






每天给你送来NLP技术干货!
引言:我们正处于一个“多模多任务大统一”的AI时代。
 来自:高能AI
来自:高能AI
老铁们,上图是对动漫《海贼王》所选框的文字描述(Zero-shot测试),而这一“炫酷”的效果正式由达摩院最新发布的多模统一模型OFA搞定的~
曾几何时,建立一个能像人类一样同时处理多模态、多任务的通用模型一直是AI领域的1个“小目标”。
而最近阿里达摩院发布了模态、任务、结构统一的模型OFA,将多模态及单模态的理解和生成任务统一到1个简单的Seq2Seq生成式框架中,OFA执行预训练并使用任务指令进行微调,并且没有引入额外的任务特定层进行微调。
具体地说:
统一模态:统一图片、视频、文本的多模态输入形式;
统一结构:采取统一采用Seq2Seq生成式框架;
统一任务:对不同任务人工设计了8种任务指令;
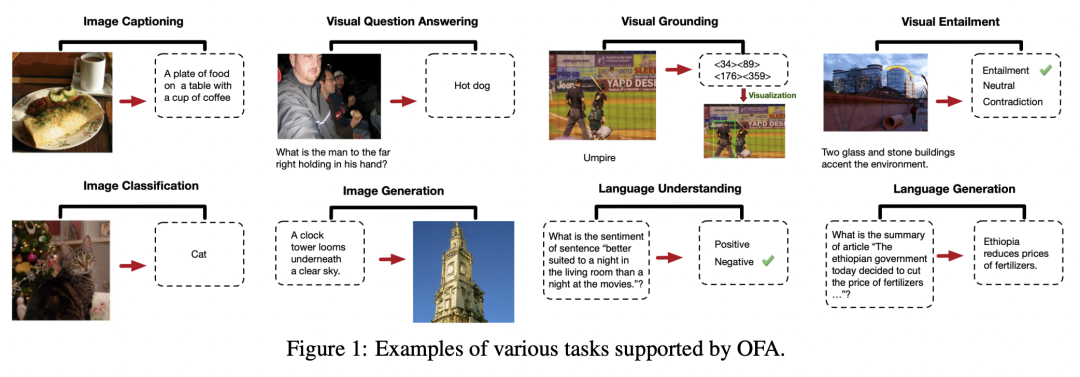
正如上图所说,OFA覆盖的下游任务横跨多模态生成、多模态理解、图片分类、自然语言理解、文本生成等多个场景,在图文描述、图像生成、视觉问答、图文推理、物体定位等多个风格各异的任务上取得SOTA。
论文题目:Unifying Architectures, Tasks, and Modalities Through a Simple Sequence-to-Sequence Learning Framework
论文地址:https://arxiv.org/pdf/2202.03052.pdf
开源地址:https://github.com/OFA-Sys/OFA
如何实现3个统一?
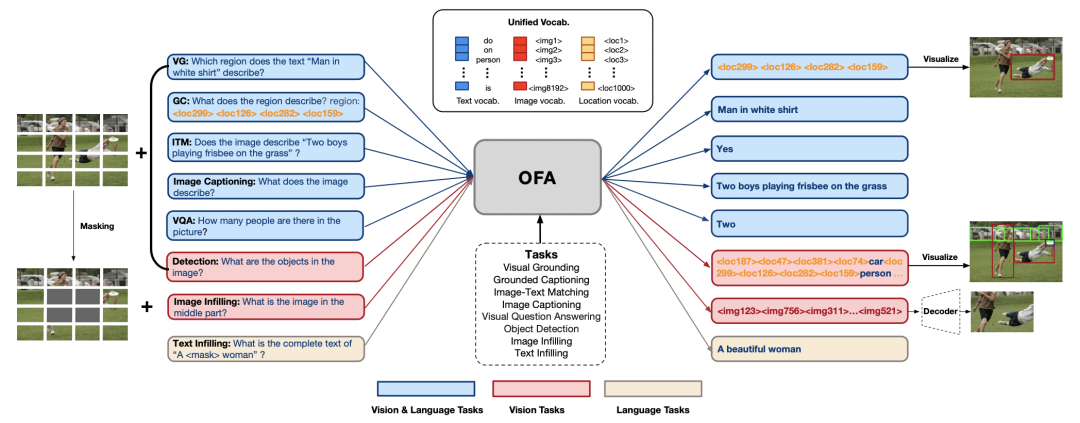
为了统一多模态输入,OFA将文本、图片以及其中的物体离散化到一个统一的词表中。具体做法是,将文本用BPE转化为subwords,将图片简单切分成多个patch并使用image quantization转化为image code,抽取图片中的物体的标签和bounding box并将bounding box离散化为location tokens <x1, y1, x2, y2>。最后,统一词表是文本的subwords,图片的image code和物体的location tokens三者的并集。
