






每天给你送来NLP技术干货!
来自:复旦DISC
作者:陈伟

引言

对话系统是自然语言处理领域的核心任务之一。对话系统的最新进展绝大多数是由深度学习技术所贡献的,这些技术已经被用来强化各类大数据应用,如计算机视觉,自然语言处理和推荐系统。本次分享我们将介绍三篇ACL论文,分别介绍了从有限的个性化数据训练基于角色的对话模型、开放域对话的主题转移、用于对话中情绪识别的上下文推理网络。

文章概览

BoB: BERT Over BERT for Training Persona-based Dialogue Models from Limited Personalized Data
论文地址:https://arxiv.org/abs/2106.06169
带标注的人设密集数据的规模有限仍然是训练强大且一致的基于人设的对话模型的障碍。在这项工作中,作者使用BERTover-BERT (BoB) 模型将基于人设的对话生成分解为两个子任务。具体来说,该模型由一个基于 BERT的编码器和两个基于 BERT的解码器组成,其中一个解码器用于响应生成,另一个用于人设一致性理解。同时,作者通过优化unlikelihood利用大规模非对话推理数据中学习人设一致性理解。自动和人工评估都表明,所提出的模型在响应质量和角色一致性方面优于强大的基线。
OTTers: One-turn Topic Transitions for Open-Domain Dialogue
论文地址:https://arxiv.org/abs/2105.13710
开放域对话中的混合主动性需要一个系统来主动引入新主题。单轮主题转换任务探索系统如何以合作和连贯的方式连接两个主题。该任务的目标是生成一个“桥接”话语,将新话题与上一个对话轮的话题联系起来。作者收集一个新的单轮主题转换对话数据集OTTers。然后,作者探索了人类在被要求完成此类任务时使用的不同策略,并注意到使用桥接话语来连接两个主题是最常用的方法。最后作者展示了现有的最先进的文本生成模型如何适应此任务,并检查这些基线在 OTTers 数据的不同拆分上的性能。
DialogueCRN: Contextual Reasoning Networks for Emotion Recognition in Conversations
论文地址:https://arxiv.org/abs/2106.01978
对话中的情绪识别在开发移情机器方面受到越来越多的关注。最近,许多方法致力于通过深度学习模型感知对话上下文。然而,由于缺乏提取和整合情感线索的能力,这些方法在理解上下文方面是不够的。在这项工作中,作者提出了上下文推理网络DialogueCRN,以从认知角度全面理解会话上下文。受情绪认知理论的启发,作者设计了多轮推理模块来提取和整合情绪线索。推理模块迭代执行直观的检索过程和有意识的推理过程,模仿人类独特的认知思维。在三个公共基准数据集上的大量实验证明了所提出模型的有效性和优越性。

论文细节

1

动机
对话中的人设(Persona)代表某个说话者的身份元素的组合,例如个人资料和背景个人事实。在对话生成中,传统模型难以保证生成的回复符合预设的人设。如下图所示。

