






为什么需要新的视觉推理测评标准?
当前的多模态大模型(如GPT-4o、Gemini)看似能“看图说话”,但论文揭露了一个残酷真相:它们可能只是在玩“文字游戏”!现有测评标准存在重大漏洞——允许模型先把图像转文字描述,再通过纯语言推理解题。
更扎心的是实验数据:人类在这套新标准下的正确率是51.4%,而所有测试模型无一超过30%,甚至不如闭眼蒙答案(25%随机正确率)。这说明模型的“视觉思考”能力还停留在幼儿园水平。

论文:VisuLogic: A Benchmark for Evaluating Visual Reasoning in Multi-modal Large Language Models
链接:https://arxiv.org/pdf/2504.15279
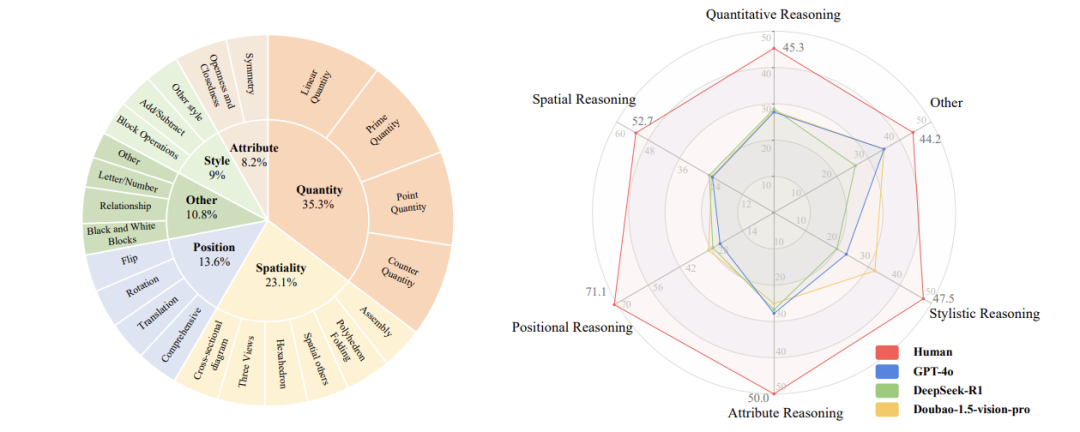
VisuLogic的独特设计
为了堵住作弊漏洞,研究者精心设计了1000道“看图说话也无法破解”的考题,分为六大类:
数量推理:数清图形元素变化
空间推理:3D图形折叠展开
方位推理:平移旋转找规律
属性推理:对称性、曲率等本质特征
风格推理:叠加、裁剪等抽象变化
其他类别:字母符号等特殊题型
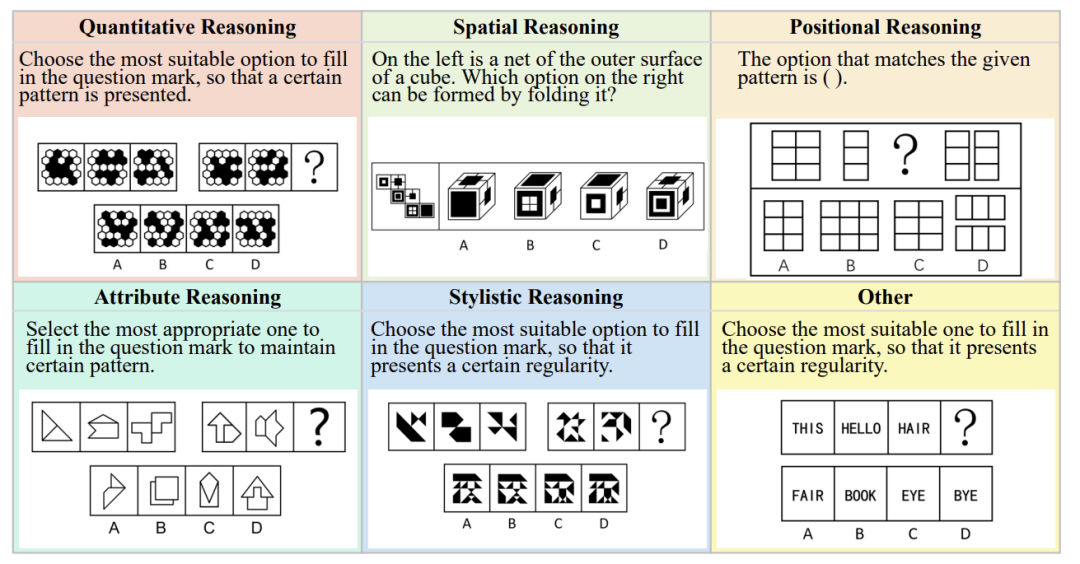
这些题目刻意设计成“难以用文字准确描述”。例如一道对称性推理题,标准答案需要观察图形旋转规律,但若用文字描述,关键细节极易丢失(比如“黑色方块每次顺时针移动1格”可能被简化为“图形有移动”),导致纯文字模型根本无法解题。
