预测结果而言的,它表示的是预测为正的样本中有多少是真正的样本。定义:
P = TP / (TP+FP)
召回率(R值)
召回率是针对我们原来的样本而来的,它表示的是样本中的正例有多少被预测正确了。定义:
R = TP / (TP+FN)
F值
检索结果Precision越高越好,同时Recall也越高越好,但事实上两者在某些情况下是有矛盾的。最常见的方法是F-Measure,通过计算F值来评价一个指标。例如F1值:
F1=2PR/(P+R)
ROC曲线
定义:接收者操作特征(receiveroperating characteristic),ROC曲线上每个点反映着对同一信号刺激的感受性。
横纵轴
横轴:负正类率(false postive rate FPR)特异度,划分实例中所有负例占所有负例的比例;(1-Specificity)
纵轴:真正类率(true postive rate TPR)灵敏度,Sensitivity(正类覆盖率)
真正类率(true postive rate TPR)
TPR = TP / (TP+FP)
TPR = TP / P
负正类率(false postive rate FPR)
FPR = FP / (TN + FN)
FPR = FP / N
AUC 值
定义:ROC曲线下的面积大小。
计算方法:延ROC曲线做积分。















 271
271











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