同时,现有的社交媒体对话中人设信息较少,如推特上不到10%的消息会透露个人轶事或在家或工作中的活动,甚至更少的个人身份信息。因此在有限的个性化数据上训练的模型无法充分理解人设的一致性。
模型
为了解决这一问题,作者提出了BERTover-BERT (BoB) 模型。该模型由一个编码器和两个解码器构成。
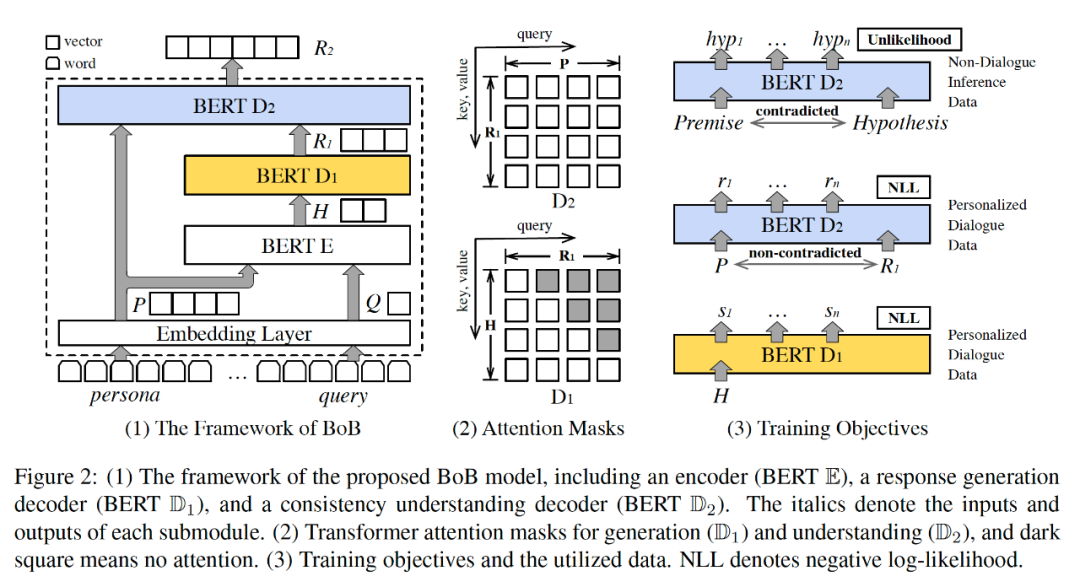
其中编码器是一个标准的 BERT 模型;解码器 D1 是响应生成解码器,由 BERT 和随机初始化的编码器-解码器注意力层构成;解码器 D2 是一致性理解解码器,也是一个标准的 BERT 模型。
训练

