







点击下面卡片,关注我呀,每天给你送来AI技术干货!
来自:哈工大讯飞联合实验室
本期导读:篇章要素(Discourse Element)是指篇章单元在一篇文章中的作用和贡献。在篇章结构评分任务中,使用篇章要素来表示篇章结构是一种有效的表示方法。本文通过两篇发表于EMNLP 2020和IJCAI 2020的论文,分别介绍篇章要素识别和基于篇章要素识别的篇章结构评分的研究工作。
•••
Discourse Self-Attention for Discourse Element Identification in Argumentative Student Essays
论文作者:宋巍,宋子尧,付瑞吉,刘丽珍,程苗苗,刘挺
论文地址:https://www.aclweb.org/anthology/2020.emnlp-main.225.pdf
项目地址:https://github.com/cnunlp/Discourse-Self-Attention-For-Discourse-Element-Identification
引言
篇章要素(Discourse Element)表示每一个篇章单元对于整个篇章的功能和贡献。篇章要素识别(Discourse Element Identification,DEI)任务主要是识别篇章要素单元(Discourse Element Unit, DEU)并对其进行分类。篇章要素单元既可以是短文本,如一个句子或子句;也可以是长文本,如一个段落。在议论文中篇章要素通常可以分为七类:引论(Introduction)、中心论点(Thesis)、分论点(Main Idea)、事实论据(Evidence)、理论论据(Elaboration)、结论(Conclusion)和其他(Other)。篇章要素识别可以在多个方面辅助作文自动评分,例如作文结构建模、主题和观点识别和作为评分系统的特征。本文主要针对句子级篇章要素进行研究。

动机
篇章要素识别目前仍面临一些挑战:
首先,一些句子的多意性和模糊性使得一些篇章要素模型很难学到他们的区别。
第二,一些特殊的句子级篇章要素依赖于上下文内容。
第三,篇章要素识别任务的数据不平衡问题非常严重。
受Transformer中自注意力机制的启发,本文从以下两个方面来增强议论文篇章要素的识别能力:
使用基于自注意力机制的句子间关系能够表示句子间的相关性。 句子间的相关性能够帮助识别数量少且与其他句子具有不同关系模式的句子的篇章要素。自注意力机制通过计算得到的每一个句对之间的注意力权重,也是这两个句子间相关性的一种表示。采用自注意力机制中的注意力向量来表示句子之间的关系,不仅可以获得句子间的关系模式,还能弥补距离较远的句子的依赖问题。
句子位置信息为篇章要素识别提供了非常重要的信息。 因为议论文作文写作往往会使用一些常用的结构来组织,所以位置信息是与篇章要素文本的内容和风格不相关的。受到词的位置信息编码的启发,提出了一种简单的句子结构位置信息编码策略。
模型
本文采用层次双向LSTM模型(HBiLSTM)作为基础模型。在这个模型中使用两个不同层次的Bi-LSTM模型,分别得到句子内容表示C和篇章要素表示D。最后使用每个句子对应的篇章要素表示D进行分类。
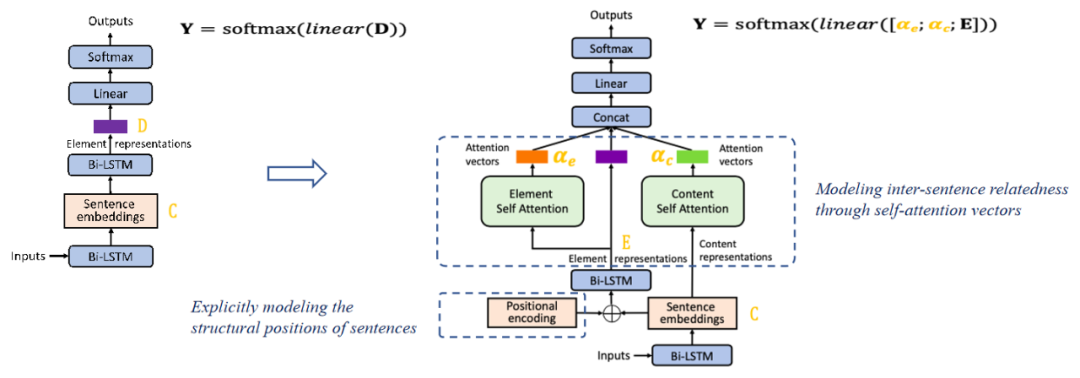
句子位置编码(SPE)。为了构建结构化的位置信息,定义了三种类型的位置信息用于位置编码:
全局位置(Global position):句子在全文中的位置。将作文看作句子序列,一个句子在序列中的索引即为该句子的全局位置。
段落位置(Paragraph position):句子所属段落在全文中的位置。句子所属段落的位置也是非常重要。
段内位置(Local position):句子在段落内的位置。句子在段落内的位置也能提供很多的信息。
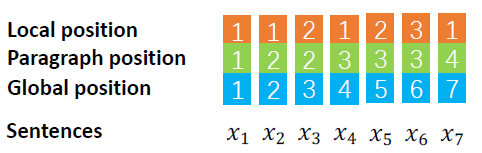
本文使用了一种简单的相对位置编码(Relative SPE) 方法。这种编码方式主要考虑句子相对于整体的位置。计算时使用句子位置索引除以整体的句子序列长度。然后通过将编码后的三种句子位置加权求和得到最终的句子位置编码pos。
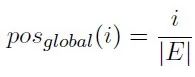
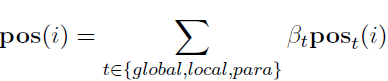
通过直接将句子位置编码pos加到句子表示c上得到新的句子表示,将其输入BiLSTM得到新的篇章要素表示e。
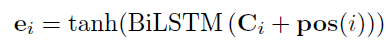
句子间注意力向量(ISA)。通过计算每一个句对之间的注意力,就可以得到句子间的关系。相较于通常的注意力机制方法,本文发现直接只用注意力向量特征能够获得更好的效果。

