






论文名称:Generating Persona Consistent Dialogues by Exploiting Natural Language Inference
论文作者:宋皓宇,张伟男,胡景雯,刘挺
原创作者:宋皓宇
论文链接:https://arxiv.org/pdf/1911.05889.pdf
来自:哈工大SCIR
1. 简介
一致性问题是对话生成任务面临的主要挑战之一。高质量的对话不仅需要对输入作出自然的回复,而且还需要保持一致的角色特征。在这项工作中,我们利用了自然语言推理技术建模了人物角色的一致性问题。不同于已有的基于重排序的工作,我们把该项任务建模为强化学习问题,并利用自然语言推理技术信号优化对话生成模型。具体来说,我们的生成模型使用了基于注意力机制的编码器-解码器来生成基于角色文本的回复。另一方面,我们的评估器由两部分组成:一个由对抗训练方法训练得到的自然度模块和一个基于自然语言推理技术的一致性模块。此外,我们引入了另一个性能良好的自然语言推理技术模型来客观评价生成回复的角色一致性。我们进行了定性和定量的实验。在公开数据集上的结果表明我们的方法优于基线模型,尤其是在生成回复的角色一致性方面。
2. 动机
虽然最近几年通过利用社交网络上大量人人交互数据训练开放域对话模型取得了很大的成功[1],但是这些数据驱动的对话系统仍然无法很自然的与人类对话,其中的一个主要问题就是对话系统缺乏一致的角色特征[2]。图1中的例子展示了角色一致性是如何影响对话的质量。提高对话系统角色一致性的一个实用方法是明确定义一组描述对话系统角色信息(persona)的描述性文本,并以此为基础学习生成体现出预先定义角色信息的回复[3]。尽管编码器-解码器框架在基于角色信息的对话生成模型中得到了成功的应用,但存在的问题是这些生成模型普遍缺乏对于一致性信息的建模。

图1 一致性对于回复质量的影响
另一方面,近几年自然语言推理技术(Natural Language Inference)相关技术有了长足的进步。有研究工作表明,回复和角色文本的一致性检测问题可以被建模为<角色信息,回复>之间的自然语言推理技术问题[4]。如何在基于角色信息的对话生成模型中利用这种检测方法建模并提高角色的一致性是一个值得探索的问题。
