







RL is All You Need for Agent while OTC-PO is All You Need for Agentic RL
Agent 即一系列自动化帮助人类完成具体任务的智能体或者智能助手,可以自主进行推理,与环境进行交互并获取环境以及人类反馈,从而最终完成给定的任务,比如最近爆火的Manus以及OpenAI的o3等一系列模型和框架。强化学习 (Reinforcement Learning) 被认为是当下最具想象力,最适合用于Agent自主学习的算法。其通过定义好一个奖励函数,让模型在解决任务的过程中不断获取反馈即不同的奖励信号,然后不断地探索试错,找到一个能够最大化获取奖励的策略或者行为模式。
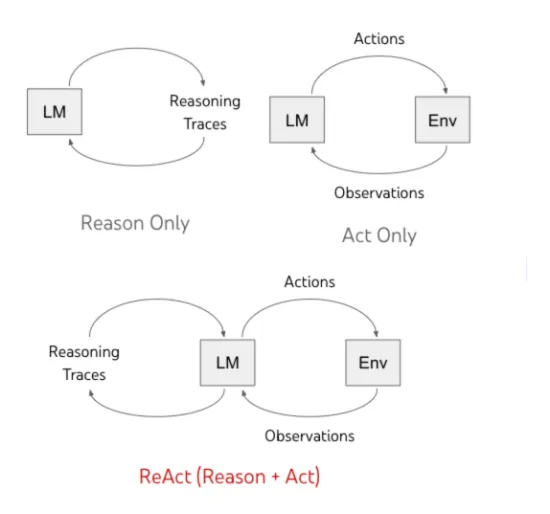
为了实现OpenAI推出的o3这样的表现,我们就必须先要了解Agent最重要的行为模式。Agent最重要的两种行为主要分为推理(i.e., Reasoning)和行动(i.e., Acting)两种,前者专注模型本身的推理行为,比如反思,分解等各种深度思考技巧;后者专注模型与环境的交互,比如模型需要调用不同的工具,API以及其他模型来获取必要的中间结果。Open-o1,DeepSeek-R1以及QwQ 等大推理模型通过设计一些基于规则的奖励函数,仅仅从最终答案的正确与否就可以通过RL激发出来大模型强大的 Reasoning 模式,比如System 2 thinking,从而在代码,数学等任务上取得了惊人的效果。近期一系列工作试图在Agent的Acting模式复刻大推理模型的成功,比如Search-R1,ToRL,ReTool等等,但是几乎所有的工作依旧沿用之前的大推理模型时代的奖励函数,即根据最后答案的正确与否来给于Agent不同的奖励信号。
这样会带来很多过度优化问题,就像OpenAI在其博客中指出的那样,模型会出现Reasoning和Acting行为模式的混乱。因为模型仅仅只关注最后的答案正确,其可能会在中间过程中不使用或者过度使用推理或者行动这两种行为。这里面存在一个认知卸载现象,比如模型就会过度的依赖外部的工具,从而不进行推理,这样一方面模型之前预训练积累的能力就极大地浪费了,另外也会出现非常愚蠢的使用工具的情况,举个例子就是我们俗称的遇事不思考老是问老师或者直接抄答案。我们这里可以针对Agent的这两种不同的行为: Reasoning 和 Acting 设想几种不同的奖励函数,或者说我们期望模型表现出来一种什么样的模式。
Maximize Reasoning and Acting, 即我们期望模型能够使用越多的reasoning和acting来解决问题,会导致效率以及过度优化问题。
Minimize Reasoning and Acting,即我们期望模型能够使用越少的reasoning和acting来解决问题,训练难度较大,可能会导致效果不佳。
Maximize Acting and Minimize Reasoning: 这会导致模型极大的浪费本身就很强的reasoning能力,反复的愚蠢的去和外部世界交互。
Maximize Reasoning and Minimize Acting: 即OpenAI o3目前表现出来的行为,o3只会在超过自己能力之外的问题下才会去和外部世界交互,大部分的问题都使用自己的推理能力进行解决了。
