







概述
域对抗训练(Domain-Adversarial Training of Neural Networks,DANN)属于广义迁移学习的一种, 可以矫正另一个域的数据集的分布, 也可以看成是一种特殊的对抗式生成网络(GAN), 他也确实和 GAN 在差不多的时间发表. 此文主要记录如何在 Tensorflow2::keras API 下实现 DANN, 可以直接看使用案例.
原理回顾 (可跳过)
域对抗训练技术(Domain-Adversarial Training of Neural Networks,DANN)是一种简单高效的无监督域自适应方法.
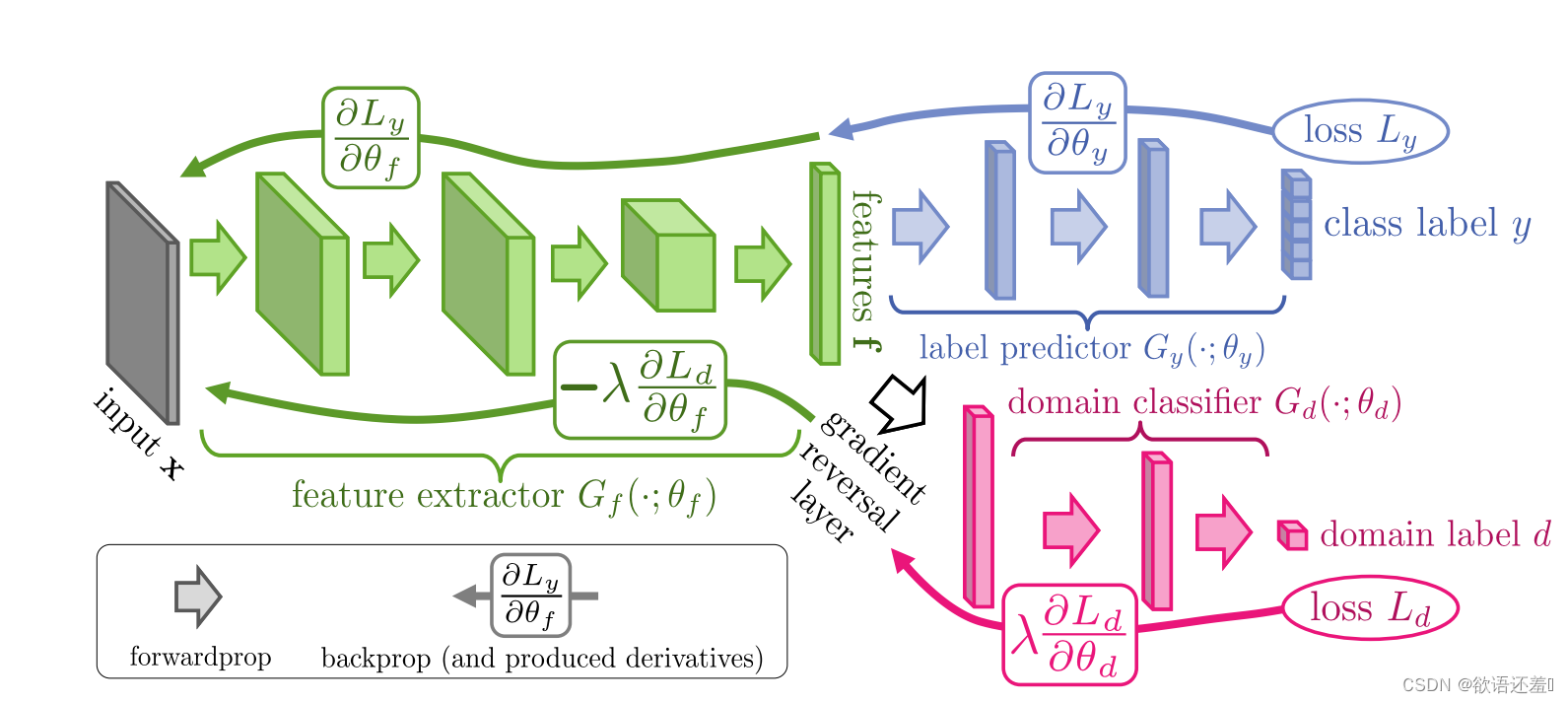
如上图, DANN 的做法是:首先通过一个深度网络来提取出某个域的输入数据的高层抽象特征(绿色部分),再通过一个域分类器(红色部分)对域进行分类;绿色部分的任务是想要学习到能骗过红色部分的特征,让域分类器不能区分输入数据来自于哪一个域,也就做到了把不同域的数据映射到同一个空间。绿色部分和红色部分可以看成分别构成了对抗神经网络的 Generator 与 Discriminator,不过在此 DANN中是插入了一个梯度反转层(Gradient Reversal Layer,GRL)对传播的梯度乘以一个负常数,来对绿色网络进行梯度上升并对红色部分实行梯度下降。然而网络很可能会学习到只输出一个常数向量的能力,此时不管什么域的输入数据都映射为了同一个向量,域分类器虽然分不出域,但对后续的分类任务非常不利;为了防止此类情况的发生,需要再引入标签分类器(蓝色部分)来约束特征提取网络,在训练阶段它需要对有标签的源域数据进行目标分类。
根据原文, 下面对 DANN 的损失函数与训练过程进行定量阐述。对于某一批输入
x
i
,
i
=
1
⋯
N
\boldsymbol{x}_i, i=1\cdots N
xi,i=1⋯N,假设前
n
n
n 个为有标签的源域数据,后
N
−
n
N-n
N−n 个为无标签的目标域数据。源域数据样本
x
i
\boldsymbol{x}_i
xi 一次前向传播后,由上图中网络的两个输出部分可以得到两个损失:
L
y
i
(
θ
f
,
θ
y
)
=
L
y
(
G
y
(
G
f
(
x
i
;
θ
f
)
;
θ
y
)
,
y
i
)
L
d
i
(
θ
f
,
θ
d
)
=
L
d
(
G
d
(
G
f
(
x
i
;
θ
f
)
;
θ
d
)
,
d
i
)
\begin{array}{c} \mathcal{L}_{y}^{i}\left(\theta_{f}, \theta_{y}\right) = \mathcal{L}_{y}\left(G_{y}\left(G_{f}\left(\mathbf{x}_{i} ; \theta_{f}\right) ; \theta_{y}\right), y_{i}\right) \\ \mathcal{L}_{d}^{i}\left(\theta_{f}, \theta_{d}\right) = \mathcal{L}_{d}\left(G_{d}\left(G_{f}\left(\mathbf{x}_{i} ; \theta_{f}\right) ; \theta_{d}\right), d_{i}\right) \end{array}
Lyi(θf,θy)=Ly(Gy(Gf(xi;θf);θy),yi)Ldi(θf,θd)=Ld(Gd(Gf(xi;θf);θd),di)