在生成模型中结合基于自然语言推理技术方式的对话一致性建模,一种很自然的思路就是通过强化学习的方式来优化训练目标。另一方面,我们也考虑到自然语言推理技术模型本身仅仅给出了一致或者矛盾的推断,无法考虑回复的流畅度和相关度等重要指标。如果仅仅通过强化学习的方式进行训练很有可能会导致回复质量显著降低。因此,我们同时引入了对抗训练的方式来保障回复的质量。
3. 模型
3.1 任务定义
我们的目标是学习一个生成模型G以生成角色信息一致的对话。形式化定义如下:给定输入 X ,角色信息的集合 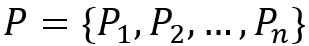 ,目标是生成一个回复
,目标是生成一个回复 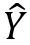 ,即
,即 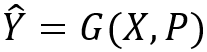 。此外,我们有一个自然语言推理技术模型 NLI ,生成的回复需要满足
。此外,我们有一个自然语言推理技术模型 NLI ,生成的回复需要满足 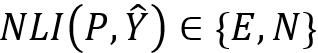 ,其中表示一致,N 表示中立。
,其中表示一致,N 表示中立。
3.2 方法
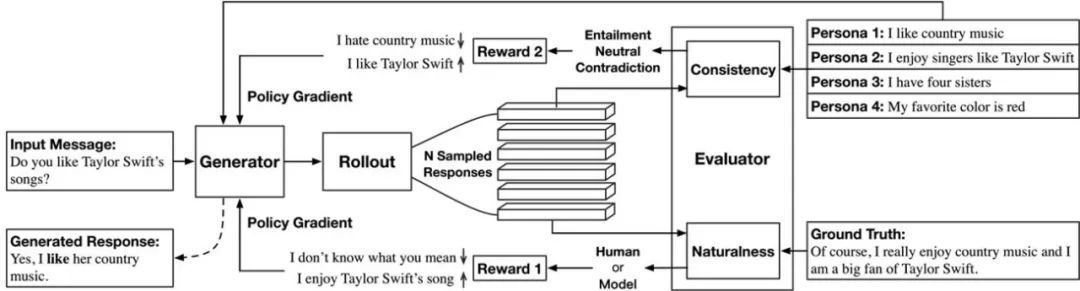
图2 模型总体结构图
如图2所示,我们所提出的一致性对话生成框架由两部分组成:一个序列生成器G(Generator)和一个评估器(Evaluator)E。其中,评估器E由两个子模块组成,分别是一致性检测模块(一致,中立,矛盾)和自然度检测模块(自然,不自然)。在本文的任务重,一个理想的回复应该是看起来很自然并且与给定的角色信息保持一致的,即:
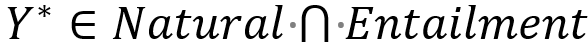