由于不同的文章的句子的数量不同,因此得到的句子间注意力向量的维度也是不同的。为了得到一个固定长度的注意力向量特征表示,本文使用“空间金字塔池化”(Spatial Pyramid Pooling,SPP)方法来提取表示。SPP是为了解决图像的目标检测任务中不同的目标块大小不一样的问题提出的,使用多个输出大小不同的自适应池化层将不同维度的矩阵或序列转化为固定大小的矩阵和序列。
最终,将篇章要素表示E和内容级与篇章要素级的句子间注意力向量进行拼接,并进行预测。

实验
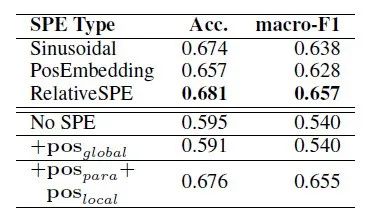
实验表明,位置信息能够有效地提升篇章要素的识别效果。其中,相对位置信息编码方式更加有效。编码段落位置信息和段内位置信息能够大幅提高模型的识别效果。这说明合适的结构化位置信息编码比序列化位置信息编码能够更好地识别具有结构化特性的篇章要素。
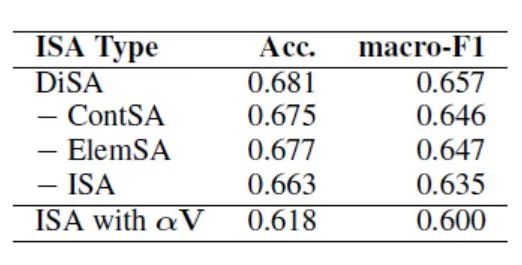
由实验结果可以看出,与不使用句子间注意力向量比较,句子内容间注意力向量和句子篇章要素间注意力向量都对模型的识别效果提升有很大贡献。句子间注意力向量对数量少的中心论点有很大的提升,并且对于数量并不少的事实论据的识别效果也有很大的提升。中心论点句总是和文章中其他的区域的句子有很大的相关性;而事实论据只是列举事例等,仅与前后位置的句子相关。
结论
尽管相对位置编码方法很简单,但是能够大幅地提高模型对篇章要素的识别能力,说明结构化的位置信息对分析句子级篇章要素是有用且重要的;
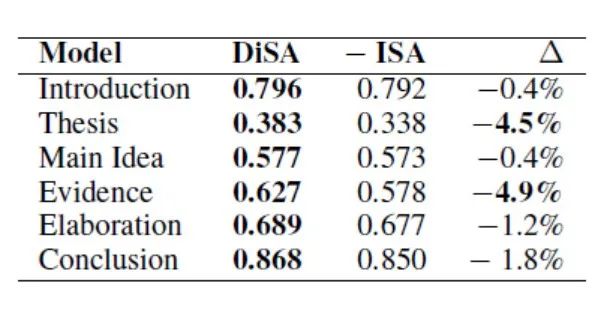
句子间注意力向量可以帮助模型更好地识别篇章要素,特别是数量少的和与其他句子具有不同关系模式的句子。
参考文献
[1] Song W, Liu L Z. Representation learning in discourse parsing: A survey[J]. Science China Technological Sciences, 2020: 1-26.
[2] Yang Z, Yang D, Dyer C, et al. Hierarchical attention networks for document classification[C]//Proceedings of the 2016 conference of the North American chapter of the association for computational linguistics: human language technologies. 2016: 1480-1489.
[3] Stab C, Gurevych I. Parsing argumentation structures in persuasive essays[J]. Computational Linguistics, 2017, 43(3): 619-659.
[4] Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[C]//Proceedings of the 31st International Conference on Neural Information Processing Systems. 2017: 6000-6010.
[5] He K, Zhang X, Ren S, et al. Spatial pyramid pooling in deep convolutional networks for visual recognition[J]. IEEE transactions on pattern analysis and machine intelligence, 2015, 37(9): 1904-1916.
原文:宋子尧
编辑:HFL编辑部
说个正事哈
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方“深度学习自然语言处理”,进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心 。
。
投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注呦
点击上面卡片,关注我呀,每天推送AI技术干货~
整理不易,还望给个在看!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