为了实现统一模型,OFA继续复用了在之前的大量工作中证明能有效地兼容不同的模态的Transformer结构。同时为了加快模型收敛,本文使用了post-normalization。
为了统一不同任务,OFA对不同任务人工设计了8种任务指令。其中,对多模任务设计了5种指令(如上图中蓝色矩形),对视觉任务设计了2种指令(如上图中红色矩形),对语言任务设计了1中指令(如图中黄色矩形)。以image grounding任务为例,模型输入为足球比赛图片和指令’Which region does the text ‘Man in white shirt’ describe’,希望模型能生成正确的白衣球员的正确位置信息。
主要实验结果
为了验证模型的有效性,论文分别进行了跨模态、单模态和zero-shot实验。
1、跨模态任务
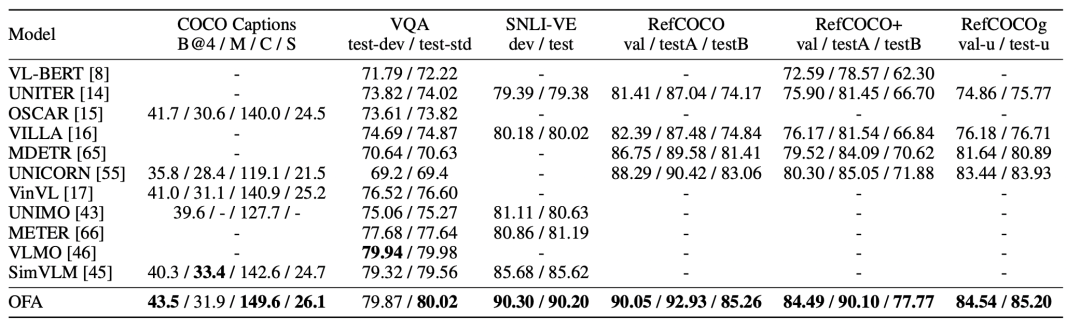
从实验结果中可以看到,OFA在image caption、VQA、visual entailment 和 referring expression comprehension 4个跨模态任务中都取得了SOTA。其中,OFA还超过了180亿参数的大模型SimVLM。
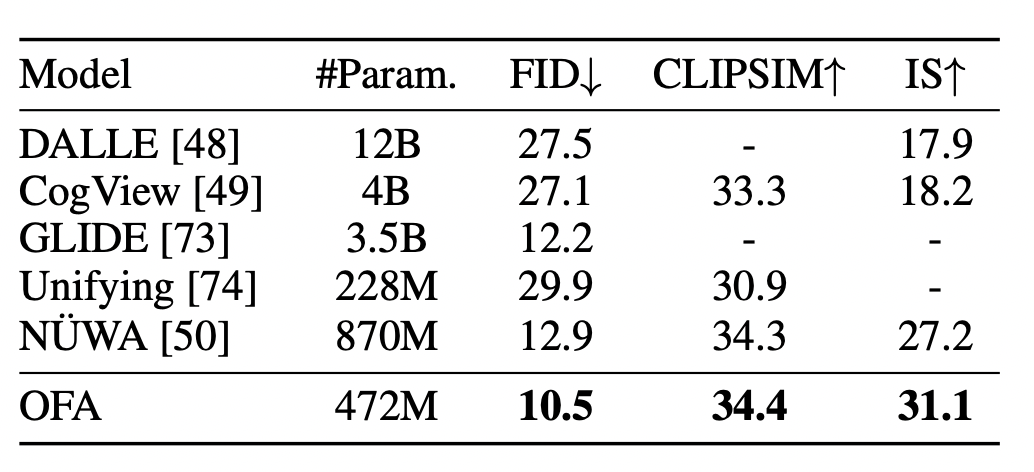
另外,在image-to-text generation任务中,OFA 也超过了DALLE, CogView和最近大火的NÜWA模型。
2、单模态任务
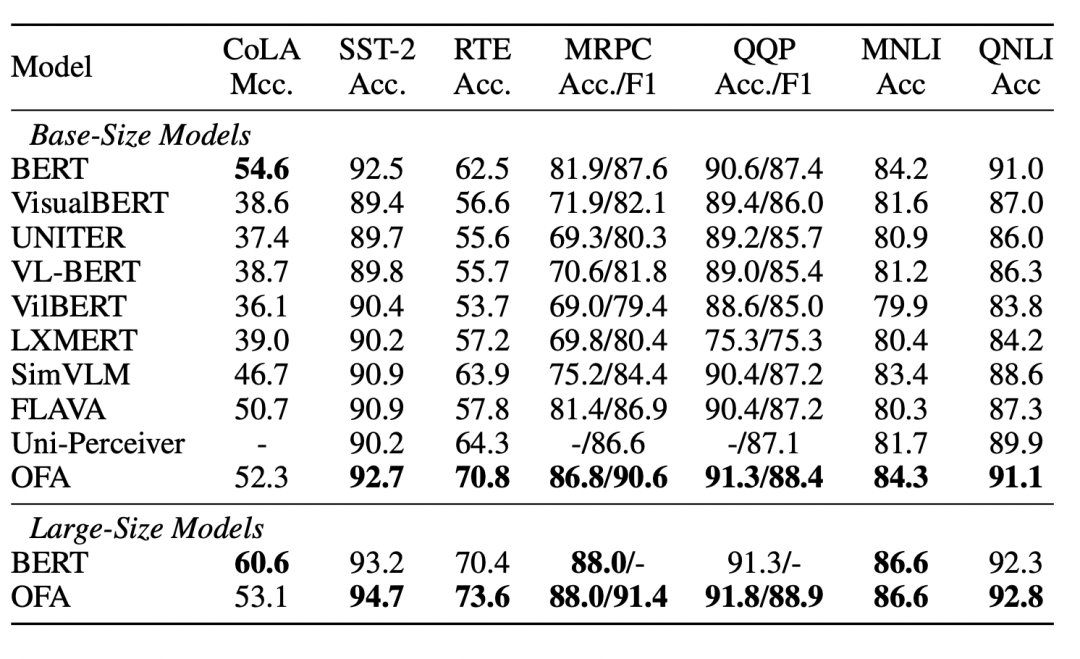
在文本任务上,如下表所示,OFA在文本理解数据集GLUE上大幅度超过了多模预训练模型SimVLM,并且和BERT的效果媲美,同时也在摘要生成数据集Gigaword上超过了大多数纯文本预训练模型。