这其中最有潜力或者最有可能的技术路线就是第2和第4个方向,而在这两个方向里唯一的一个共同点就是要不断要求模型去Minimize Acting,那我们最新推出的OTC: Optimal Tool Call via Reinforcement Learning (OTC-PO) 其实就是朝着这个方向走出的根本性的一步。
直播预约~ 本周末我们会通过两篇工作分享:如何让大语言模型通过强化学习又好又准地使用工具?ToolRL 解决的是通过强化学习教会模型如何使用工具(如何“好”);OTC-PO 则进一步解决教会模型如何少用、精用工具(如何“准”)。

Arxiv: https://arxiv.org/pdf/2504.14870
Huggingface: https://huggingface.co/papers/2504.14870
本文的核心贡献在于以下三点:
我们是第一个 i) 关注大模型工具使用行为优化的RL算法;ii) 发现并量化认知卸载现象,且模型越大,认知卸载越严重,即模型过于依赖外部工具而不自己思考;iii) 提出工具生产力概念,兼顾收益与成本;
我们提出OTC-PO,任何RL算法皆可使用,代码修改仅几行,简单,通用,可扩展,可泛化,可以应用到几乎所有工具使用的场景,最大化保持准确率的同时让你的训练又快又好,模型即聪明又高效。
我们的方法在不损失准确率的前提下,工具调用减少 73.1%,工具效率提升 229.4%,训练时间大幅缩小,且模型越大,效果越好。
具体来说,给定任意一个问题和任意一个模型,我们假设存在一个最优的Acting次数,即最少的工具调用次数,来使得模型能够去回答对这个问题。需要注意的是这里面最少的工具调用次数是由模型和问题共同决定的,因为不同的模型有着不同的能力,不同的问题也有着不同的难度,这样就是每一个问题和每一个模型其实都有着独特的最小所需工具次数,并且这个最少的工具调用次数可以为0即退化为传统的language-only reasoning。也正是因为这样的性质,导致之前的SFT方案无法直接作用在这样的场景里面,因为SFT基本都是使用一个数据集去拟合所有模型的行为。RL就天然的提供了这样的一个解决方案,使得不同的模型都可以在自己的交互过程中去学习到对应的最佳的行为模式,而不仅仅是通过SFT去模仿一个次优解。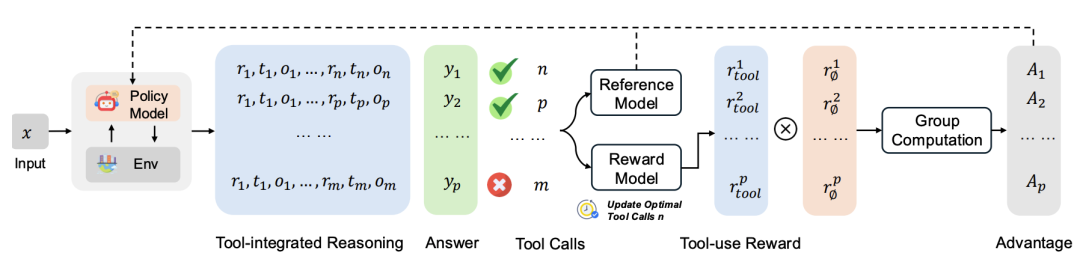 那这个任务就可以被重新定义成如下这样的形式,给定一个问题q,一个模型M以及一堆工具t0, t1, …, tn,我们喜欢模型M能够即快又好的回答问题,其在第k步的推理过程可以被定义成:
那这个任务就可以被重新定义成如下这样的形式,给定一个问题q,一个模型M以及一堆工具t0, t1, …, tn,我们喜欢模型M能够即快又好的回答问题,其在第k步的推理过程可以被定义成: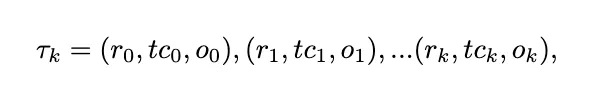 其中ri, tci, oi 分别代表模型的内部推理过程,工具调用,以及环境反馈。需要注意的时候这样的定义可以泛化到不使用任何工具调用的情况即tci和oi为空字符串。整体的任务就变成了我们需要要求模型不仅答对,还要以一种高效的方式答对,即