其中
G
f
,
y
,
d
(
⋅
)
G_{f,y,d}(\cdot)
Gf,y,d(⋅) 表示了三个网络,而
θ
f
,
y
,
d
\theta_{f,y,d}
θf,y,d 为它们的参数;
L
y
,
d
\mathcal{L}_{y,d}
Ly,d 是标签预测网络和域分类网络的损失函数,一般选为交叉熵损失函数,将其带上上标
i
i
i 后表示为该样本一次传播的损失。对于目标域样本,则不含有
L
y
i
\mathcal{L}_{y}^i
Lyi 这一项。基于上述的对抗思想,总体的损失函数为:
E
(
θ
f
,
θ
y
,
θ
d
)
=
1
n
∑
i
=
1
n
L
y
i
(
θ
f
,
θ
y
)
−
λ
(
1
n
∑
i
=
1
n
L
d
i
(
θ
f
,
θ
d
)
+
1
n
′
∑
i
=
n
+
1
N
L
d
i
(
θ
f
,
θ
d
)
)
E\left(\theta_{f}, \theta_{y}, \theta_{d}\right)=\frac{1}{n} \sum_{i=1}^{n} \mathcal{L}_{y}^{i}\left(\theta_{f}, \theta_{y}\right)-\lambda\left(\frac{1}{n} \sum_{i=1}^{n} \mathcal{L}_{d}^{i}\left(\theta_{f}, \theta_{d}\right)+\frac{1}{n^{\prime}} \sum_{i=n+1}^{N} \mathcal{L}_{d}^{i}\left(\theta_{f}, \theta_{d}\right)\right)
E(θf,θy,θd)=n1i=1∑nLyi(θf,θy)−λ(n1i=1∑nLdi(θf,θd)+n′1i=n+1∑NLdi(θf,θd))
其中正数
λ
\lambda
λ 为梯度反转层的超参数,其值不能太大。如果
λ
\lambda
λ 过大相当于给红色部分给予很高的权重,驱使其将域分类完全分错,过犹不及,并不符合分不出域(即希望输出为一个均匀分布的向量)的初衷。综上,训练时 DANN 实际的优化目标为:
(
θ
^
f
,
θ
^
y
)
=
argmin
θ
f
,
θ
y
E
(
θ
f
,
θ
y
,
θ
^
d
)
θ
^
d
=
argmax
θ
d
E
(
θ
^
f
,
θ
^
y
,
θ
d
)
\begin{aligned} \left(\hat{\theta}_{f}, \hat{\theta}_{y}\right) &=\underset{\theta_{f}, \theta_{y}}{\operatorname{argmin}} E\left(\theta_{f}, \theta_{y}, \hat{\theta}_{d}\right) \\ \hat{\theta}_{d} &=\underset{\theta_{d}}{\operatorname{argmax}} E\left(\hat{\theta}_{f}, \hat{\theta}_{y}, \theta_{d}\right) \end{aligned}
(θ^f,θ^y)θ^d=θf,θyargminE(θf,θy,θ^d)=θdargmaxE(θ^f,θ^y,θd)
其中的最小化与最大化构成了一组对抗任务。
下图是作者原文中效果不错的一次实验结果:

GRL 层实现