Bob主要包含两类训练数据,一类是带人设的对话数据 (P,Q,R),分别代表人设 Persona、上下文查询 Query、响应 Response;另一类是非对话推理数据 (D+, D-),其中D由前提和假设构成,D+代表正样本(即“假设”是符合“前提”的),而D-代表负样本。
训练时,E和D1组成了一个标准的 Transformer 模型,使用正常的带人设的对话数据可以计算得到负对数似然L1;D2则在D1的基础上,使用了两次 self-attention,第一次得到自身和人设 P(不包含Q)的注意力表示,然后再得到自身和D1的隐藏层输出的注意力表示,那么带有人设和D1输出的特征作为D2的输出层表示。
值得注意的是,D2使用了正负样本进行训练,其中正样本可以类似D1计算负对数似然,负样本则计算得到 unlikelihood,用于惩罚D2生成不符合人设P的响应。总体来说,D1是正常用于响应生成的解码器,D2则使用了unlikelihood优化,用于一致性理解,利用大规模推理数据,迫使 D2生成复合人设的响应。
数据集
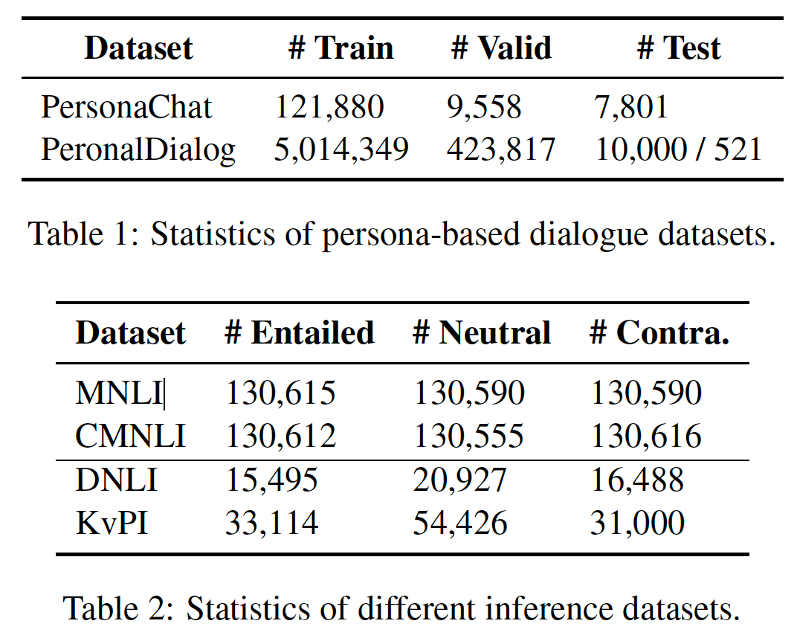
作者使用了多个数据集,其中带人设的对话数据集选择了 PersonaChat 和 PersonalDialog,非对话推理数据选择了 MNLI 和 CMNLI,用于评测的数据集选择了 DNLI 和 KvPI,下表是各个数据集的统计数据。
评价指标
作者提出了三类评价指标,第一类是自动评价指标,包含 Perplexity (PPL.) 和 Distinct 1/2 (Dist.1/2);第二类是基于模型的指标,包含Consistency Score (C.Score) 和 Delta Perplexity;最后一类是人工评价指标,包含四个维度,即 Fluency (Flue.)、informativeness (Info.)、relevance (Relv.) 和 consistency (Per.C.)。
结果
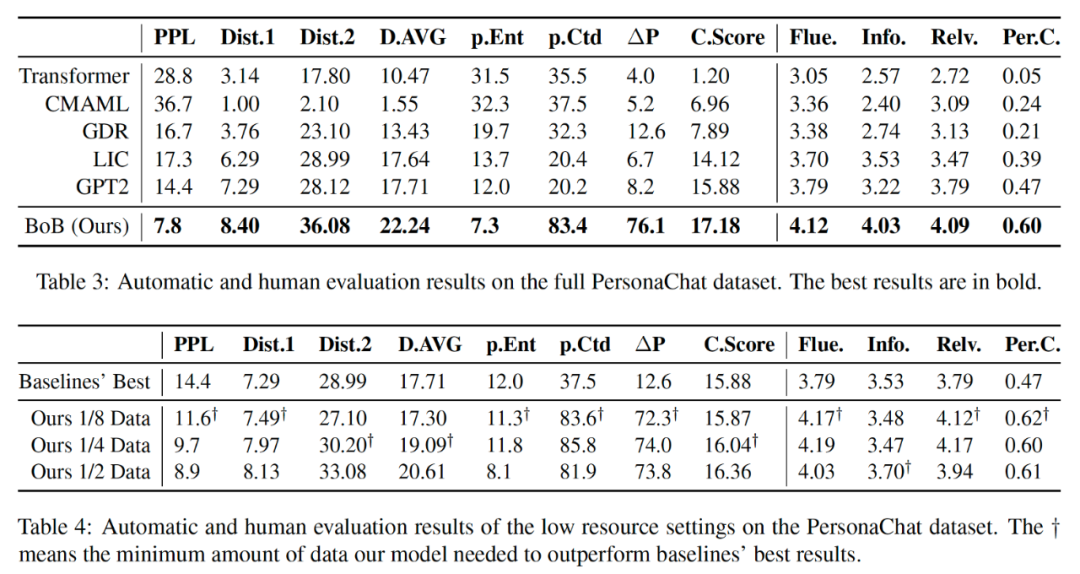
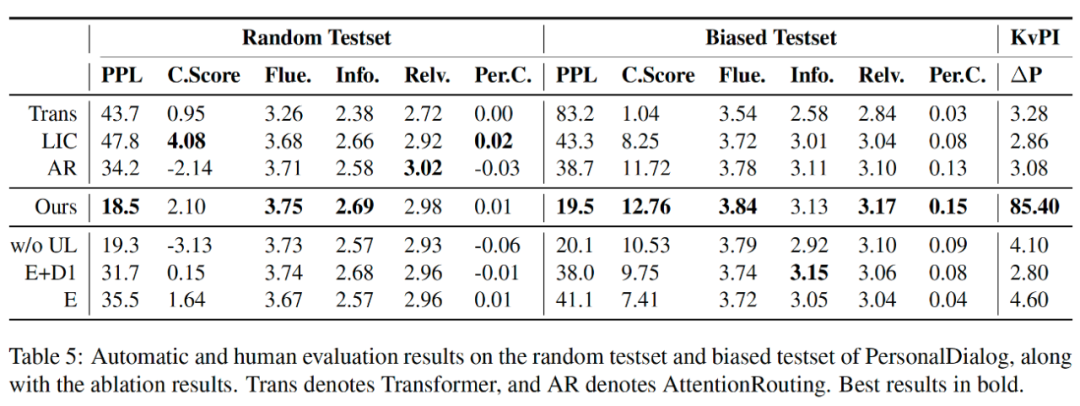
作者分别报告了在 PersonaChat 和 PersonalDialog 测试集上的评价指标,从表3中可以看出,BoB模型在所有的指标都显著优于基线模型。从表5中可以看出,BoB模型随机测试集中的一致性指标没有明显优于基线模型,但是另外制作的一个有偏测试集中的所有指标都明显优于基线模型。作者猜想这是因为 PersonalDialog 中的人设是比较稀疏的,所以人工挑选的有偏测试集特意筛选了部分带人设的子集。
从表4中可以看出,BoB模型在低资源的条件下仍然表现优秀,只需要八分之一的训练数据模型表现即可超过基线模型。表5中的消融分析可以看出,BoB的编码器和两个解码器都是有效的,减少其中的组件将降低模型性能。
分析
作者展示了BoB模型的一些案例分析,可以看出,BoB模型可以根据提供的人设特征,生成符合人设特征的响应。
2