实验结果:惨遭碾压
测试结果堪称大型翻车现场:
纯文字模型(如Claude-3.7):成绩≈随机蒙题
多模态顶流(GPT-4o、Gemini):最高仅28.1%
开源模型(如InternVL3-78B):27.7%紧追闭源模型
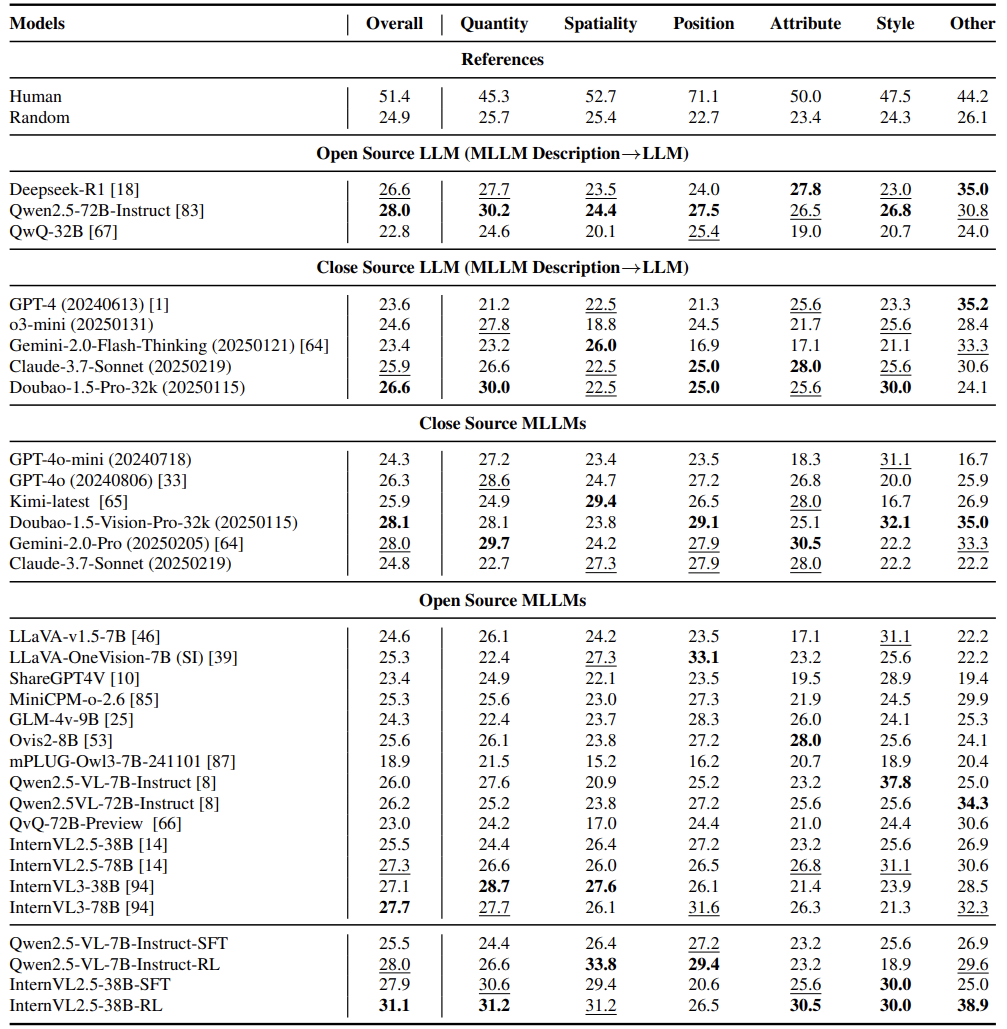
最惨烈的是风格推理题,AI错误率超75%,比蒙答案还差。这说明当前模型对图形叠加、轮廓变化等抽象特征几乎“眼盲”。反观人类,在方位推理题上错误率低于30%,展现真正的空间想象力。
破局关键:强化学习显神威
研究团队发现一条突围路径——强化学习(RL)。用配套训练数据微调模型后:
Qwen2.5-VL-7B模型:成绩从25.5%→28%
InternVL2.5-38B模型:从25.5%→31.1%

更重要的是,团队开源了所有代码、数据和训练方法。这意味着全球开发者都能参与改进,就像给AI界发起了一场“视觉推理奥林匹克竞赛”。
未来启示录
这项研究揭示了两大趋势:
多模态AI需“脱虚向实”:当前模型过度依赖语言能力,真正的视觉理解仍是短板
强化学习或成关键钥匙:通过针对性训练,AI可能突破“看山是山”的初级阶段
对普通人而言,更强大的视觉推理AI将带来:
更精准的医学影像分析
更流畅的AR/VR交互
更智能的自动驾驶决策
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









