






LLM解题的痛点:会做题,但不会检查
现在的大模型解题能力越来越强,甚至能搞定奥数题,但“做完题不会检查”成了致命短板。 比如,解完题后,可能因为中间某步计算错误而给出错误答案,但它自己却无法发现。
论文:Heimdall: test-time scaling on the generative verification
链接:https://arxiv.org/pdf/2504.10337
论文提到,当前顶级模型如GPT-4的直接验证准确率仅62.5% ,相当于考试时做完题随便蒙答案——显然不够可靠。
人类启示:爱因斯坦提出相对论前,通过验证光速不变悖论修正了经典物理理论。验证能力是知识创新的核心,LLM也需要这样的能力。
Heimdall:LLM界的“质检员”
Heimdall(名字源自北欧神话中能洞察万物的守护神)是一个专为验证而生的模型。 它的核心能力是通过长链思维推理(Chain-of-Thought, CoT),像人类一样逐步检查解题过程的每一步。
关键突破:
用强化学习训练,让LLM学会“自我纠错”;
验证准确率从62.5%提升到94.5% ,多次采样后达到97.5% ;
甚至能发现训练中从未见过的数学证明题错误。
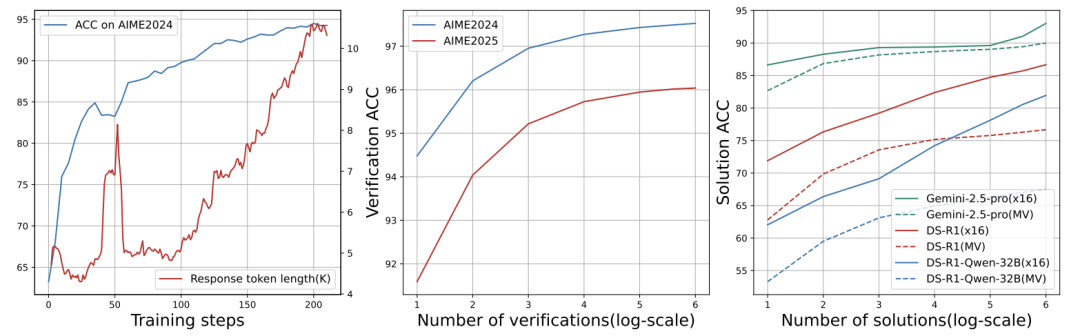
技术细节
训练方法:
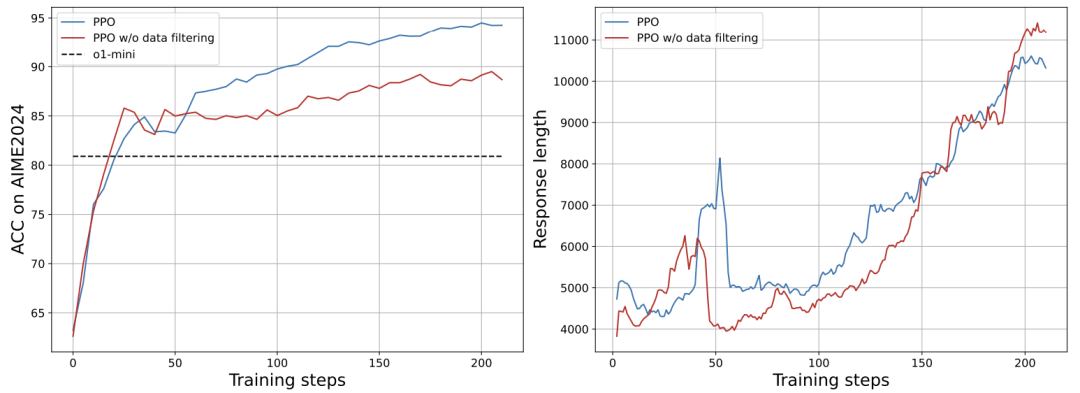
强化学习框架:用PPO算法(类似教模型“对答案给奖励,错答案扣分”);
数据过滤:剔除两类题目——
太简单(所有解法都对);
太难(所有解法都错)。