动机
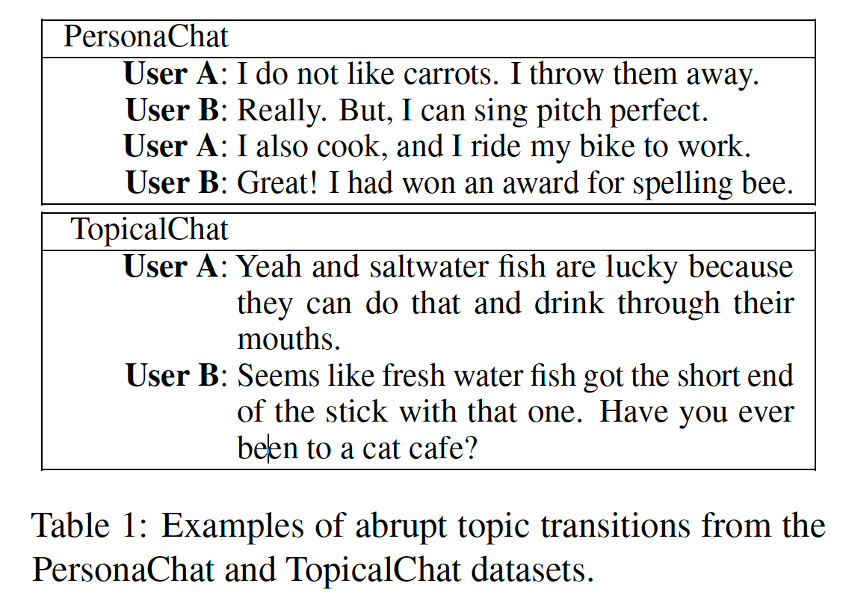
一个吸引人的有趣的对话需要双方都有积极性,比如引入新话题,这称为对话的混合互动性。现有的对话系统很难做到这一点,它们常常有以下的问题:1)纯响应式;2)突然的转折;3)不主动。下面是一些对话的例子。
贡献
本文提出了一种新的自然语言生成任务,该任务基于“桥接”策略,以知识库实体作为提示,生成开放域对话的单轮主题转换语句。
文本收集了一个众包数据集 OTTers,并在转换策略、语言属性、实体链接和知识库等方面进行了全面的分析。
普通 GPT-2 解码器相比,以知识库为基础的数据集可以有效地利用现有基于 Transformer 模型的推理组件,在域内和域外数据拆分中生成更好的输出。
任务定义
输入:话语 和 话语 。
输出:一轮过渡话语 。
目标: 和 的拼接是 的一个合适的响应,即 和 在讨论不同的主题, 的作用是用于从 过渡到 。
语料库构建
假设:作者认为,一个过渡的话语和知识库是有联系的。具体地,假设 中包含实体 , 中包含实体 ,那么一个合理的 应该包含某个实体 ,其中 在 和 在知识库的某条路径上。
知识库构建:作者以 PersonaChat 数据集中的 persona traits(人设话语)为起点。首先使用 Yahoo Entity Linker找出话语中所有的实体并链接到维基数据标识符(Wikidata identifier),然后使用SPARQL检索其超类和子类并添加到知识库作为顶点,最后从 ConceptNet 检索每个实体的常识连接。
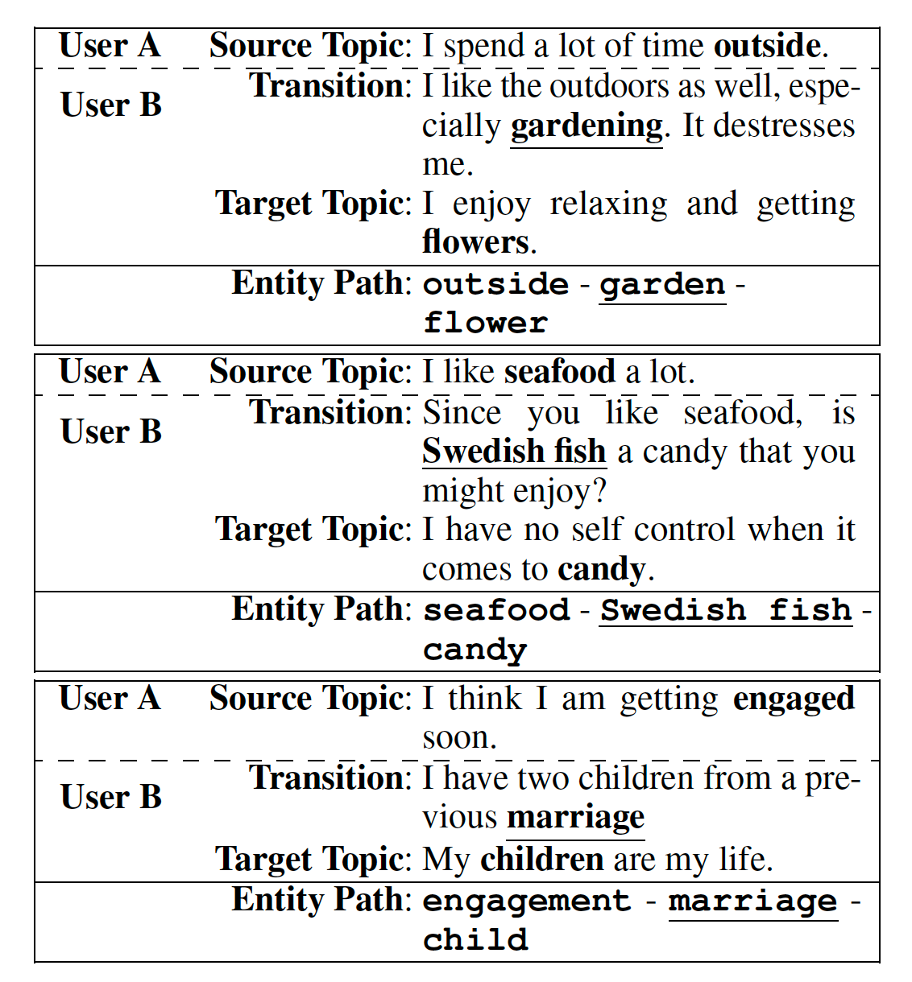
人工标注:作者首先从构建的知识库中,筛选出所有最短路径在1到20之间到实体对,这些实体对被保存下来,作为潜在的标注目标。对于给定的实体对,作者从PersonaChat找出实体对分别对应的句子,并要求标注者写出从一个实体句到另一个实体句的过渡语句。标注者还要求写出每个句子涉及的主题,一个标注的例子如下。
语料库分析
OTTers 包含 1,421 个独特主题对的 4,316 条话语,平均话语长度为 1.3 个句子和 16.4 个单词。作者还计算了给定 、 中提到的实体与众包注释话语中提到的实体之间的重叠。作者使用了实体集合的 Jaccard 距离作为度量,对于 OTTers 中近四分之一的话语对 、 和话语 ,这两个实体集合之间的 Jaccard 距离为 1,平均值为 0.842。这说明标注者过渡话题的过程中,会提到新的实体,遵循基于知识图的路径。
作者进一步针对标注者的主题转换策略进行了人工标注,作者将转化策略分为五类,分别是 bridging、acknowledge & continue、disjunctive、off-task、off-task。

