







前言
什么是AI?
The theory and development of computer systems able to perform tasks normally requiring human intelligence.(–Oxford Dictionary)
Using data to solve problems.(–cy)
过程
下图是车质网投诉页面:http://www.12365auto.com/zlts/0-0-0-0-0-0_0-0-0-0-0-0-0-1.shtml

首页的网址为:http://www.12365auto.com/zlts/0-0-0-0-0-0_0-0-0-0-0-0-0-1.shtml。

点击翻页后面有2、3、4…页,网址也分别为:
http://www.12365auto.com/zlts/0-0-0-0-0-0_0-0-0-0-0-0-0-2.shtml
http://www.12365auto.com/zlts/0-0-0-0-0-0_0-0-0-0-0-0-0-3.shtml
http://www.12365auto.com/zlts/0-0-0-0-0-0_0-0-0-0-0-0-0-4.shtml
程序分步(先爬取一页)
#先根据网址得到一个BeautifulSoup对象
request_url=http://www.12365auto.com/zlts/0-0-0-0-0-0_0-0-0-0-0-0-0-1.shtml
#先加一个headers
headers={'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36'}
html=requests.get(request_url,headers=headers,timeout=10)
content=html.text#得到了一个str类型的内容
#通过content去创建一个BeautifulSoup对象
soup=BeautifulSoup(content,'html.parser',from_encoding='utf-8')
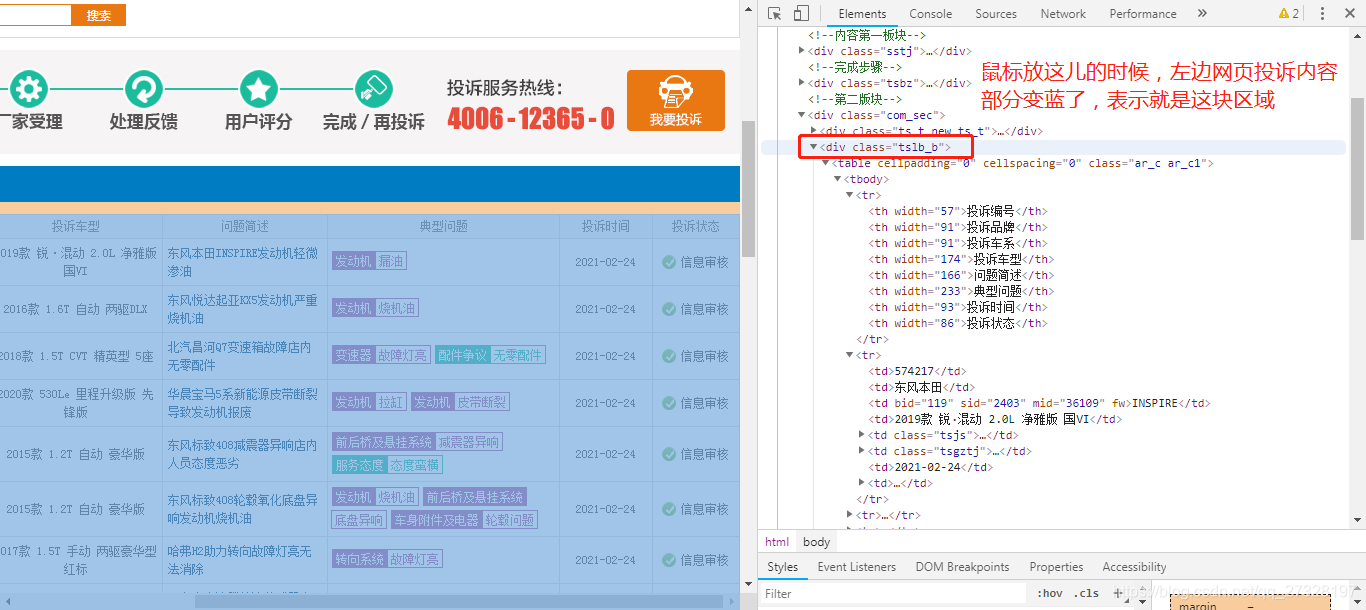
#有了soup这个BeautifulSoup对象,找到完整的投诉信息框
temp=soup.find('div',class_="tslb_b")#这里的div 和 tslb_b都是查看页面元素之后找到对应的东西,这个是我们要去候选的区域
#先准备好一个dataframe准备把解析到的数据给放到这个dataframe里面
import pandas as pd
##投诉编号 投诉品牌 投诉车系 投诉车型 问题简述 典型问题 投诉时间 投诉状态
df=pd.DataFrame(columns=['id','brand','car_modle','type','desc','problem','datatime','status'])
tr_list=temp.find_all('tr')#得到里面所有的tr就是汽车投诉那个表
for tr in tr_list:#再去获取里面的每一行 每一行的8个<td>就是要拿到的内容
tempMy={}
#第一个tr没有td 因为它就是网页中的列索引名称 从第二个tr开始 里面才td 存放的是表格里的内容
td_list=tr.find_all('td')
if len(td_list)>0:#如果有td 就去提取里面的内容
tempMy['id'],tempMy['brand'],tempMy['car_modle'],tempMy['type'],tempMy['desc'],tempMy['problem'],tempMy['datatime'],tempMy['status']=td_list[0].text,td_list[1].text,td_list[2].text,td_list[3].text,td_list[4].text,td_list[5].text,td_list[6].text,td_list[7].text
df=df.append(tempMy,ignore_index=True)