其中ri, tci, oi 分别代表模型的内部推理过程,工具调用,以及环境反馈。需要注意的时候这样的定义可以泛化到不使用任何工具调用的情况即tci和oi为空字符串。整体的任务就变成了我们需要要求模型不仅答对,还要以一种高效的方式答对,即 这里a^\hat代表了该问题的正确答案,我们希望模型答对的前提下,能够去最小化达到这个目标的成本,比如token的消耗,tool的调用。这样的任务定义不仅仅是简单的扩充,而是对目前Agent RL的一次范式纠偏,使得大家不仅仅关注最终的答案是否正确,还需要关注模型在这个过程中表现的行为。
这里a^\hat代表了该问题的正确答案,我们希望模型答对的前提下,能够去最小化达到这个目标的成本,比如token的消耗,tool的调用。这样的任务定义不仅仅是简单的扩充,而是对目前Agent RL的一次范式纠偏,使得大家不仅仅关注最终的答案是否正确,还需要关注模型在这个过程中表现的行为。
这里最核心的思路是根据模型在当下这个交互行为中工具的调用次数 m 以及 最优的工具调用次数 n 去给于模型不同的奖励函数。具体来说,在答对的情况下,我们希望模型在取得最优工具调用的时候能够获取最大的奖励,在使用了更多的工具调用的时候奖励是相对小一点的;在答错的情况下,我们希望模型不会获取奖励或者根据调用次数获得的奖励相对较小,从而最大程度的规避奖励黑客现象 (i.e., Reward Hacking)。具体来说,我们设计了如下的奖励函数: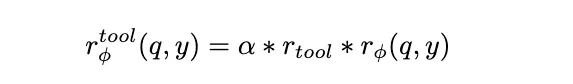 其中r_tool代表对于工具调用次数的奖励,r_\phi (q, y)代表原来的根据答案的正确性的奖励。这样的奖励函数有很多优点:1)已经有理论证明类似这样的定义理论上对于准确性没有任何损失;2)极大地避免奖励黑客的现象,防止模型过度优化;3)可以泛化到几乎所有的Agentic RL的场景,比如对r_tool 和 r_\phi 进行扩充,考虑更多的奖励信号。这里r_tool的设计只需要满足之前说过的那些属性即可,比如越少越好,或者越接近最优工具调用越好,感兴趣的可以参考原文,这里我们重点讲讲我们的一些发现。
其中r_tool代表对于工具调用次数的奖励,r_\phi (q, y)代表原来的根据答案的正确性的奖励。这样的奖励函数有很多优点:1)已经有理论证明类似这样的定义理论上对于准确性没有任何损失;2)极大地避免奖励黑客的现象,防止模型过度优化;3)可以泛化到几乎所有的Agentic RL的场景,比如对r_tool 和 r_\phi 进行扩充,考虑更多的奖励信号。这里r_tool的设计只需要满足之前说过的那些属性即可,比如越少越好,或者越接近最优工具调用越好,感兴趣的可以参考原文,这里我们重点讲讲我们的一些发现。
Main Results
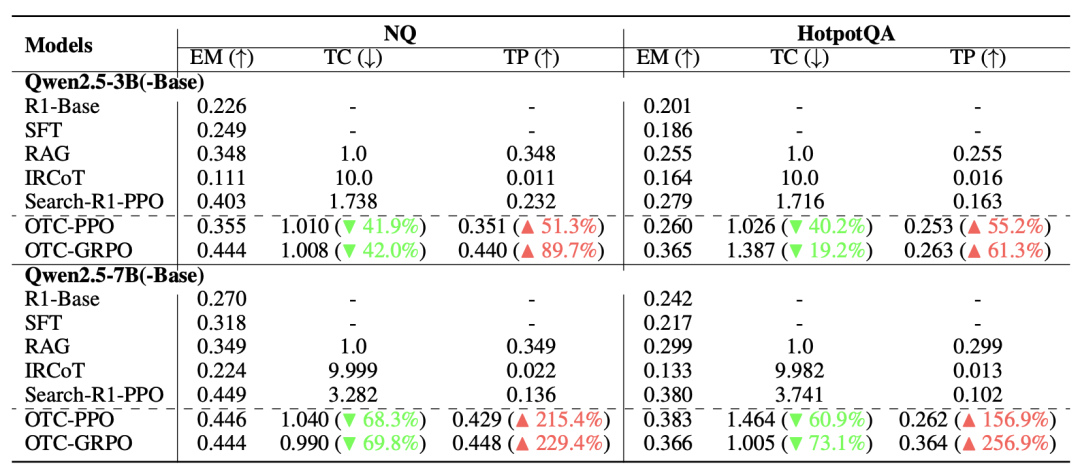
模型越大,其认识卸载越严重。这里的认知卸载指的是模型倾向于把原来通过推理能得到的结果直接外包给外部工具,从而一方面造成工具滥用,一方面阻碍了模型自身推理能力的发展。从图上看就是Search-R1在更大的模型上反而需要使用到更多的工具,工具生产力更低。模型越大,我们的方法效果越好。我们在7B模型能够取得最高256.9%的工具生产力的提升,并且我们的准确率基本没有损失,我们相信当模型大小继续增大的时候,有可能我们能迎来效果与效率的双重提升,具体原因我们稍后解释。此外我们发现GRPO相较于PPO效果更好,这是因为GRPO由于天然具备针对同一样本的多次采样,对于该样本的最优工具调用行为有一个更加精准的估计。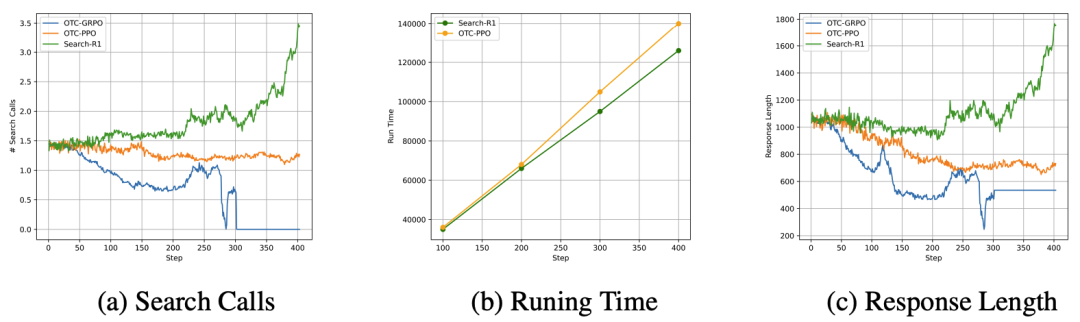
