







数据结构中有数组和链表来实现对数据的存储,但这两者基本上是两个极端。
数组
数组存储区间是连续的,占用内存严重,故空间复杂的很大。但数组的二分查找时间复杂度小,为O(1);数组的特点是:寻址容易,插入和删除困难;
链表
链表存储区间离散,占用内存比较宽松,故空间复杂度很小,但时间复杂度很大,达O(N)。链表的特点是:寻址困难,插入和删除容易。
哈希表
那么我们能不能综合两者的特性,做出一种寻址容易,插入删除也容易的数据结构?答案是肯定的,这就是我们要提起的哈希表。哈希表((Hash table)既满足了数据的查找方便,同时不占用太多的内容空间,使用也十分方便。
哈希表有多种不同的实现方法,我接下来解释的是最常用的一种方法—— 拉链法,我们可以理解为“链表的数组” ,如图:
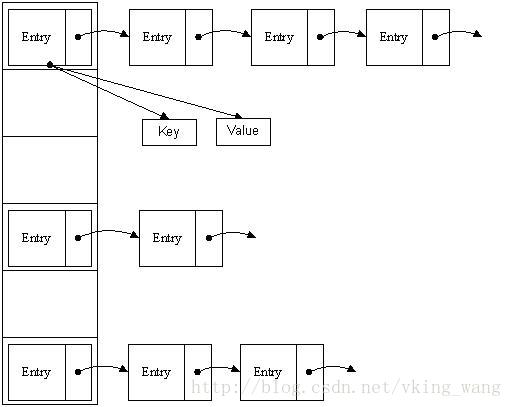
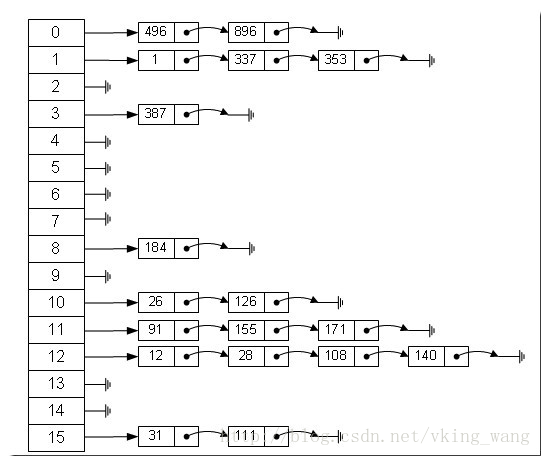
从上图我们可以发现哈希表是由数组+链表组成的,一个长度为16的数组中,每个元素存储的是一个链表的头结点。那么这些元素是按照什么样的规则存储到数组中呢。一般情况是通过hash(key)%len获得,也就是元素的key的哈希值对数组长度取模得到。比如上述哈希表中,12%16=12,28%16=12,108%16=12,140%16=12。所以12、28、108以及140都存储在数组下标为12的位置。
HashMap其实也是一个线性的数组实现的,所以可以理解为其存储数据的容器就是一个线性数组。这可能让我们很不解,一个线性的数组怎么实现按键值对来存取数据呢?这里HashMap有做一些处理。
首先HashMap里面实现一个静态内部类Entry,其重要的属性有key , value, next,从属性key,value我们就能很明显的看出来Entry就是HashMap键值对实现的一个基础bean,我们上面说到HashMap的基础就是一个线性数组,这个数组就是Entry[],Map里面的内容都保存在Entry[]里面。
1现在我们通过源码研究一下 HashMap中 put()方法的实现:
public V put(K key, V value) {
//首先判断key是否为空
if (key == null)
//这个方法的作用是如果key为空,则去map中已经存在的key中查找是否有为空的,如果有则将新的value赋值进去,如果没有则存入新的value
//具体代码看注1
return putForNullKey(value);
//根据key算出hash值
int hash = hash(key);
//根据hash值判断出再哈希表中应该处于哪个位置 i return h & (length-1); 通过按位与
int i = indexFor(hash, table.length);
//表里Entry
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
//如果hash值和key的值都相同 则说明key已经存在,于是就把新的value 存在 key中,并将旧的value返回
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
//如果key的hash值不重复或者key不相同,则调用下面方法, 此方法中实现了将key-value放进Entry中 具体代码 注2
addEntry(hash, key, value, i);
return null;
}
注1:
/**
* Offloaded version of put for null keys
*/
private V putForNullKey(V value) {
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(0, null, value, 0);
return null;
}
注2:
/**
* Adds a new entry with the specified key, value and hash code to
* the specified bucket. It is the responsibility of this
* method to resize the table if appropriate.
*
* Subclass overrides this to alter the behavior of put method.
*/
void addEntry(int hash, K key, V value, int bucketIndex) {
//如果table(Entry<K,V>[] table)中存在
if ((size >= threshold) && (null != table[bucketIndex])) {
//如果map的长度大于现有的值,将table的长度翻倍
resize(2 * table.length);
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
//在Entry中创建一个链表节点或者数组节点 代码如下
createEntry(hash, key, value, bucketIndex);
}
void createEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<>(hash, key, value, e);
size++;
}
总结: HashMap 将值放入map之前 首先进行key的值进行判断是否为空,如果为空则将之前的value覆盖
如果不为空,则计算key的hash值,然后判断key是否存在map中,如果存在则把旧的value覆盖,否则就通过addEntry()方法创建一个节点,
同时在创建的同时还会判断是否需要扩充map的大小,如果存在key的hash值相同,但是key不相同则将加入的key-value放入对应的数组节点下 如图1,2,
如果key的hash值和值都不想通则直接在数组的表头(即第一个,如果存在hash值相同,key值不相同则后被放在此表头的后面)。
















 907
907

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