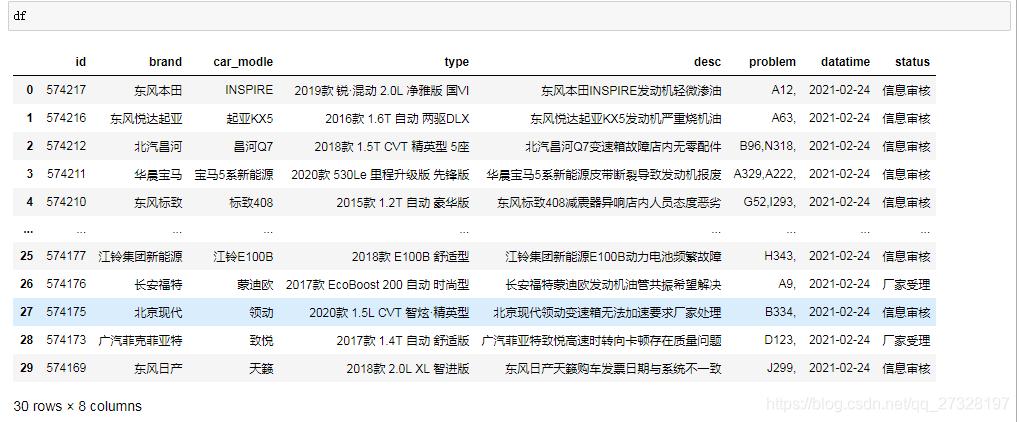
程序运行之后就爬取到了本地:
程序一步到位(爬取10页)
#先导包
import requests
from bs4 import BeautifulSoup
#先准备好一个dataframe准备把解析到的数据给放到这个dataframe里面
import pandas as pd
##投诉编号 投诉品牌 投诉车系 投诉车型 问题简述 典型问题 投诉时间 投诉状态
result=pd.DataFrame(columns=['id','brand','car_modle','type','desc','problem','datatime','status'])
def get_info(request_url):
"""一步到位"""
## 1根据指定的网址url得到一个BeautifulSoup对象
headers={'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36'}
#把request_url和headers放入requests.get()函数里面得到一个response对象
html=requests.get(request_url,headers=headers,timeout=10)
#再拿到这个responce对象的文字部分 str
content=html.text
#再把这个str喂入BeautifulSoup中得到一个bs对象
soup=BeautifulSoup(content,'html.parser',from_encoding='utf-8')
#把投诉框里面的内容给拿到了 下面这步是翻看了网页的源码确定的find()里面的内容
temp=soup.find('div',class_='tslb_b')
#temp里面所有的tr就是汽车投诉那个表
tr_list=temp.find_all('tr')
##投诉编号 投诉品牌 投诉车系 投诉车型 问题简述 典型问题 投诉时间 投诉状态
df_info=pd.DataFrame(columns=['id','brand','car_modle','type','desc','problem','datatime','status'])
for tr in tr_list:#再去获取里面的每一行 每一行的8个<td>就是要拿到的内容
tempMy={}#先用个字典 准备存放每一个td里面的内容
#第一个tr没有td 因为它就是网页中的列索引名称 从第二个tr开始 里面才td 存放的是表格里的内容
td_list=tr.find_all('td')
if len(td_list)>0:#如果有td 就去提取里面的内容
tempMy['id'],tempMy['brand'],tempMy['car_modle'],tempMy['type'],tempMy['desc'],tempMy['problem'],tempMy['datatime'],tempMy['status']=td_list[0].text,td_list[1].text,td_list[2].text,td_list[3].text,td_list[4].text,td_list[5].text,td_list[6].text,td_list[7].text
#添加到外面那个大的dataframe里面
df_info=df_info.append(tempMy,ignore_index=True)
return df_info
for i in range(1,11):
result=result.append( get_info('http://www.12365auto.com/zlts/0-0-0-0-0-0_0-0-0-0-0-0-0-'+str(i)+'.shtml') )
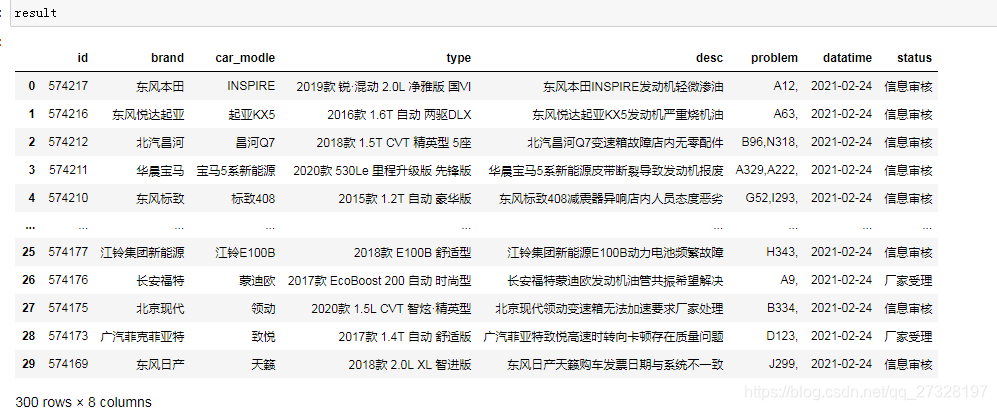
然后把这个转成excle或者csv文件即可
result.to_csv("车质网汽车投诉.csv")

总结
爬虫需谨慎。(如果您发现我写的不对,欢迎在评论区批评指正)。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