经过统计,超过80%的标注着使用了转化策略。79%的标注者使用了 bridging 策略,5%使用了 acknowledge & continue 策略。这些分析表明了 OTTers 代表了基于知识库的主题转化语料库。
作者还研究了话语标记和KG distance的关系。KG distance指的是两句话中的实体在知识库中的最短距离,话语标记则般在句中起提示、停顿或过渡的作用。如"oh", "well", "now", "then", "you know", and "I mean"等。作者发现显性的话语标记和KG distance有一些微弱的相关性,即实体的联系越远,则主题转移语句中包含话语标记的可能性越大。
作者将 OTTers 和 PersonaChat 进行了对比,使用人工标注对转移语句进行打分,发现在 44/49 的案例中,OTTers 中的话语被判断为不那么突然,在一个案例中,可比较的 PersonaChat 话语被判断为不那么突然,而在另一个案例中,这两种话语都被评为“差”。这进一步说明了语料库的可用性。
实验
作者进一步进行了实验,其中 GPT2和 Multi-Gen 都是典型的文本生成模型,Multi-Gen 则包含了知识库的多跳推理模块。Split中,ood 代表测试集中的主题/实体在训练集中完全没出现过。hit@k 则表示模型预测的前k个相关实体是否包含在目标参考中识别出的实体。
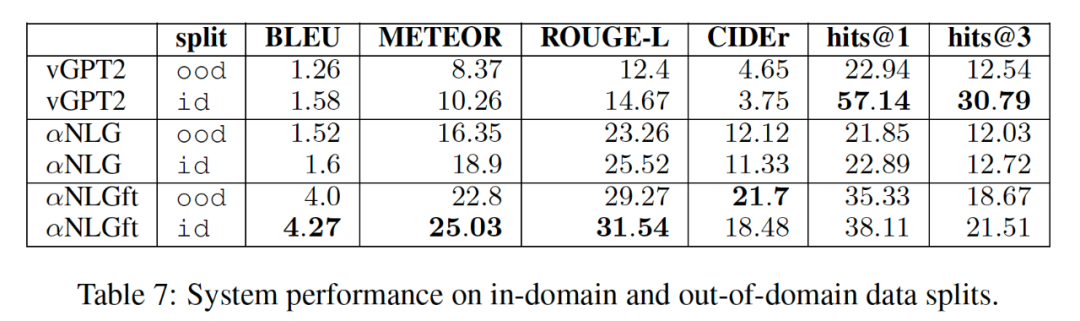
实验结果表明,在BLEU、METEOR等指标中,经过fine-tune的NLG模型表现最好,这说明基于知识库多跳推理模型在 OTTers 语料库上的有效性。
3