就像老师布置作业时,避免全是“1+1”或“哥德巴赫猜想”,否则学生学不到真正的判断能力。
推理优化:
多次采样+投票:让模型对同一题多次验证,取多数结果(类似多人会诊);
悲观验证算法:优先选择“最确定正确”的答案,避免被错误答案带偏。
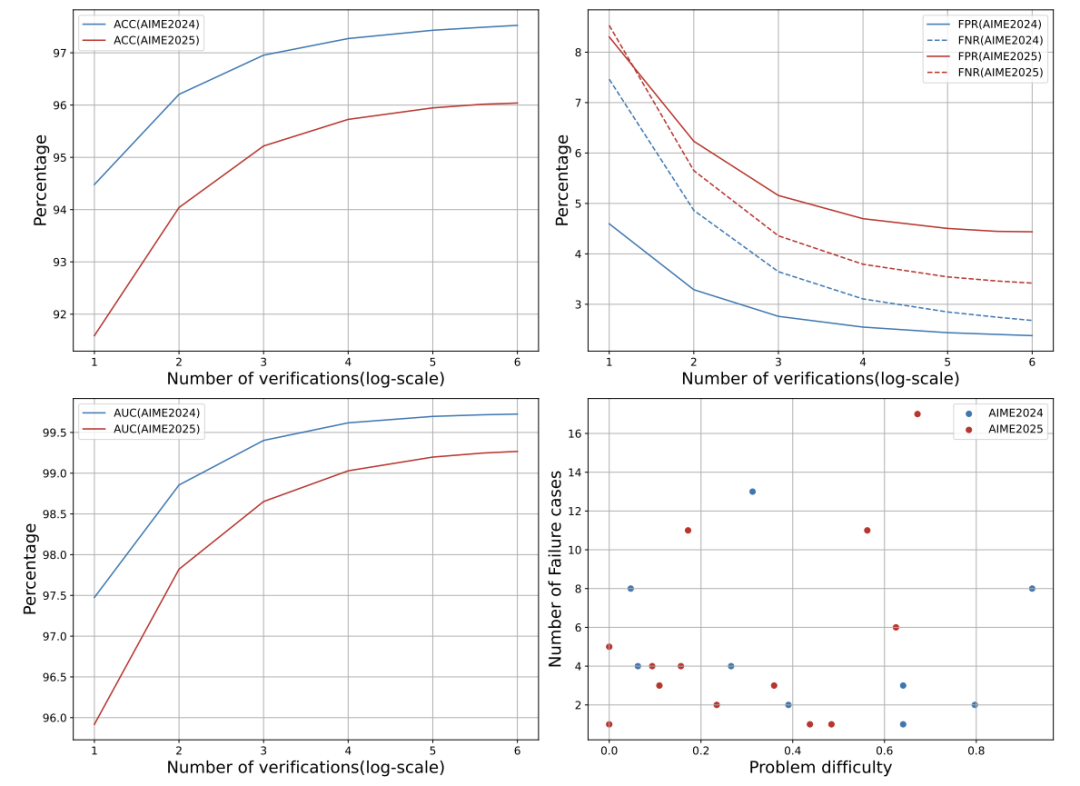
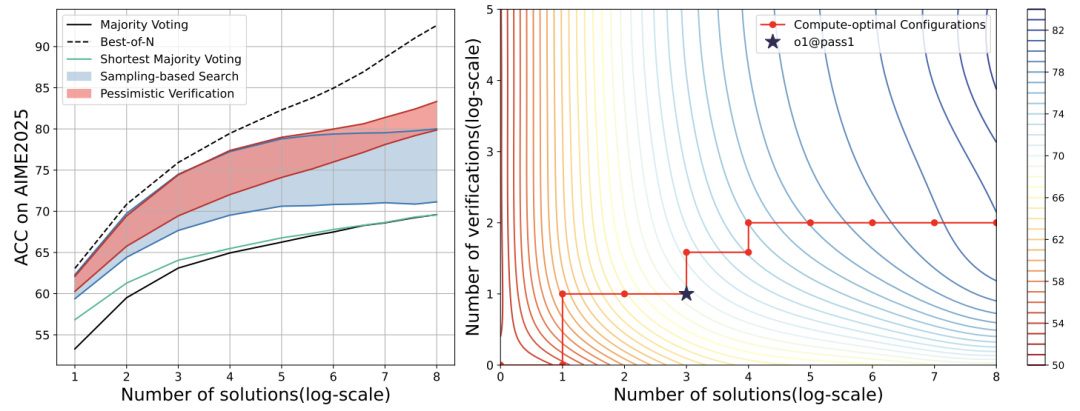
效果炸裂:准确率从62.5%飙升至97.5%
在AIME数学竞赛题测试中:
单次验证准确率94.5% ,64次采样后达到97.5% ;
结合解题模型(如Gemini 2.5 Pro),整体解题准确率从54%提升到93% ,接近人类顶尖水平。
算法对比:
传统“多数投票”准确率仅70%;
悲观验证算法通过平衡“解题偏好”和“验证信号”,显著优于其他方法。
跨界应用:数学证明、数据质检都能行
数学证明题
Heimdall能发现证明过程中的逻辑漏洞,例如:
某步骤假设未经验证;
结论正确但推导错误(类似“蒙对答案但过程瞎写”)。

数据质检
在合成数据集NuminaMath中,Heimdall发现近一半数据有缺陷(如题目无解或解法错误)。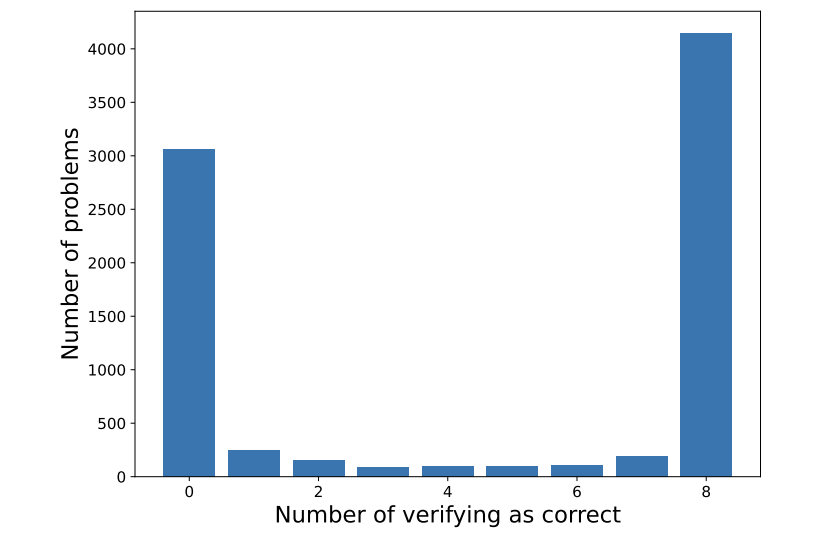
这相当于帮公司省去了人工筛查海量数据的成本。
当前局限
对空间推理类问题(如几何)表现较弱;
需要更多领域数据(如编程、物理)进一步训练。
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