方法的关键在于引导模型生成满足上式的回复,为此我们选择了使用策略梯度(policy gradient)的方法来训练生成器。有一点需要强调的是,我们的评估器使用了两个独立的子模块,而不是一个联合训练的模型。这是因为“自然度”这个属性是体现在训练数据之中的:我们始终可以认为训练数据中的回复要比模型生成的回复更加自然。因此,在训练的过程中我们也能够源源不断的获得对自然度模块进行训练的正负例。相反,一致性是没有体现在训练数据的回复中的。我们后续的实验表明,在训练数据中,大部分的回复是处于与角色信息中立的状态。我们无法在训练过程中动态的获得新的训练数据来更新一致性检测模型。
自然度模块  是一个二分类器,用于判断给定的回复来自模型生成还是训练数据。我们把输入的回复通过双向GRU编码为向量表示,然后通过多层感知器网络及SoftMax函数输出二分类概率。 的训练目标是最小化预测结果和真实标签之间的交叉熵损失。来自 的奖励 定义
是一个二分类器,用于判断给定的回复来自模型生成还是训练数据。我们把输入的回复通过双向GRU编码为向量表示,然后通过多层感知器网络及SoftMax函数输出二分类概率。 的训练目标是最小化预测结果和真实标签之间的交叉熵损失。来自 的奖励 定义  为 将给定回复预测为来自训练数据的概率。
为 将给定回复预测为来自训练数据的概率。
一致性模块 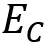 是一个NLI的分类器。 被训练来预测<角色信息,回复>之间的一致性关系,共有一致,中立和矛盾三种情况。由于我们首次尝试使用该方法来建模一致性,为了更好的探索自然语言推理技术模型对于提高回复一致性的帮助作用,我们这里使用了2个效果有明显差别的自然语言推理技术模型,Base模型和BERT模型,以观察对最终效果的影响。其中,Base模型为GRU+Interaction+MLP的典型NLI模型;BERT模型实在BERT_base的基础上进一步微调得到的。最终,来自一致性模块 的奖励定义为:
是一个NLI的分类器。 被训练来预测<角色信息,回复>之间的一致性关系,共有一致,中立和矛盾三种情况。由于我们首次尝试使用该方法来建模一致性,为了更好的探索自然语言推理技术模型对于提高回复一致性的帮助作用,我们这里使用了2个效果有明显差别的自然语言推理技术模型,Base模型和BERT模型,以观察对最终效果的影响。其中,Base模型为GRU+Interaction+MLP的典型NLI模型;BERT模型实在BERT_base的基础上进一步微调得到的。最终,来自一致性模块 的奖励定义为:
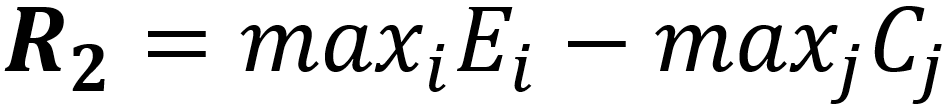
E 是回复与角色信息一致的置信度,C 是回复与角色信息矛盾的置信度。通过该奖励函数,我们希望鼓励模型尽可能生成一致的回复并减少不一致回复的生成。
生成器 G 是一个用GRU作为基本单元,使用Seq2Seq的结构的生成模型。角色信息文本作为了输入的一部分[3]。此外,在生成过程中的每一步都使用了展开(rollout)的方式来获取对于当前位置更为精确的奖励估计。强化学习和对抗训练的算法流程和更多细节请参考论文第4页。最后用于优化 G 的奖励函数为:
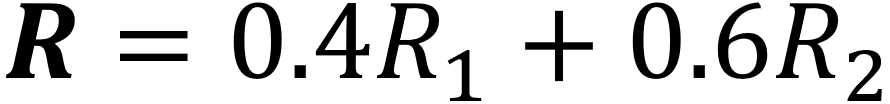
4. 实验结果
我们在公开的PersonaChat数据集上进行了实验。实验评价主要考虑两个方面:
回复的一致性。考虑到有限样本的情况下人工标注难以得到足够的一致类别的样本,我们主要使用自然语言推理技术模型DIIN对生成的回复进行分类。结果如表1所示。其中,我们的方法缩写为RCDG,即Reinforcement Learning based Consistent Dialogue Generation。Entail.表示回复与角色信息一致的比例,值越高越好;Contr.表示回复与角色信息相矛盾的比例,值越低越好。同时,我们也给出了测试数据的相关比例。可以发现,PersonaChat中并非所有对话都与角色信息相关。此外,我们也的确在数据集中发现了极个别存在的矛盾回复。
回复的质量。对回复质量的评价按照惯例进行,包括了客观指标(表2)和主观评价(表3)两部分。客观指标包括衡量流畅性的困惑度(ppl),衡量语义相似度的embedding metrics(Ave., Grd., Ext.)以及衡量多样性的Distinct-2(Dst.)。主观评价使用了0-2的总体质量打分方式。
表1 角色一致性评价结果
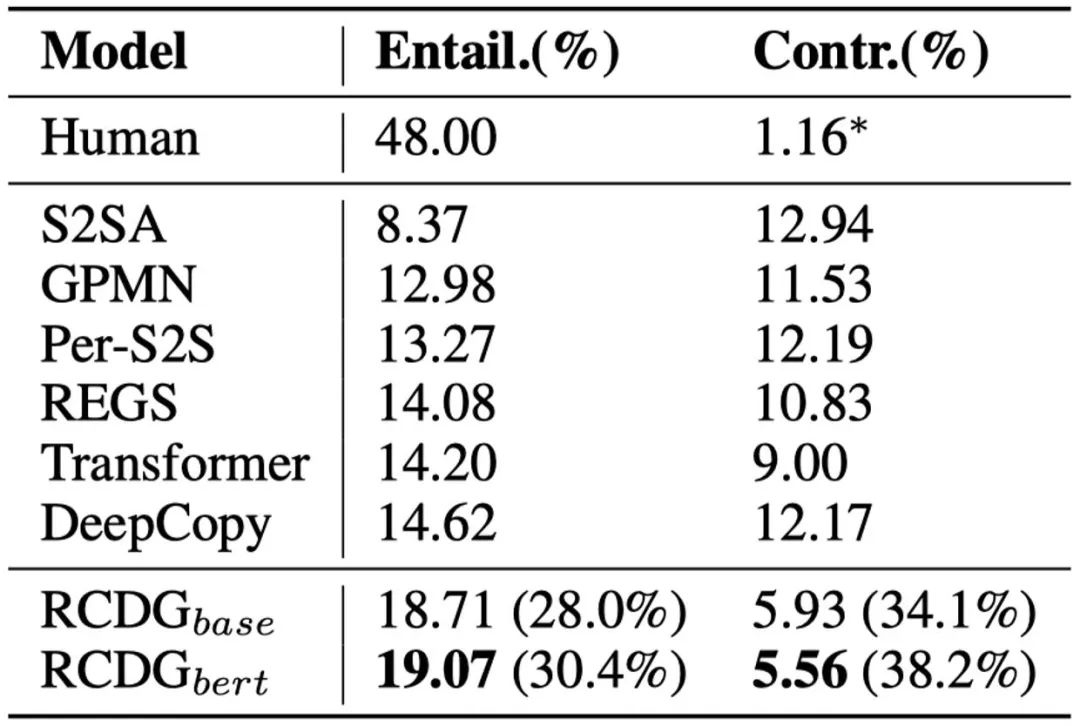
表2 对话质量自动指标结果
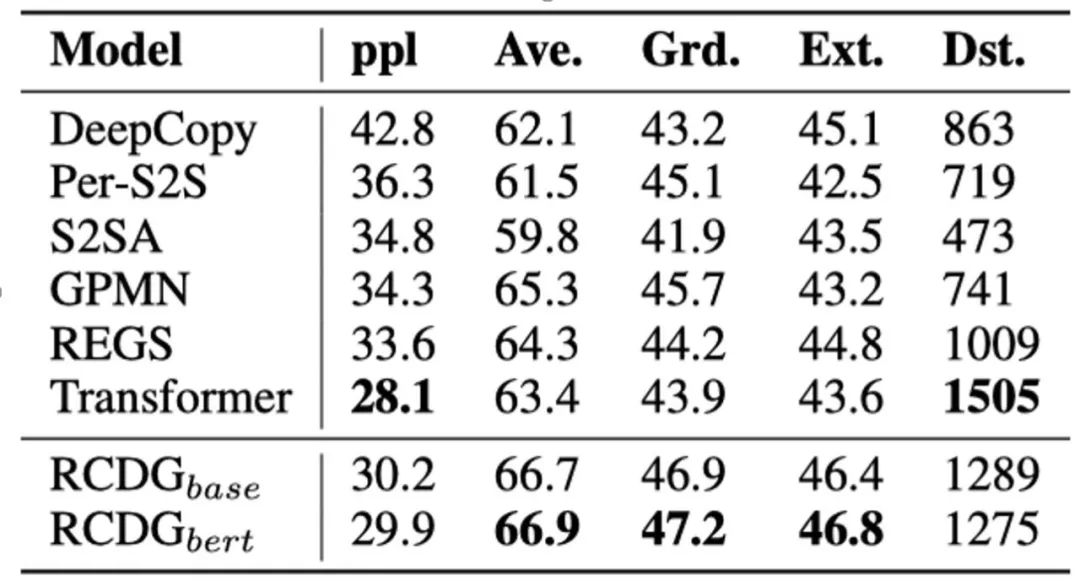
表3 对话质量人工评价结果