动机
对话中的情绪识别是开发有情感的对话系统的重要工具,也是其上游任务之一。现有对话情绪识别研究主要面临两个挑战:1)情感线索的提取。大多数方法通常从静态记忆中检索相关上下文,这限制了捕捉更丰富的情感线索的能力。2)情感线索的整合。许多研究使用注意力机制来整合编码的情感线索,而忽略了其内在的语义顺序。
任务
给定一段对话 ,其中N为对话轮数,假设共有 个说话者,对话情绪识别要求模型预测,每句话 的情感标签 。
模型
文本特征抽取:作者使用了 CNN 和最大池化层抽取了上下文无关的文本特征,输入是 300 维的 GloVe 向量。接下来,作者将模型分为三个组件,分别是感知阶段、认知阶段和情绪分类器。
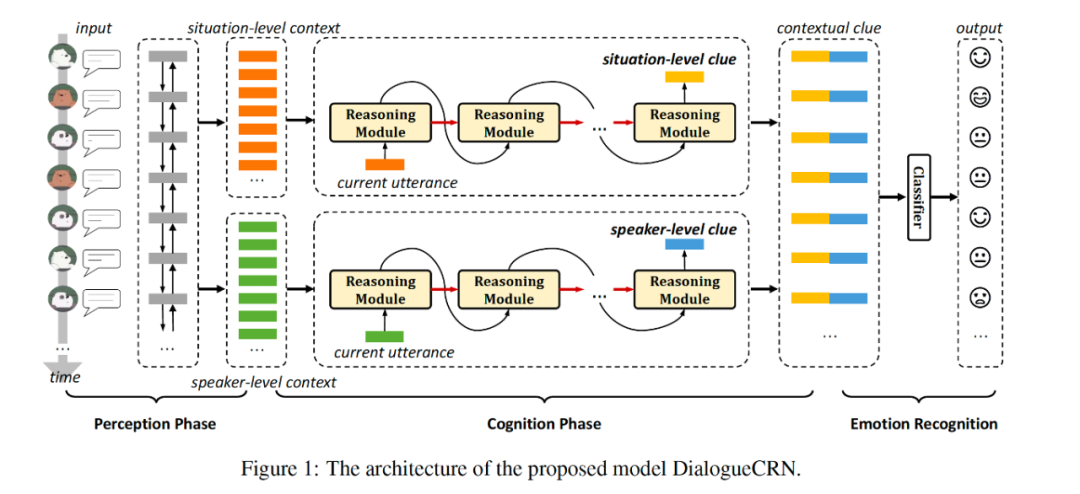
感知阶段
首先使用 LSTM 来建模相邻话语的序列相关性,其中 代表每句话的上下文无关的文本特征,其中 为 situation-level 的上下文相关的文本特征。
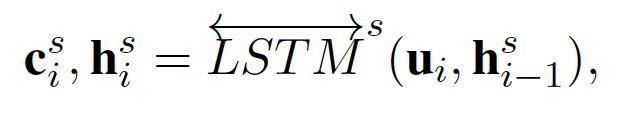
然后使用一个共享参数的 LSTM 来建模每个说话者的相邻话语的序列相关性,其中 为 speaker-level 的上下文相关的文本特征。
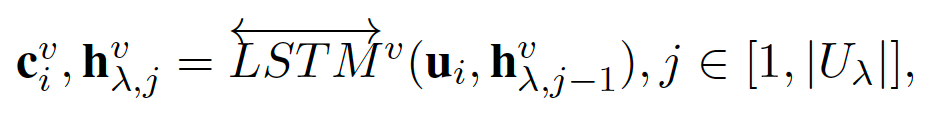
最后使用一个线性层分别将 situation-level 和 speaker-level 的文本特征存储为全局记忆表示(Global Memory Representation)。
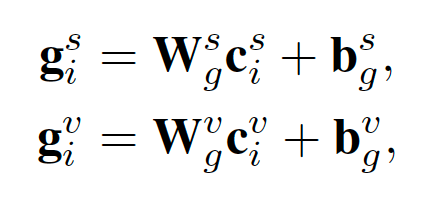
认知阶段
认知阶段分为推理过程和抽取过程,其中 为工作记忆(working memory)。
其中推理过程中,使用一个新的 LSTM,对上下文相关的文本特征 进行建模。
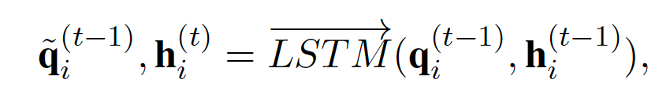
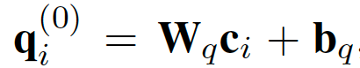
在抽取过程中,则使用注意力机制,从全局记忆表示中得到更新后的隐状态。