上图展现了我们的训练效率分析。可以看出我们的方法不仅能够以更少的工具调用和更短的响应时间实现类似的结果,还能实现更快、更高效的训练优化。这一点尤为重要,因为它显著降低了训练过程中与实时工具交互相关的时间和成本,包括时间,计算资源以及可能潜在的工具调用费用。

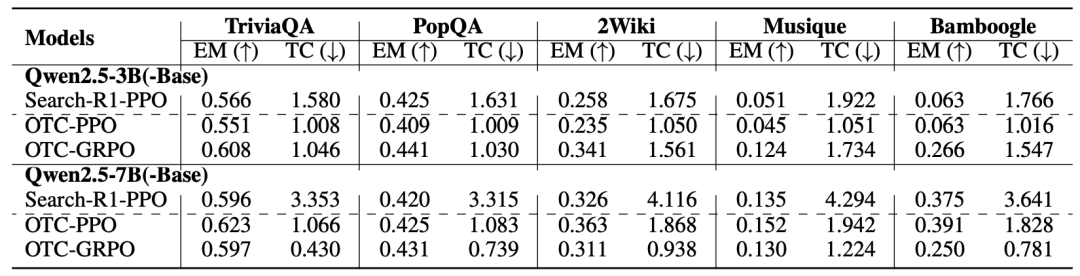
我们的方法不仅仅在In-domain evaluation上取得了不错的效果,在Out-of-domain上仍然能够带来巨大的提升,甚至我们观察到我们的准确率和效率都得到了提升,而不仅仅是工具的调用次数和工具生产力,比如这里OTC-PPO在7B模型上的表现就显著优于Search-R1-PPO。 最后分享一个case study,更多分析和case可参考原文。这个case study代表了我们整篇论文最重要的一个发现即 (Minimizing Acting = Maximizing Reasoning) = Smart Agent 从案例中我们可以观察到如果不对模型的交互行为做出任何的限制,模型非常容易出现认知卸载以及工具滥用的现象。仅仅只需要最小化工具调用,我们就可以发现模型不仅能学会更加聪明的使用工具(OTC-PPO),还会极大地激发自身的推理能力,从而去完成问题,即我们一开始所说的如何实现o3的行为模式。
最后分享一个case study,更多分析和case可参考原文。这个case study代表了我们整篇论文最重要的一个发现即 (Minimizing Acting = Maximizing Reasoning) = Smart Agent 从案例中我们可以观察到如果不对模型的交互行为做出任何的限制,模型非常容易出现认知卸载以及工具滥用的现象。仅仅只需要最小化工具调用,我们就可以发现模型不仅能学会更加聪明的使用工具(OTC-PPO),还会极大地激发自身的推理能力,从而去完成问题,即我们一开始所说的如何实现o3的行为模式。
结论
在本研究中,我们引入了最佳工具调用控制策略优化 (OTC-PO),这是一个简单而有效的强化学习框架,它明确鼓励语言模型通过最佳工具调用生成正确答案。与之前主要关注最终答案正确性的研究不同,我们的方法结合了工具集成奖励,该奖励同时考虑了工具使用的有效性和效率,从而促进了既智能又经济高效的工具使用行为。据我们所知,这是第一篇从强化学习 (RL) 角度去建模 TIR 中工具使用行为的研究,我们的方法提供了一种简单,可泛化,可扩展的解决方案,使 LLM 在多种情境和基准测试中成为更强大、更经济的智能体。这个项目仍在进行中,希望不久的未来我们能够给大家分享更多发现。我们有信心这篇论文将会引领一个全新的研究范式,为实现OpenAI的o3系列模型带来一个可行的路径。
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦

















 4116
4116

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