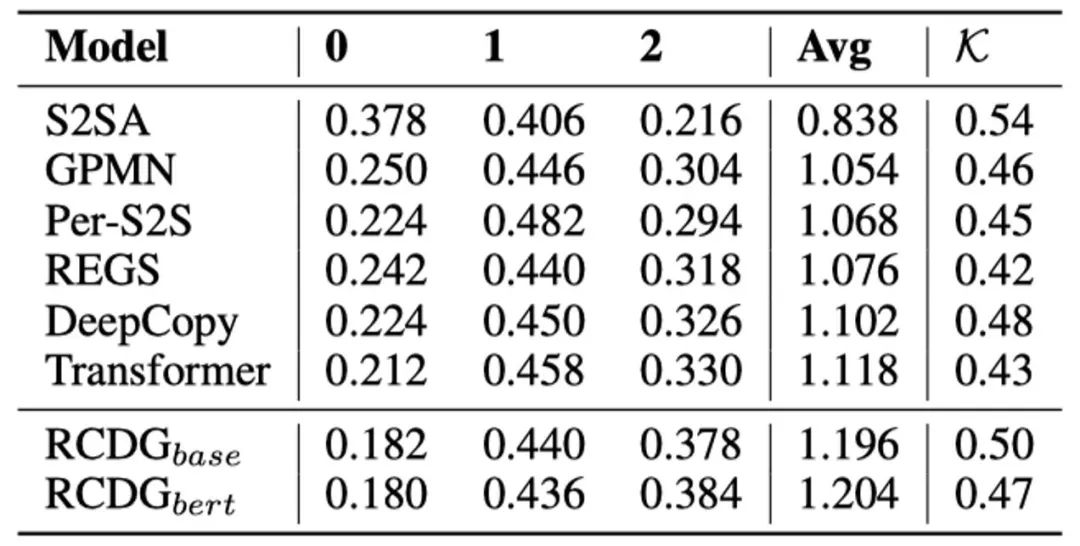
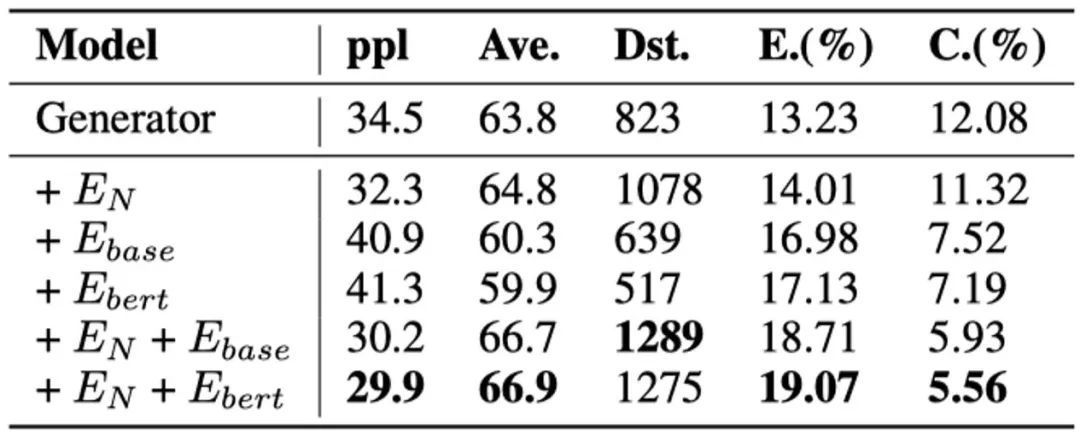
此外,我们还进行了消解实验,以分析每一个子模块的作用。结果如表4所示。
表4 消解实验结果
5. 总结
在该项工作中,我们探索了利用自然语言推理技术来建模开放域对话生成中人物角色一致性的问题。为此,我们将该任务转化为一个强化学习问题,并在生成模型中利用自然语言推理技术信号提高回复的一致性。通过在PersonaChat数据集上的实验,我们证明了我们的方法相比于基线模型获得了有效提升。
参考文献
[1] Shang, L.; Lu, Z.; and Li, H. 2015. Neural responding machine for short-text conversation. arXiv:1503.02364.
[2] Jiwei Li, Michel Galley, Chris Brockett, Georgios Spithourakis,Jianfeng Gao, and Bill Dolan. A persona-based neural conversation model. ACL, 2016.
[3] Zhang, S.; Dinan, E.; Urbanek, J.; Szlam, A.; Kiela, D.; and Weston, J. Personalizing dialogue agents: I have a dog, do you have petstoo? ACL, 2018.
[4] Welleck, S.; Weston, J.; Szlam, A.; and Cho, K. Dialogue natural language inference. ACL, 2019.
本期责任编辑:张伟男
本期编辑:王若珂
交流学习,进群备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。
广告商、博主勿入!




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