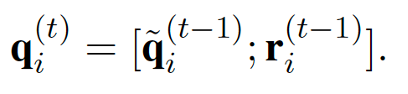
下图是认知阶段的流程,其中输入通过 过线性层进行初始化,工作记忆为LSTM中隐状态,隐状态的更新还依赖于从全局记忆中进行抽取。
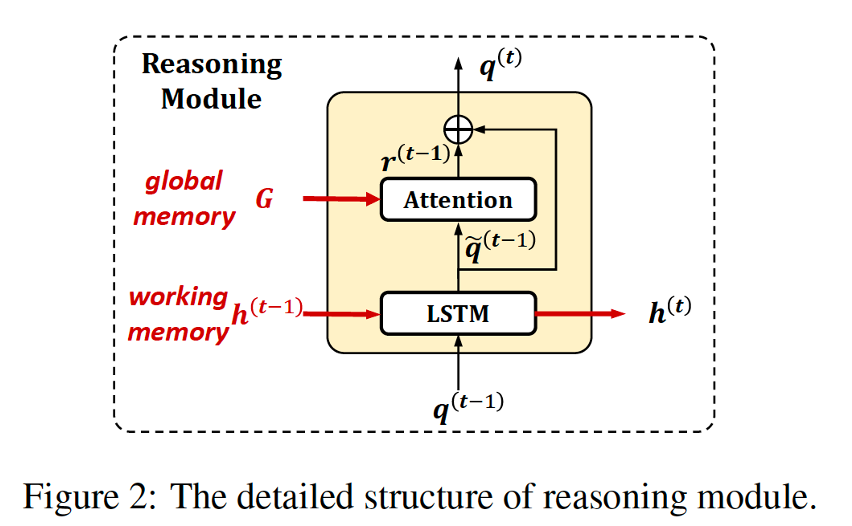
情感识别分类器
和 通过认知阶段得到的特征进行拼接,再通过 softmax 层即可计算出交叉墒损失函数,进行优化即可更新模型参数。