可以直接用于 keras 的 Functional API 编程, 因为大家都是直接继承的 layers.Layer, 初始化时需要给定 lambda_ 即梯度要乘以的负数.
class GradientReversalLayer(tf.keras.layers.Layer):
"""The gradient reversal layer is a layer that multiplies the gradient by a negative constant during
backpropagation.
Args:
lambda_: Float32, the constant by which the gradient is multiplied. It should be a negative number.
"""
def __init__(self, lambda_: float = -1):
super().__init__(trainable=False, name="gradient_reversal_layer")
self.lambda_ = tf.constant(lambda_, dtype=tf.float32) # Normally, a negative value
def call(self, x, **kwargs):
return self.grad_reversed(x)
@tf.custom_gradient
def grad_reversed(self, x):
"""
It returns input and a custom gradient function.
Args:
x: The input tensor.
Returns:
the input x and the custom gradient function.
"""
def custom_gradient(dy):
return self.lambda_ * dy
return x, custom_gradient
def get_config(self):
config = super().get_config().copy()
config.update({
"lambda": float(self.lambda_.numpy())
})
return config
主要参考:
https://stackoverflow.com/questions/56841166/how-to-implement-gradient-reversal-layer-in-tf-2-0
https://www.tensorflow.org/guide/eager#%E8%87%AA%E5%AE%9A%E4%B9%89%E6%A2%AF%E5%BA%A6
使用 GRL 的域对抗(DANN)模型实现
修改两个分类器可以自己实现, 这里只用了一层全连接直接 softmax. 参数中需要给定一个 feature_extractor 即特征提取网络, 比如可以来自于 tf.keras.applications.ResNet50 并指定 include_top=false, 这样会去掉最上层的 softmax 而输出高维特征. 如果是自己的其他的提取器, 想修改的话, 可以见后面.
class DomainAdversarialModel:
"""
Domain-Adversarial Training of Neural Networks (DANN) in Tensorflow2.