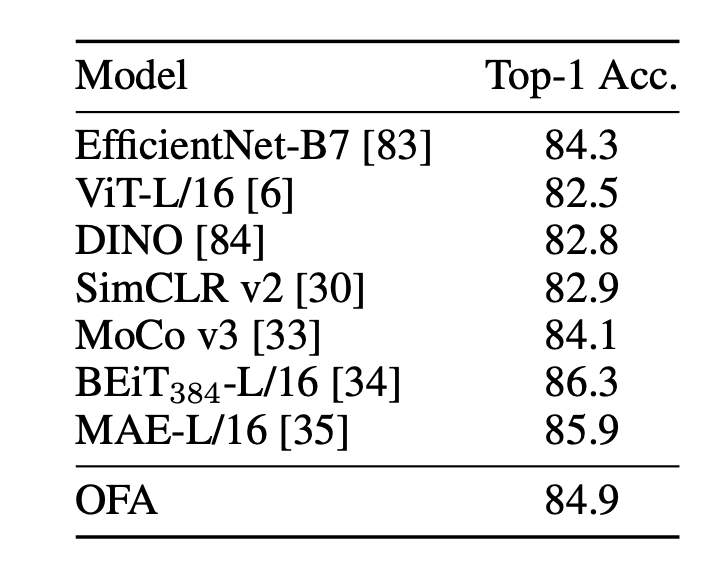
在图片分类任务上,OFA不仅超过了EfficientNet-B7等backbone模型,同时也超过了基于对比学习的SimCLR和MoCo,并且与基于masked image modeling训练的BEiT-L和MAE-L模型取得了相近的结果。
3、Zero-shot和任务迁移
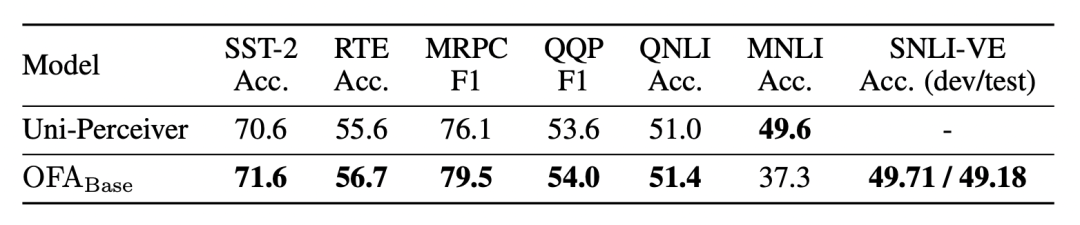
如上图,OFA在6个GLUE的单句和句子对分类任务上进行了zero-shot实验,效果超过了同期模型Uni-perciver,但是在句子对分类上的效果并不好,准确度低于60%。
为了验证OFA的zero-shot泛化能力,作者设计了一种grounded answering的新任务,如下图所示,对图片中的某一区域进行提问,模型也能给出满意的答案。

总结:
本文介绍的统一模型OFA是一个与任务无关、模态无关的综合性、大一统模型。
OFA实现了结构、任务和模态的统一,因此能够实现多模态和单模态理解和生成,无需在附加层或任务中指定。
OFA达到了图像字幕、文本到图像生成、VQA、SNLI-VE等方面的新SOTA。
OFA展示了与语言/视觉预训练模型在单模态理解中的可比性能。
OFA进一步分析了它在零样本学习下领域和任务转移方面的有效性。
最后,达摩院表示:正努力构建一个可推广到复杂现实世界的全能模型解决方案!
下载一:中文版!学习TensorFlow、PyTorch、机器学习、深度学习和数据结构五件套! 后台回复【五件套】
下载二:南大模式识别PPT 后台回复【南大模式识别】投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注呦
整理不易,还望给个在看!

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