实验
实验设置
数据集:作者使用了 IEMOCAP、SEMAINE、MELD 三个经典的对话情绪识别数据集,其中 IEMOCAP 包含 happy, sad, neutral, angry, excited, frustrated 共 6 种情绪,SEMAINE 包含 Arousal, Expectancy, Power, Valence 共 4 种情绪,MELD 包含 happy/joy, anger, fear, disgust, sadness, surprise, neutral 共 7 种情绪。
评价指标:准确率、Weighted-average F1 、Macro-averaged F1。
实验结果
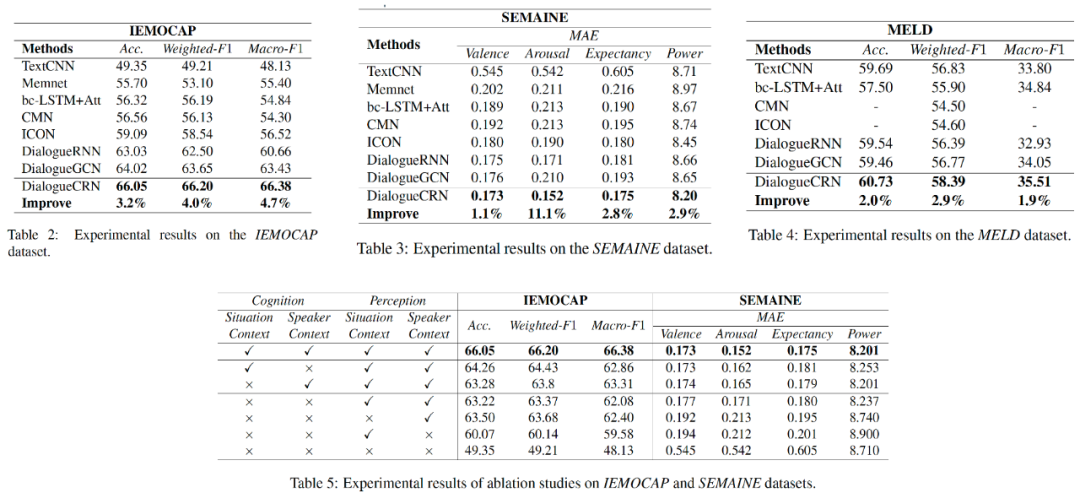
从表2、3、4中可以看出,DialogCRN 在三个数据集都表现出了最好的效果,相对SOTA模型有了较大的提升。同时,根据消融实验的结果(表5),从感知层和认知层上看,situation-level 和 speaker-level 的文本特征都是有效的,去掉任何一项,模型表现都有一定程度的降低。
投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注呦
整理不易,还望给个在看!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