Args:
feature_extractor: A model of tf.keras.Model, it would have attributes like .input, .output
num_labels: Int, the number of labels.
num_domains: Int, the number of domains.
lambda_: Float32, the constant by which the gradient is multiplied. It should be a negative number.
Attributes:
output layer name of label classifier: "label_predict"
output layer name of domain classifier: "domain_predict"
"""
def __init__(self, feature_extractor: tf.keras.Model, num_labels, num_domains, lambda_: float = -1,
name_label_classifier="label_predict", name_domain_classifier="domain_predict"):
self.feature_extractor = feature_extractor # has to be a tf.keras.Model
self.num_labels = num_labels
self.num_domains = num_domains
self.lambda_ = lambda_
self.name_label_classifier = name_label_classifier
self.name_domain_classifier = name_domain_classifier
def get_model(self):
feature = self.feature_extractor.output
if len(self.feature_extractor.output_shape) != 2:
# make sure feature has a shape of (None, feature_dim). Flatten is important for pytorch, maybe
# not necessary for Tensorflow2.keras.
feature = tf.keras.layers.Flatten()(feature)
# output1 --> label_classifier
label_predict = self.label_classifier(feature)
# output2 --> domain_classifier
domain_predict = GradientReversalLayer(self.lambda_)(feature)
domain_predict = self.domain_classifier(domain_predict)
return tf.keras.Model(inputs=self.feature_extractor.input,
outputs=[label_predict, domain_predict])
def label_classifier(self, x):
# x = tf.keras.layers.Dense(128, activation='relu')(x)
return tf.keras.layers.Dense(self.num_labels, activation='softmax', name=self.name_label_classifier)(x)
def domain_classifier(self, x):
# x = tf.keras.layers.Dense(128, activation='relu')(x)
return tf.keras.layers.Dense(self.num_domains, activation='softmax', name=self.name_domain_classifier)(x)
DANN 的使用案例 !!!
将上面两个模型复制到代码后, 可以如此调用. 首先需要一个特征提取网络, 并且属于 tf.keras.Model 对象. 如果你的模型并不是直接输出 feature 或想指定哪一层作为 feature 的输出, 则可以用第五行那样直接修改. keras 会自动追踪层间的计算关系. 剩下只需要给定标签个数和域的个数, 和梯度反转强度就行了.
如果想用自定义的域分类器和标签分类器, 则可以直接在上一节的两个 xxx_classifier 中自定义.
# Firstly, you should have a feature extraction model of tf.keras.Model, e.g., a tf.keras.applications.ResNet50 with `include_top=false`.
from .SE_ResNeXt_1DCNN import SEResNeXt
Model = SEResNeXt(...).SEResNeXt50() # A custom model to be specified by yourself
# If the model doesn't output a feature, several top layers have to be removed like:
modified_model = tf.keras.Model(inputs=Model.input, outputs=Model.get_layer(index=-2).output)
DANN = DomainAdversarialModel(feature_extractor=modified_model, num_labels=4, num_domains=3, lambda_=-0.8).get_model()
DANN.summary()
DANN.compile() # To be specified by yourself
data = tf.random.normal((1, ...)) # To be specified by yourself
print(DANN(data))
后记
如果无法复制则可以到 github中复制或下载. 另外, 根据李宏毅的视频里提到, 像 GAN 那样交替训练可能会性能更佳, 即先训练一下域分类器, 再训练特征提取网络和标签分类器.















 6306
6306











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









